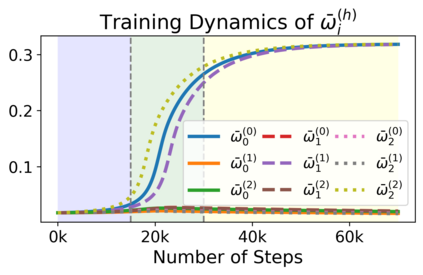
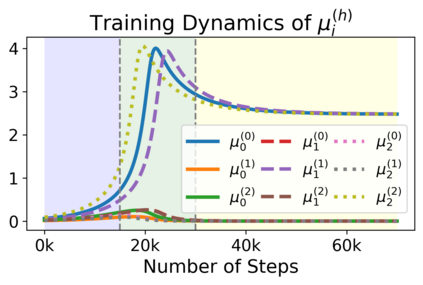
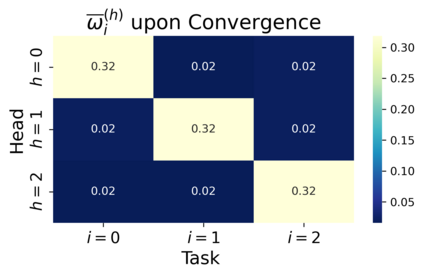
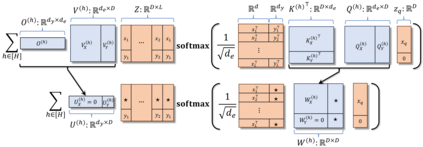
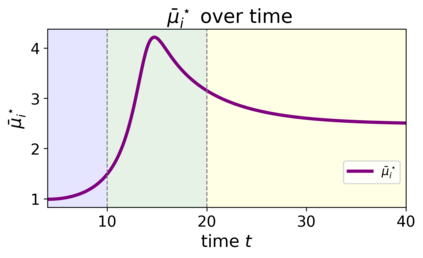
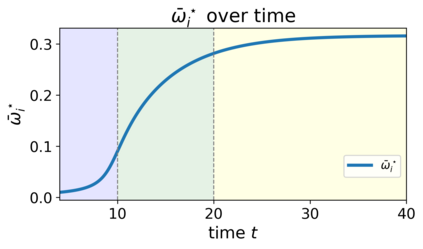
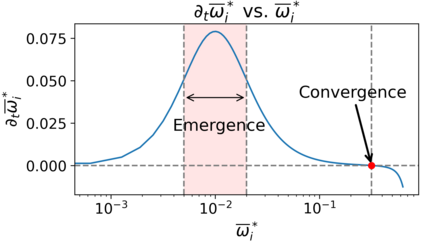
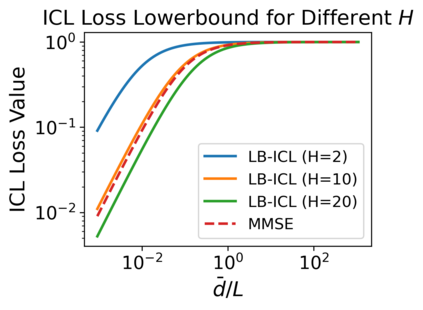
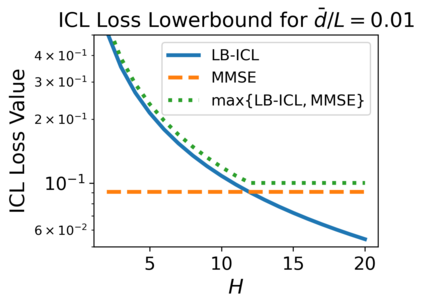
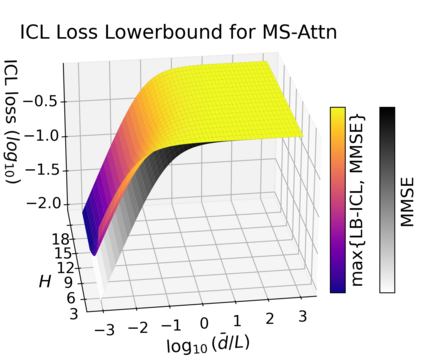
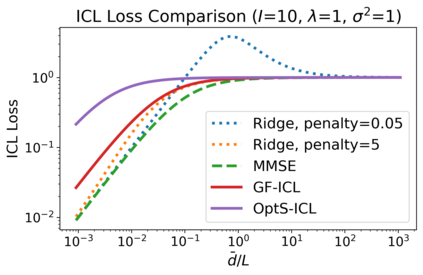
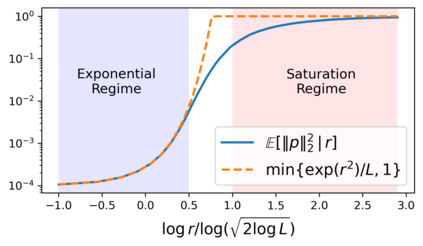
We study the dynamics of gradient flow for training a multi-head softmax attention model for in-context learning of multi-task linear regression. We establish the global convergence of gradient flow under suitable choices of initialization. In addition, we prove that an interesting "task allocation" phenomenon emerges during the gradient flow dynamics, where each attention head focuses on solving a single task of the multi-task model. Specifically, we prove that the gradient flow dynamics can be split into three phases -- a warm-up phase where the loss decreases rather slowly and the attention heads gradually build up their inclination towards individual tasks, an emergence phase where each head selects a single task and the loss rapidly decreases, and a convergence phase where the attention parameters converge to a limit. Furthermore, we prove the optimality of gradient flow in the sense that the limiting model learned by gradient flow is on par with the best possible multi-head softmax attention model up to a constant factor. Our analysis also delineates a strict separation in terms of the prediction accuracy of ICL between single-head and multi-head attention models. The key technique for our convergence analysis is to map the gradient flow dynamics in the parameter space to a set of ordinary differential equations in the spectral domain, where the relative magnitudes of the semi-singular values of the attention weights determines task allocation. To our best knowledge, our work provides the first convergence result for the multi-head softmax attention model.
翻译:暂无翻译