
Using Prior Knowledge to Guide BERT's Attention in Semantic Textual Matching Tasks
Authors: Tingyu Xia, Yue Wang, Yuan Tian, Yi Chang
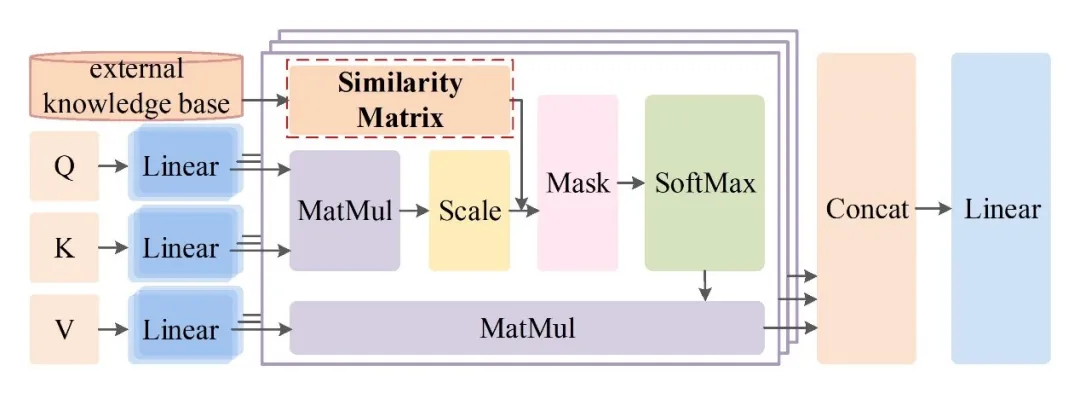
我们研究了将先验知识整合到基于深度Transformer的模型中的问题,即:,以增强其在语义文本匹配任务中的性能。通过探索和分析BERT在解决这个任务时已经知道的东西,我们可以更好地理解BERT最需要什么特定任务的知识,在哪里最需要什么知识。这一分析进一步促使我们采取一种不同于大多数现有工作的方法。我们没有使用先验知识来创建一个新的训练任务来微调BERT,而是直接将知识注入BERT特的多头注意机制。这将我们引向一种简单而有效的方法,它历经快速训练阶段,因为它节省了模型在主要任务以外的额外数据或任务上的训练。大量的实验表明,本文提出的知识增强的BERT模型能够持续地提高语义文本匹配性能,并且在训练数据稀缺的情况下性能效益最为显著。
https://www.zhuanzhi.ai/paper/7b48ad08e4eaf1a9d87baf6474bec12f
成为VIP会员查看完整内容
相关内容

Arxiv
10+阅读 · 2021年2月22日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
8+阅读 · 2017年11月22日

相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2021年2月22日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
8+阅读 · 2017年11月22日