NAACL 2019 | 注意力模仿:通过关注上下文来更好地嵌入单词

作者 | 梁夏
编辑 | 唐里
下面要介绍的论文选自NAACL2019,
论文标题:Attentive Mimicking: Better Word Embeddings by Attending to Informative Contexts
论文地址:https://arxiv.org/abs/1904.01617
在稀疏上下文信息的情况下,很难得到较高质量的低频单词嵌入,“模仿”被认为是一种可行的解决方案:通过给定标准算法的词嵌入,首先训练模型出现频次高的单词的嵌入,然后再计算低频单词的词嵌入。在本文中,我们引入了注意模仿模型,该模型不仅仅能够可以体现单词的表面形式,同样还可以访问所有可用的上下文,并学会使用最有用和最可靠的上下文来计算词嵌入。在对四项任务评估中,我们发现对于低频和中频单词,注意力模仿比以前的工作更出色。因此,注意力模仿可以改进词汇中大部分包括中频词的嵌入。
1. 研究背景
词嵌入在自然语言处理(NLP)中取得了巨大的性能提升。然而,嵌入方法通常需要对单词进行多次观察才能为其学习到更好的表示形式。克服这种限制并改进低频单词的嵌入的一个方法是将表层信息纳入学习范围。这里可以采取一步或者两步的方法来解决,首先,在单词级别上训练嵌入模型,然后使用表层信息对词嵌入要么微调,要么重新计算。后者可以通过训练模型来实现,复制(或模仿)原始嵌入。然而,这些方法仅在单词的含义至少可部分根据其形式来预测时才有效。
一个密切相关的研究路上是新词嵌入,目标是从小部分单词观察中获取以前未出现过的单词嵌入。尽管大多数现代方法专门使用上下文信息用于此任务。最近介绍了形式-上下文模型,并表明从表面形式和上下文进行联合学习可带来更好的表现。
本文中讨论的关键在于,通常一个词的上下文中只有很少一部分能提供关于其含义的有价值的信息。然而,当前的技术水平将所有的上下文视为相同作用。我们通过引入一种更智能的机制来解决这个问题:我们不是使用所有的上下文,而是通过关注来选择一个信息更为丰富的上下文的子集进行学习。这个机制基于以下观察:在许多情况下,给定单词的可靠上下文往往彼此相似。我们将此结构称为注意力模仿(AM)。
我们的贡献如下:(i)介绍了注意力模仿模型。通过关注最有用的上下文,它可以为低频和中频单词生成高质量的嵌入。(ii)我们提出了一种基于VecMap的新式评估方法,使我们能够轻松评估低频和中频单词的嵌入质量。(iii)我们发现,注意力的模仿可以改善各种数据集上的单词嵌入性能。
2. 相关工作
训练表面形态模型以模拟词嵌入的方法包括基于词素和字符级别,在微调方面,可用通过引入一个高斯模型,该模型将词形态信息整合到单词嵌入中。使用一组特定语言的规则重新计算嵌入。直接将表面形态信息集成到嵌入学习中的模型包括fastText、LexVec和Charagram。虽然许多学习嵌入新词的方法利用上下文信息的同时也使用了注意力机制。但他们的注意力是在上下文内(选择单词),而不是横跨上下文(选择上下文)。他们的注意力仅限于单词类型和单词之间的距离,而不是我们注意力模仿模型中可用的更复杂的因素,例如与单词表面形态信息的交互。
3. 注意力模仿
3.1 上下文模型
在上下文模型(FAM)中需要一个维度为d的嵌入空间,将高质量的嵌入向量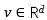
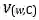
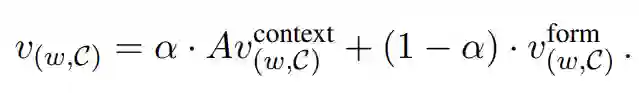
其中加权系数α是两个嵌入的系数,其模型为:
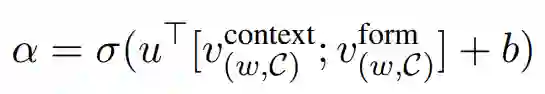
其中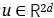
3.2 上下文注意力机制
FCM同样关注一个词的所有上下文,但通常只有很少的上下文实际上适合推断某个单词的含义。引入注意力模仿(AM)来解决这个问题:我们允许模型根据上下文的"可靠性"的度量来为上下文分配不同的权重。为此令C = {C1,...,Cm},其中每个Ci是单词组。我们将FCM的上下文嵌入替换为加权嵌入
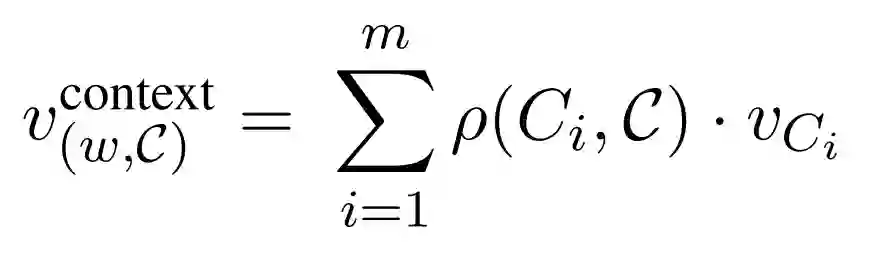
其中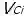
我们考虑一个词w,其中w的十分之六的上下文中包含涉及体育的单词,由于这种高度相关的上下文,因此可以合理地假设与w来自同一域,同时,与体育无关的剩下的十分之四的上下文信息较少。我们将两个上下文的相似性定义为:
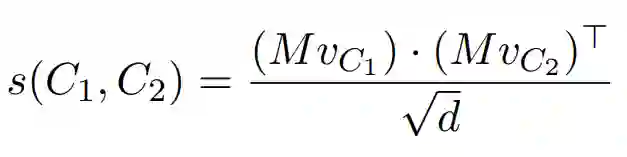
其中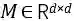
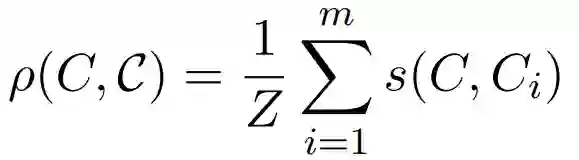
其中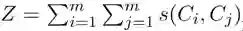
4.实验
在我们的实验中,我们遵循维基百科语料库(WWC)的设置并使用它来训练所有的嵌入模型。为了获取FCM和AM的训练实例(w,c),我们根据WWC的频率对单词和上下文进行采样,仅使用至少出现100次的单词。我们使用Gensim中的skipgram嵌入训练FCM和AM。
我们的实验设置在两个方面与Schickand Schutze (2019)不同
(1)我们没有使用固定数量的上下文表示C,而是随机采样1到64个上下文
(2)我们将训练轮数固定为5轮
对于第一个不同,我们希望模型在少数可用上下文以及在大量可用上下文两种情况下都能够生成高质量的嵌入,对于第二个固定轮数仅仅是因为我们的评估函数没有针对训练轮数进行优化。
为了更好的评估模型,我们应用了一种新的内在评估方法,该方法通过将嵌入空间转换为公共空间来对其进行比较(第4.1节)。我们还将在三个单词级下游任务(第4.2节,第4.3节,第4.4节)中测试模型,以证明其通用性。
4.1 Vecmap
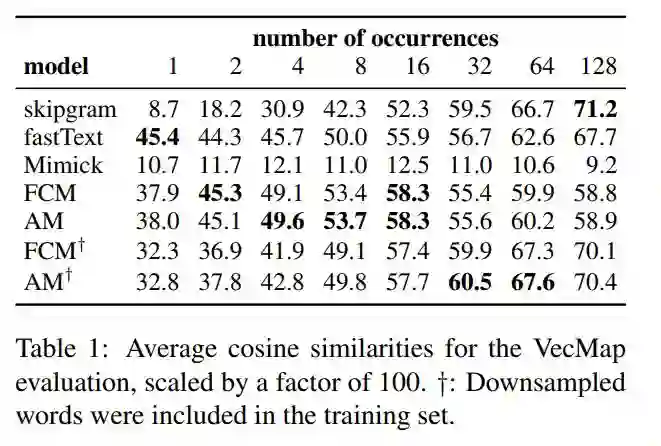
我们介绍了一种新颖的评估方法,该方法通过将WWC中的常用词降采样为固定的出现次数来显式评估低频和中频词的嵌入。然后,我们将从原始语料库获得的skipgram嵌入与通过在降采样语料库上训练的某种模型学习的嵌入进行比较。使用VecMap将两个嵌入空间转换为一个公共空间, 我们提供除降采样词外的所有词作为映射字典。从直觉上讲,模型从少量观察值推断嵌入的效果越好,其嵌入与该公共空间中的嵌入的相似性就越高。因此,我们通过计算模型嵌入和skipgram嵌入之间的平均余弦相似度来衡量模型的质量。作为基线, 我们在缩小样本的语料库上训练skipgram和fastText。然后我们在skipgram上训练Mimick、FCM和AM。
我们还尝试了一种变体,将降采样后的单词放入训练集中,这样一来,该模型就可用完全从无到有地学习这些单词,而且还可以利用他们的原始嵌入。因此我们希望该变体仅在单词不太稀疏的情况下才有用,即其原始嵌入已经具有不错的性能。表1显示了对于频次低于32的单词,FCMand AM的表现比所有基线都要好得多,而主要关注语法信息的Mimick的表现则相对较差。在给定四个或者更多上下文的情况下。AM给FCM带来了的持续的提升。在训练过程中包括降采样单词的变体在32次或更多次观察中仍然表现出胜过skipgram,但对于不那么频繁的单词,其表现却比默认模型差。
4.2 情感词典
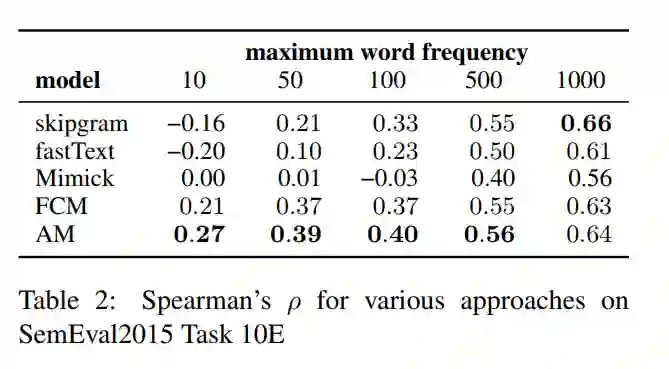
我们集成词汇词典和NRC情感词典,得到具有二元情感标签的单词训练集。在这些数据的基础上,训练了一个基于嵌入的logistic回归模型来对单词进行分类。在评估中,我们使用了SemEval2015Task 10E,其中0代表负面情感,1代表正面情感。并且使用斯皮尔曼相关系数来衡量相似度。
我们在skipgram 和fastText词嵌入中训练逻辑回归模型,并且使用模仿模型计算出的嵌入来替换skipgram嵌入。表2显示,对于低频和中频词,AM再次优于所有其他模型。
4.3 实体输入
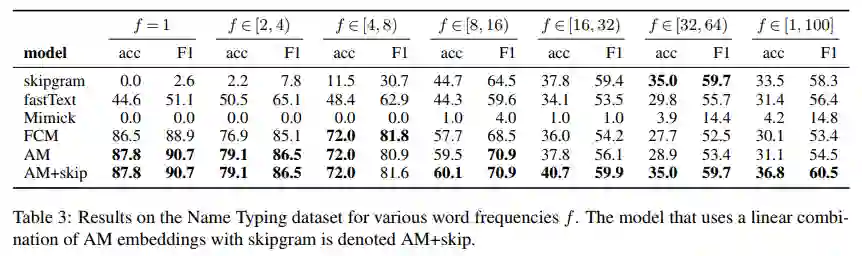
我们使用实体数据集,用于预测单词的细粒度命名实体类型,我们使用与第4.2节中相同的设置来训练逻辑回归模型,并对测试集中在WWC中出小于等于100次的所有单词进行评估。基于4.1节中的结果,AM仅改进了少于32次出现的单词的表示,我们还尝试了AM + skip的变体,在实验中用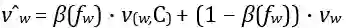
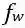
4.4 Chimeras 数据
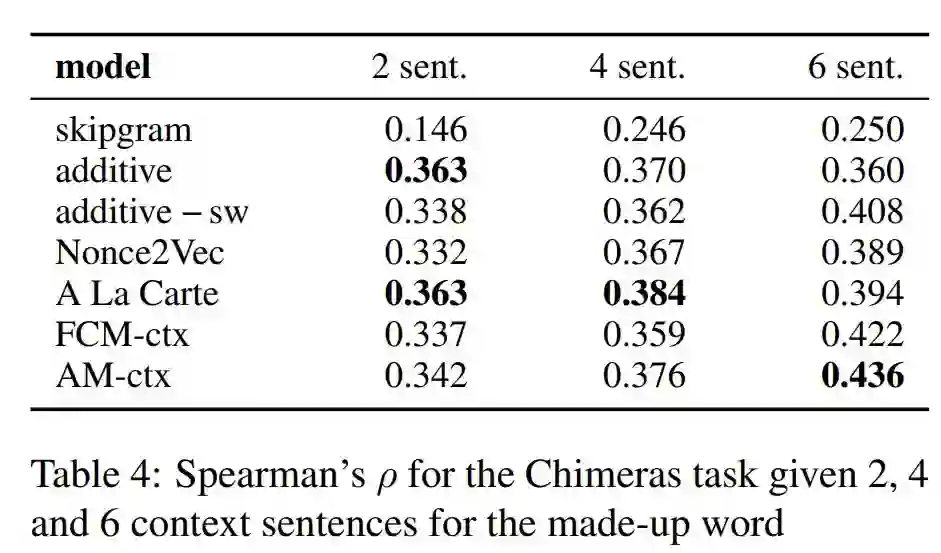
Chimeras(CHIMERA)数据集由成对单词和常规单词对的相似度得分组成。CHIMERA为每个虚构词仅提供六个上下文,因此对于评估我们的模型不是理想的。尽管如此,我们仍然可以使用它来分析FCM(无注意)和AM(有注意)的区别。由于虚构单词的表面形式是随机构建的,因此我们将自己局限于FCM和AM的上下文部分(称为FCM-ctx和AM-ctx)。使用Herbelot和Baroni(2017)的测试集,并使用FCM-ctx和AM-ctx将给定的相似度得分与相应单词嵌入的余弦相似度进行比较,以获取虚构单词的嵌入。表4给出了我们模型和各种基线的斯皮尔曼系数;我们没有添加Mimick的结果,因为它对新颖单词的结果完全基于其表面形式。虽然AM在2-4个句子中的表现比以前的方法差,但与目前发布的6个句子的最佳结果相比,它有了很大的提高。同时,上下文关注始终对于结果有所提高:无论上下文数量如何,AM-ctx的性能都优于FCM-ctx。
尽管在有许多可用上下文的情况下上下文注意的效果更加明显,但我们仍对CHIMERA的一个示例性实例进行定量分析,以更好地了解AM。我们考虑表5中出现的组成词“petfel”,是由“saxophone”和“harmonica”组合而来,该模型最多涉及句子(2)和(4),同样的,从那些句子获得的嵌入非常相似。此外,在所有四个句子中,这两个句子最适合于简单的平均模型,因为它们包含信息丰富的常用词,例如“instrument”,“chimes”和“music”。

5. 总结
我们介绍了注意力模仿机制,并得出注意内容丰富且可靠的上下文可以改善低频和中频单词的表示形式,从而适用于各种任务。在以后的工作中,研究单词层面的注意力机制是否可以进一步改善模型的性能。此外,该架构是否也有益于不同于英语的其他语言。




