
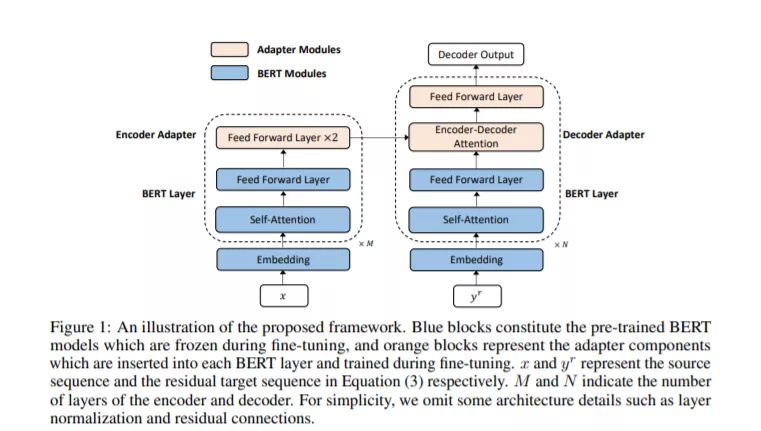
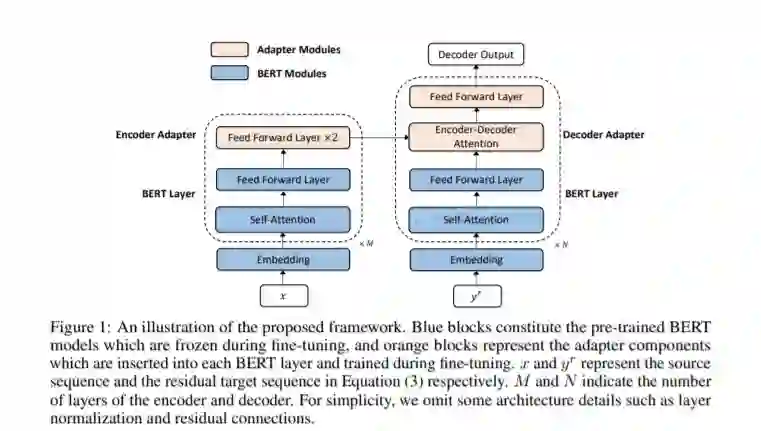
虽然BERT等大规模的预训练语言模型在各种自然语言理解任务上取得了巨大的成功,但如何高效、有效地将它们合并到序列到序列模型和相应的文本生成任务中仍然是一个不容忽视的问题。为了解决这个问题,我们提出采用两种不同的BERT模型分别作为编码器和解码器,并通过引入简单的和轻量级的适配器模块对它们进行微调,这些适配器模块插入到BERT层之间,并针对特定的任务数据集进行调优。这样,我们得到了一个灵活高效的模型,它能够联合利用源端和目标端BERT模型中包含的信息,同时绕过了灾难性遗忘问题。框架中的每个组件都可以看作是一个插件单元,使得框架灵活且任务不相关。该框架基于并行序列译码算法掩模预测,考虑了BERT算法的双向和条件独立性,易于适应传统的自回归译码。我们在神经机器翻译任务上进行了广泛的实验,在实验中,所提出的方法始终优于自回归基线,同时将推理延迟减少了一半,并且在IWSLT14德语-英语/WMT14德语-英语翻译中达到36.49/33.57的BLEU分数。当采用自回归译码时,该方法在WMT14英-德/英-法翻译中的BLEU得分达到30.60/43.56,与最先进的基线模型相当。
成为VIP会员查看完整内容
相关内容

专知会员服务
51+阅读 · 2020年3月7日
相关VIP内容
专知会员服务
51+阅读 · 2020年3月7日
相关资讯
相关论文