
【简介】近些年深度神经网络几乎在各个领域都取得了巨大的成功。然而,这些深度模型在尺寸上过于巨大,有几百万甚至上亿的参数,造成了巨大的计算开销,致使模型难以部署和落地。除此之外,模型的表现还高度依赖于大量的标注数据。为了使模型得到更加高效的训练和处理标记数据不足的难题,知识蒸馏(KD)被用来迁移从一个模型到另一个模型学习到的知识。这个过程也经常被描述为student-teacher(S-T)学习框架,并且已经被广泛应用到模型压缩和知识迁移中。这篇论文主要介绍了知识蒸馏和student-teacher学习模型。首先,我们对于KD是什么,它是如何工作的提供了一个解释和描述。然后,我们对近些年知识蒸馏方法的研究进展和典型用于视觉任务的S-T学习框架进行了一个全面的调研。最后,我们讨论了知识蒸馏和S-T模型未来的发展方向和研究前景,以及目前这些方法所面临的开放性挑战。
介绍
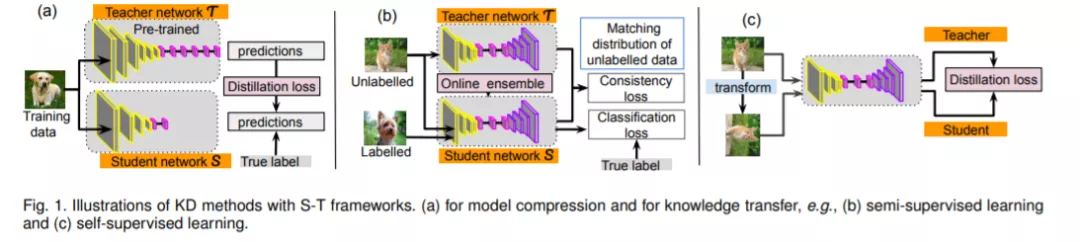
深度神经网络的成功主要依赖于精心设计的DNN架构。在大规模机器学习任务中,尤其是图像识别和语音识别任务,大多数基于DNN的模型都是凭借大量的参数来提取特征从而保证模型的泛化能力。这种笨重的模型通常都有非常深和非常宽的特点,需要花费大量的时间进行训练,而且不可能实时操作。所以,为了加速模型训练,许多研究人员尝试着利用预训练的复杂模型来获得轻量级的DNN模型,从而使得这些模型可以被部署应用。这是一篇关于知识蒸馏(KD)和student-teacher(S-T)学习模型的论文。一般来讲,知识蒸馏被视作一种机制:当只给出小型的训练集,其中包含相同或不同种类的样本的时候,这种机制能够使得人类快速学习新的,复杂的概念。在深度学习中,知识蒸馏是一个有效的方法,目前已经被广泛的应用在了从一个网络到另一个网络的信息转移上。知识蒸馏主要被应用在模型压缩和知识迁移这两个领域,对于模型压缩,一个较小的学生模型被训练来模仿一个预先训练好的较大的模型。尽管知识和任务种类多样,但是S-T框架是他们的一个相同点,其中提供知识的模型被称作teacher,学习知识的模型被称作student。我们对现有的知识蒸馏方法进行了重点分析和分类,其中还伴随着各种类型的S-T结构的模型压缩和知识转移。我们回顾和调查了这一迅速发展的领域,强调了该领域的最新进展。虽然知识蒸馏方法已经应用于视觉智能、语音识别、自然语言处理等各个领域,但本文主要关注的是视觉领域的知识蒸馏方法,所以论文中关于知识蒸馏的大多数阐释都是基于计算机视觉任务。由于知识蒸馏方法研究最多的领域是模型压缩,所以我们系统地讨论了该领域的技术细节、关键性挑战和发展潜力。同时,重点介绍了在半监督学习、自监督学习等领域的知识迁移方法,重点介绍了以S-T学习框架为基础的技术。
文章结构
section 2:探讨知识蒸馏和S-T学习框架为什么会吸引如此多的关注。 section 3:关于知识蒸馏的理论分析。 section 4-section14:对目前的方法进行分类,并且分析了面临的挑战以及该领域的发展前景。 section 15:根据上面的分类结果,我们回答了section 2中提出的问题。 section 16:介绍了知识蒸馏和S-T框架的潜力。 section 17:总结。