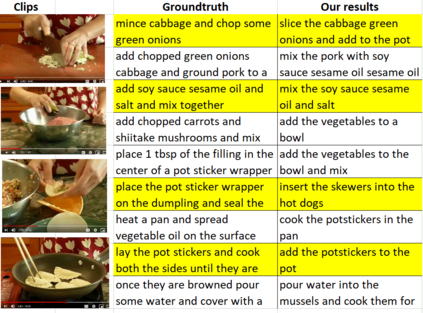
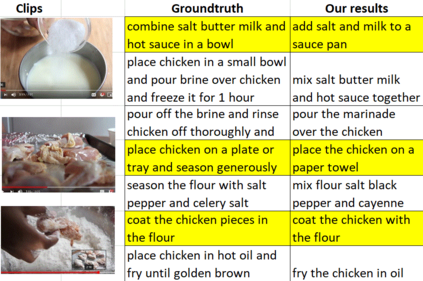
We propose UniViLM: a Unified Video and Language pre-training Model for multimodal understanding and generation. Motivated by the recent success of BERT based pre-training technique for NLP and image-language tasks, VideoBERT and CBT are proposed to exploit BERT model for video and language pre-training using narrated instructional videos. Different from their works which only pre-train understanding task, we propose a unified video-language pre-training model for both understanding and generation tasks. Our model comprises of 4 components including two single-modal encoders, a cross encoder and a decoder with the Transformer backbone. We first pre-train our model to learn the universal representation for both video and language on a large instructional video dataset. Then we fine-tune the model on two multimodal tasks including understanding task (text-based video retrieval) and generation task (multimodal video captioning). Our extensive experiments show that our method can improve the performance of both understanding and generation tasks and achieves the state-of-the art results.
翻译:我们建议UniVilM:一个用于多式联运理解和生成的统一视频和语言预培训模式。由于基于BERT的NLP和图像语言任务培训前技术最近取得成功,我们建议视频BERT和CBT利用视频和语言预培训模式,使用讲解教学视频进行视频和语言预培训。与他们的工作不同,我们建议一个统一的视频预培训模式,用于理解和生成任务。我们的模式由4个组成部分组成,包括两个单一模式编码器、一个交叉编码器和一个带有变换器主干线的解码器。我们首先对模型进行预先培训,以在大型教学视频数据集中学习视频和语言的普遍代表性。然后我们微调该模式的两种模式,包括理解任务(基于文字的视频检索)和生成任务(多模式视频字幕)。我们的广泛实验显示,我们的方法可以改进理解和生成任务的绩效,并实现艺术成果。