
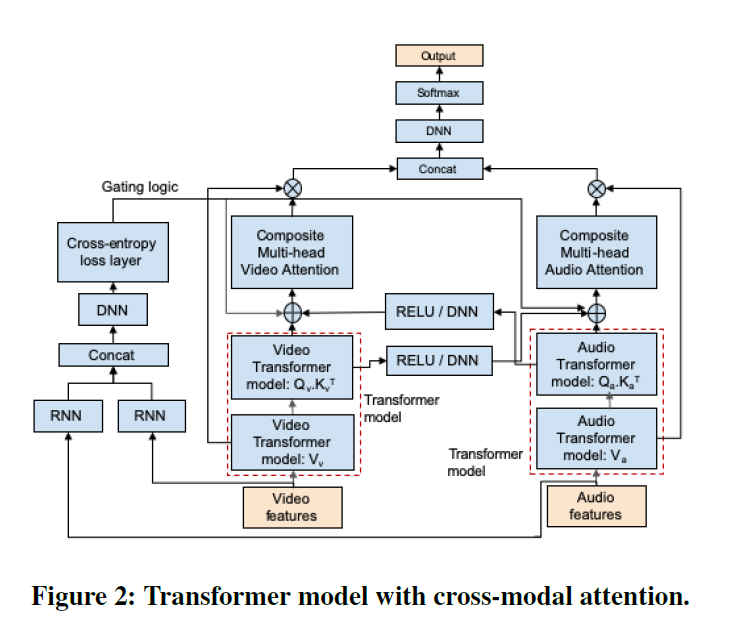
视频通常有多种形式的数据,如音频、视频、文本(字幕)。理解和建模不同模态之间的交互是视频分析任务的关键,如分类,目标检测,活动识别等。然而,数据模态并不总是相关的——因此,了解模态何时相关并使用它来引导一种模态对另一种模态的影响是至关重要的。视频的另一个显著特征是连续帧之间的连贯性,这是由于视频和音频的连续性,我们称之为时间连贯性。我们展示了如何使用非线性引导的跨模态信号和时间相干性来提高多模态机器学习(ML)模型在视频分析任务(如分类)中的性能。我们在大规模YouTube-8M数据集上的实验表明,我们的方法在视频分类方面显著优于最先进的多模式ML模型。在YouTube-8M数据集上训练的模型,在不需要再训练和微调的情况下,在一个来自实际电视频道的视频片段的内部数据集上也表现出了良好的性能,显示了我们的模型较强的泛化能力。
成为VIP会员查看完整内容
相关内容



相关VIP内容
相关资讯
相关论文