随着深度学习的成功,基于图神经网络(GNN)的方法[8,12,30]已经证明了它们在分类节点标签方面的有效性。大多数GNN模型采用消息传递策略[7]:每个节点从其邻域聚合特征,然后将具有非线性激活的分层映射函数应用于聚合信息。这样,GNN可以在其模型中利用图结构和节点特征信息。
然而,这些神经模型的预测缺乏透明性,人们难以理解[36],而这对于与安全和道德相关的关键决策应用至关重要[5]。此外,图拓扑、节点特征和映射矩阵的耦合导致复杂的预测机制,无法充分利用数据中的先验知识。例如,已有研究表明,标签传播法采用上述同质性假设来表示的基于结构的先验,在图卷积网络(GCN)[12]中没有充分使用[15,31]。
作为证据,最近的研究提出通过添加正则化[31]或操纵图过滤器[15,25]将标签传播机制纳入GCN。他们的实验结果表明,通过强调这种基于结构的先验知识可以改善GCN。然而,这些方法具有三个主要缺点:(1)其模型的主体仍然是GNN,并阻止它们进行更可解释的预测;(2)它们是单一模型而不是框架,因此与其他高级GNN架构不兼容;(3)他们忽略了另一个重要的先验知识,即基于特征的先验知识,这意味着节点的标签完全由其自身的特征确定。
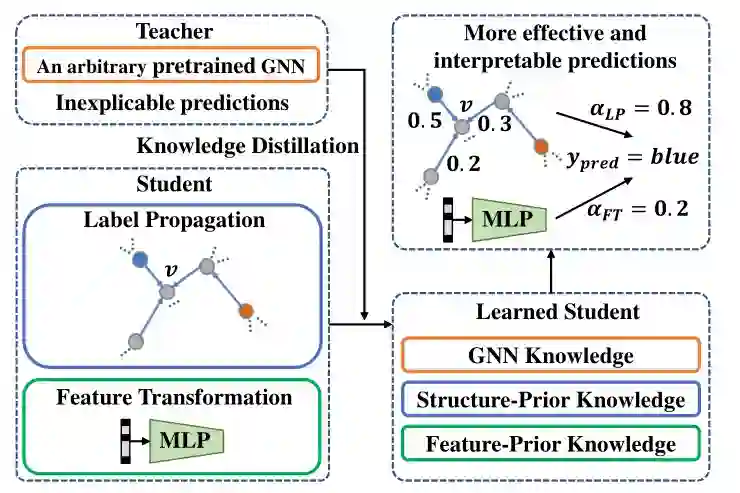
为了解决这些问题,我们提出了一个有效的知识蒸馏框架,以将任意预训练的GNN教师模型的知识注入精心设计的学生模型中。学生模型是通过两个简单的预测机制构建的,即标签传播和特征转换,它们自然分别保留了基于结构和基于特征的先验知识。具体来说,我们将学生模型设计为参数化标签传播和基于特征的2层感知机(MLP)的可训练组合。另一方面,已有研究表明,教师模型的知识在于其软预测[9]。通过模拟教师模型预测的软标签,我们的学生模型能够进一步利用预训练的GNN中的知识。因此,学习的学生模型具有更可解释的预测过程,并且可以利用GNN和基于结构/特征的先验知识。我们的框架概述如图1所示。 图片
图1:我们的知识蒸馏框架的示意图。学生模型的两种简单预测机制可确保充分利用基于结构/功能的先验知识。在知识蒸馏过程中,将提取GNN教师中的知识并将其注入学生。因此,学生可以超越其相应的老师,得到更有效和可解释的预测。
我们在五个公共基准数据集上进行了实验,并采用了几种流行的GNN模型,包括GCN[12]、GAT[30]、SAGE[8]、APPNP[13]、SGC[33]和最新的深层GCN模型GCNII[4]作为教师模型。实验结果表明,就分类精度而言,学生模型的表现优于其相应的教师模型1.4%-4.7%。值得注意的是,我们也将框架应用于GLP[15],它通过操纵图过滤器来统一GCN和标签传播。结果,我们仍然可以获得1.5%-2.3%的相对改进,这表明了我们框架的潜在兼容性。此外,我们通过探究参数化标签传播与特征转换之间的可学习平衡参数以及标签传播中每个节点的可学习置信度得分,来研究学生模型的可解释性。总而言之,改进是一致,并且更重要的是,它具有更好的可解释性。
本文的贡献总结如下:
- 我们提出了一个有效的知识蒸馏框架,以提取任意预训练的GNN模型的知识,并将其注入学生模型,以实现更有效和可解释的预测。
- 我们将学生模型设计为参数化标签传播和基于特征的两层MLP的可训练组合。因此,学生模型有一个更可解释的预测过程,并自然地保留了基于结构/特征的先验。因此,学习的学生模型可以同时利用GNN和先验知识。
- 五个基准数据集和七个GNN教师模型上的实验结果表明了我们的框架有效性。对学生模型中学习权重的广泛研究也说明了我们方法的可解释性。