论文 | 基于CNN的目标检测算法

论文:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
近十年来,多目标检测的进展主要的是基于SIFT和HOG。但当在观察PASCAL VOC object detection的比赛结果时发现,比赛结果在2010-2012年之间进展缓慢。随着CNN(卷积神经网络)在ImageNet(图像识别比赛)上大获成功,本文作者考虑是否能将CNN在图像识别比赛中的结果应用到目标检测比赛 PASCAL VOC Challenge中呢? 本文提出了基于CNN的目标检测算法,这种算法对比之前提及的SIFT和HOG,在性能上有巨大的提高。
本文提出的目标检测算法主要集中在两个问题上:如何使用深度网络定位目标以及如何使用少量的标注数据构建高性能的检测模型。
IoU, Intersection over Union,模型产生的区域与原始区域的交叠率。
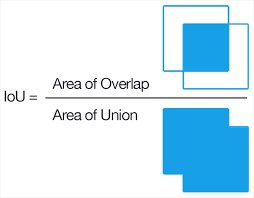
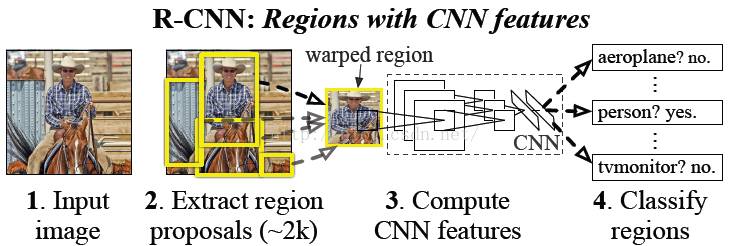
图1 R 结构
物体识别和目标检测的区别在于,物体识别仅仅需要指出这张图片属于哪一类,而目标检测在识别出物体属于哪一类的基础上,需要指出物体的区域。因此 R-CNN目标识别系统包含三个模块:
1. 候选区域生成模块。
使用Selective search算法,为每张图片生成2000个候选区域。
2. 特征提取模块
得到生成的候选区域后,如图1中的步骤2所示,候选框为矩形。而要使用CNN进行特征提取的话,要求输入为227*227的RGB图像。因此使用了最简单的图像变换算法即不考虑图片的长宽比例,直接进行缩放。缩放的结果为227*227的RGB图像。最后使用CNN(卷积神经网络)从变换后的图像中提取出4096维特征。卷积神经网络架构包括五层卷积,两层全联接层。
3. 测试方法
测试的时候,我们使用selective search在每张测试图片上生成2000个候选区域。对候选区域进行大小变换后,使用CNN提取出图片特征。然后,使用训练好的SVM对图片进行分类。分类的结果是针对图片属于每一类的打分情况。
4. 训练过程
4.1 有监督的预训练
有监督的预训练实质上是迁移学习。迁移学习就是把在之前解决的问题中得到的结论应用到另一个相关的问题中。例如在识别汽车中获得的知识可以被用来识别卡车的问题中。而在本文中,把 ILSVRC2012 clas- sification 比赛中使用的卷积神经网络的参数用来做本文中卷积神经网络的参数初始化。这样做的可行性在于,在ILSVRC2012 clas- sification 中使用的卷积神经网络的已经学习的关于物体分类的知识,在目标检测系统中同样适用。
4.2 调参
为了将上面的CNN应用在目标检测中,我们将之前的CNN中的最后一层,即1000种分类那一层。替换为N+1的分类层(N,目标的种类数,1代表背景)。而这层的参数使用随机初始化的方式。然后使用随机梯度下降法进行训练。随机梯度下降法的学习率为0.001, 是原来预训练的学习率的1/10。这样可以在不破坏初始化的状态下进行微调,以取得好的进展。在每次训练的时候,mini-batch 的大小为128,其中包括32个正样本,96个负样本。
4.3 目标种类分类器
对于检测车辆的二分类器来说,包含车的区域为正样本,像背景的区域是负样本。但是如何定义部分包含车的区域呢?作者使用了IoU阈值的各种方案,{0,0.1,…,0.5},对比发现0.3最好。即当重叠度大于0.3就标记为正样本,反之为负样本。一旦特征被提取出来,标签被标注好,我们使用这些数据来优化SVM(支持向量机)用来进行目标分类。
5. 模型修正
使用Bounding Box 回归的方法对模型生成的检测区域进行修正,从测试结果来看mAp提高了3到4个百分点。
6. 测试结果
最后在VOC 2010的数据集上,与DPM V5,UVA,Regionlets进行了对比,结果如下表所示,其中R-CNN BB在R-CNN的基础上使用了Bounding Box Regression:

原文链接:https://arxiv.org/abs/1311.2524
版权声明:转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。






