
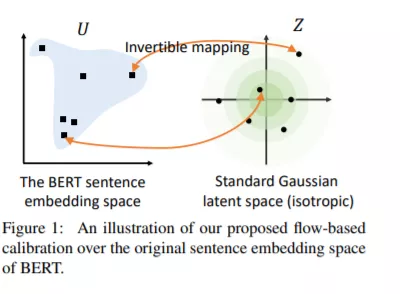
像BERT这样经过预训练的上下文表示在自然语言处理方面取得了巨大的成功。然而,未经微调的预训练语言模型中的句子嵌入发现句子的语义捕获效果较差。本文认为BERT嵌入中的语义信息没有得到充分利用。本文首先从理论上揭示了掩蔽语言模型训练前目标与语义相似度任务之间的理论联系,然后对BERT句子嵌入进行了实证分析。结果表明,BERT常常引入句子的非光滑各向异性语义空间,从而影响其语义相似度的表现。为了解决这个问题,我们提出将各向异性的句子嵌入分布转化为平滑的各向同性高斯分布,通过无监督目标学习的流进行归一化。实验结果表明,本文提出的基于BERT-flow的句子嵌入方法在各种语义文本相似度任务上都取得了显著的性能提升。该代码可在此https URL中获得。
https://arxiv.org/abs/2011.05864
成为VIP会员查看完整内容
相关内容

Arxiv
11+阅读 · 2019年10月30日
相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2019年10月30日