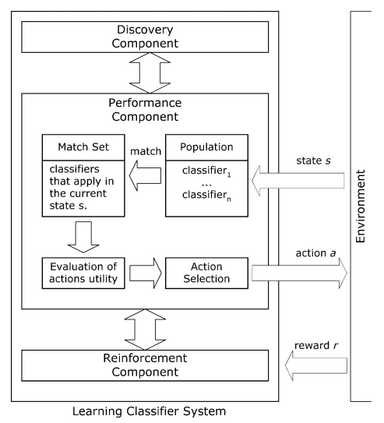
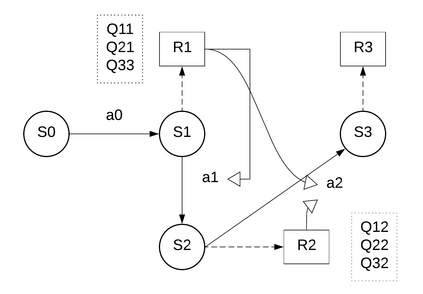
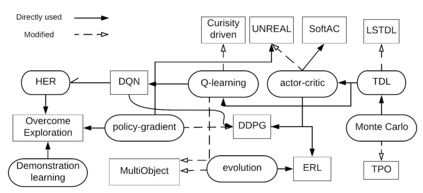
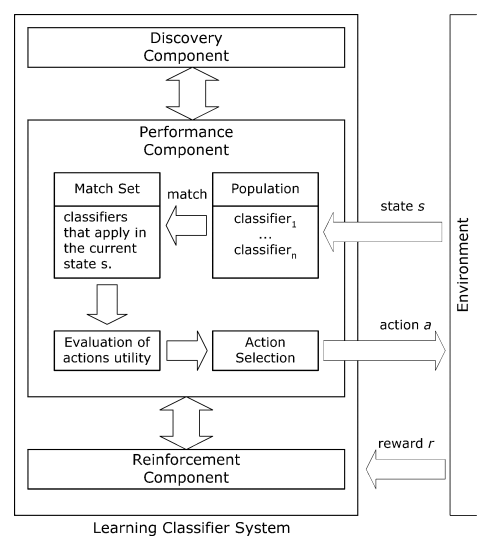
Reinforcement learning is one of the core components in designing an artificial intelligent system emphasizing real-time response. Reinforcement learning influences the system to take actions within an arbitrary environment either having previous knowledge about the environment model or not. In this paper, we present a comprehensive study on Reinforcement Learning focusing on various dimensions including challenges, the recent development of different state-of-the-art techniques, and future directions. The fundamental objective of this paper is to provide a framework for the presentation of available methods of reinforcement learning that is informative enough and simple to follow for the new researchers and academics in this domain considering the latest concerns. First, we illustrated the core techniques of reinforcement learning in an easily understandable and comparable way. Finally, we analyzed and depicted the recent developments in reinforcement learning approaches. My analysis pointed out that most of the models focused on tuning policy values rather than tuning other things in a particular state of reasoning.
翻译:强化学习是设计强调实时反应的人工智能系统的核心组成部分之一。强化学习影响着系统在任意的环境中采取行动,无论是以前是否了解环境模式。在本文件中,我们提出了一份关于强化学习的综合研究,侧重于各方面,包括挑战、最近发展不同先进技术以及未来方向。本文件的基本目标是提供一个框架,介绍现有的强化学习方法,为这一领域新的研究人员和学者提供足够和简单的信息,以便他们能够了解最新的关切。首先,我们以易于理解和可比的方式展示了强化学习的核心技术。最后,我们分析和描述了加强学习方法的最新发展。我的分析指出,大多数模式侧重于调整政策价值,而不是在特定推理状态下调整其他事物。