

**论文题目:**TrustUQA: A Trustful Framework for Unified Structured Data Question Answering **本文作者:**张文(浙江大学)、金龙(浙江大学)、朱渝珊(浙江大学)、陈矫彦(曼彻斯特大学)、黄志伟(浙江大学)、汪俊杰(浙江大学)、华尹(浙江大学)、梁磊(蚂蚁集团)、陈华钧(浙江大学) **发表会议:**AAAI 2025 **论文链接:**https://arxiv.org/abs/2406.18916 ****代码链接:https://github.com/zjukg/TrustUQA 欢迎转载,转载请注明出处

一、引言
结构化数据问答(TableQA、KGQA、TKGQA 等)在学术界与工业界备受关注。结构化知识问答方法如NL2Query针对特定数据类型将问题转化为对应查询函数,这限制了实际场景中的通用性。随着LLM和RAG方法的发展,一些更加通用的方法被提出,但依然存在如下问题:
-
检索到无关知识或LLM训练参数本身导致导致LLM幻觉
-
将结构化数据暴露到第三方LLM中,可能产生隐私数据泄漏
-
通过结构化数据很难提供高质量的问题解释
因此,我们提出 TrustUQA,统一结构化数据问答的可信框架,可以同时支持不同类型的结构化数据表示与问答,在提供可信的推理基础上最大程度避免数据泄露。
二、方法
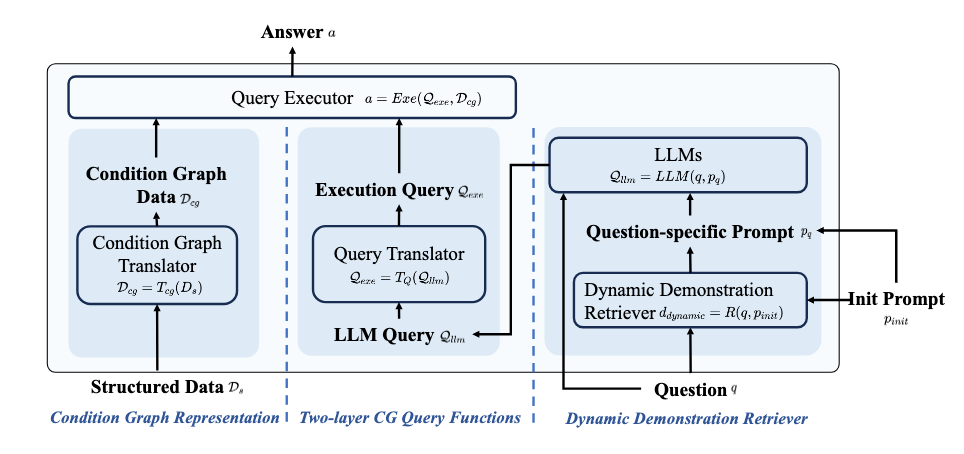
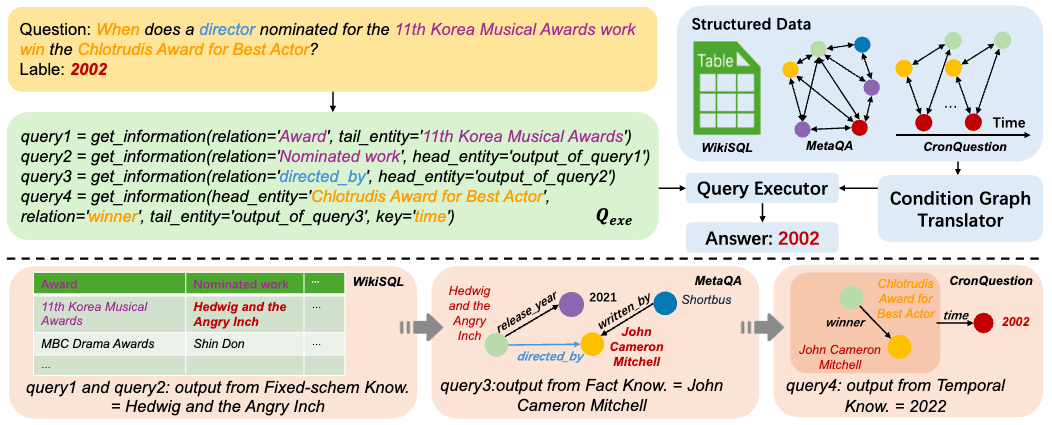
图1 TrustUQA流程图
TrustUQA的整体框架如图1所示,主要由三部分组成:
- 通过条件图(Condition Graph, 简称CG)实现结构化知识的统一表示。
- 提出两阶段查询函数实现结构化知识的统一推理与问答。
- 提出动态样例检索器进一步提升LLM生成查询函数的准确率。
条件图定义与结构化数据转换规则
条件图表示带标签的有向图 , 其中 为节点, 为条件三元组。条件图的定义如下:
- 对于节点: 有明确的语义信息, 如:实体(Earth)、关系(has friends)、属性(time)、数值(2024)
- 对于条件三元组:表示为 ,即和 由于 相连。同时如果condition可以为空表示和 相连无需额外条件。 将不同结构化数据转换为条件图对于表格,如图2所示,每行添加等于行顺序的序号,并为除了第一行以外的每个表格的值生成两个条件三元组,即.
图2 表格转换为条件图
- 对于知识图谱,如图3所示,知识图谱中的所有元素都为条件图中的节点,其中条件三元组为
 图2 表格转换为条件图
图2 表格转换为条件图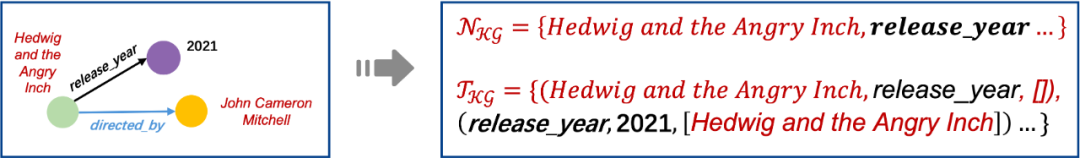
- 对于时序知识图谱,时序知识图谱中的所有元素都为条件图中的节点,除知识图谱部分转换之外,还将起始时间、终止时间、时间等信息转换为条件三元组, ,
两阶段查询函数
通过两阶段查询函数实现结构化知识推理与问答。首先通过LLM生成一阶段查询函数,后通过预定义的规则将一阶段查询函数转化为二阶段可执行函数,得到问题答案。在一阶段查询函数,我们设计如下搜索函数从条件图中搜索信息:除上述搜索函数之外,我们还设计了集合操作函数及数值计算函数。在二阶段查询函数,搜索函数将转化为以下可执行函数:
- :返回中的节点,默认情况下表示所有条件事实
- :返回满足要求的 ,即
- 查询比较函数,返回True或False

表1 两阶段查询函数转化规则两阶段查询函数转化规则如表1所示。
动态样例检索器
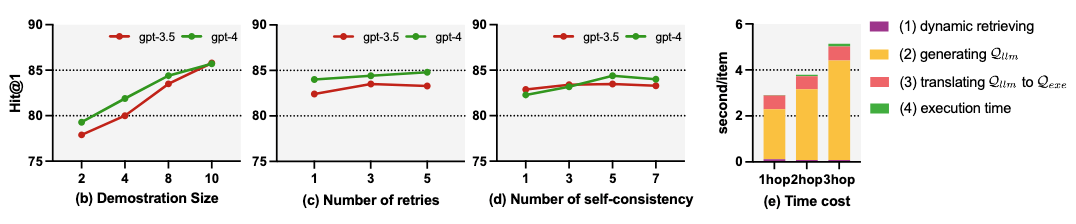
不同Few-shot样本对LLM的In-Context Learning影响明显,本文提出了动态演示检索器,从训练数据集中检索与问题的个最相似的问题。具体来说,给定一个问题,我们使用文本编码器将和训练问题编码为向量,通过计算问题向量的相似度,并选择个最相似的训练问题,其中。之后,对训练问题迭代生成一阶段查询,如果查询结果与标记的答案一致,则将检索到的问题与对应查询作为少样本样例,提升LLM生成查询函数的准确率。
三、实验结果
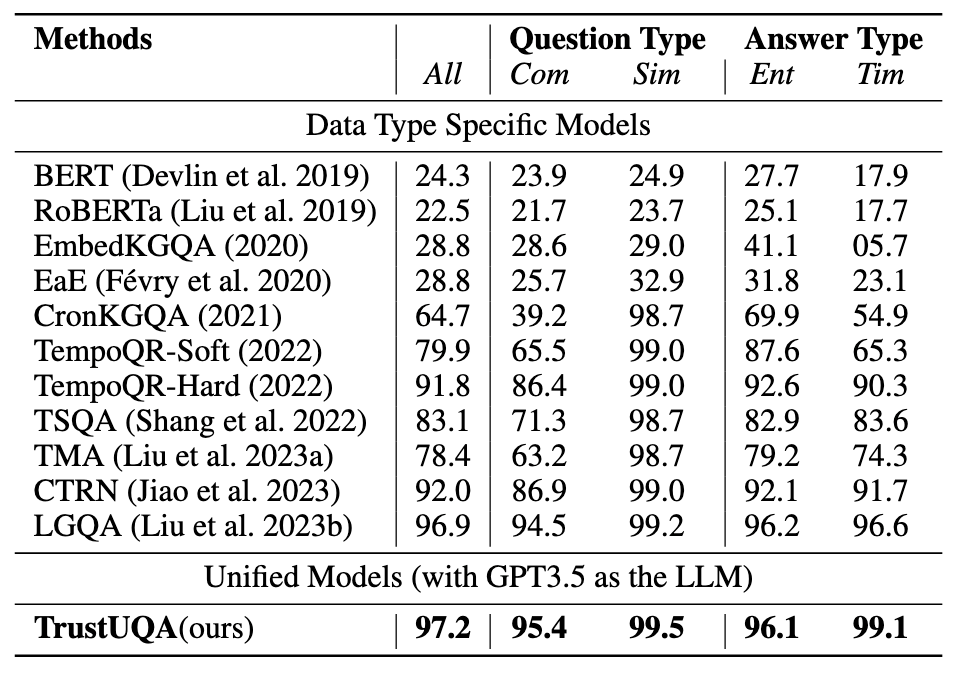
我们选用gpt-3.5-turbo-0613作为基础模型进行试验,并选择SentenceBERT作为检索器,在三种结构化数据问答任务:表格问答(WikiSQL,WTQ)、知识图谱问答(MetaQA,WebQSP),时序知识图谱问答(CronQuestion)中5个数据集上进行试验,实验结果如下:
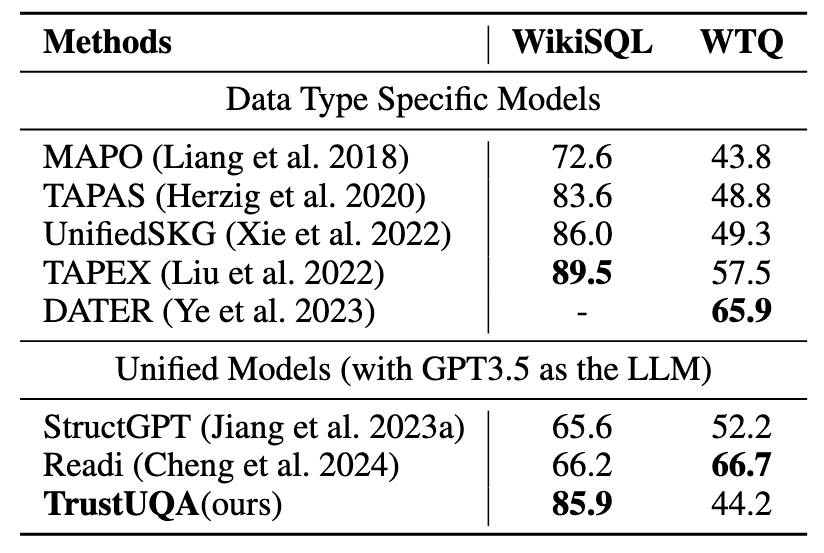
表2 表格问答实验结果表格问答实验结果如表2所示,TrustUQA在WikiSQL数据集中表现优于其他统一的问答方法,但在WTQ中仍有差距。 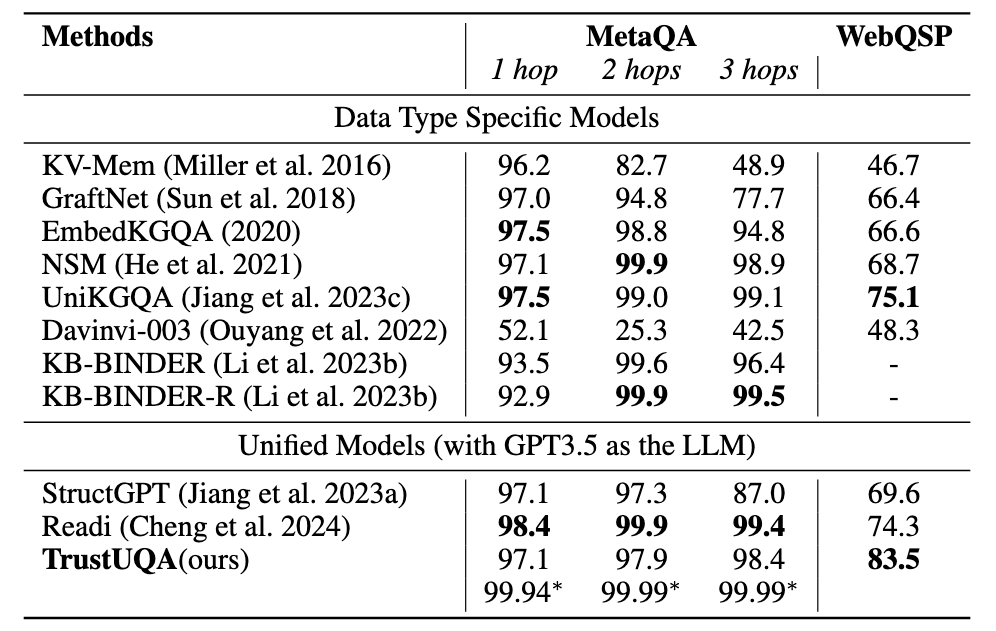

四、总结与展望
在本文中,我们提出了名为TrustUQA的统一的结构化数据问答的可信框架,其基于一种全新的、通用的数据表示方法——条件图及两阶段查询函数。通过实验证明了TrustUQA在不同类型的结构化数据上的有效性,并展示了处理更一般和更具挑战性的场景的潜力。在未来,我们将探索混合结构化数据问答和跨结构化数据问答等更具挑战性的场景,使得更接近实际应用。