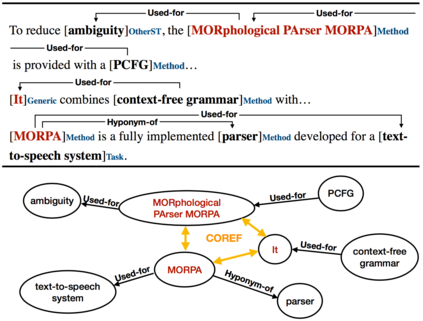
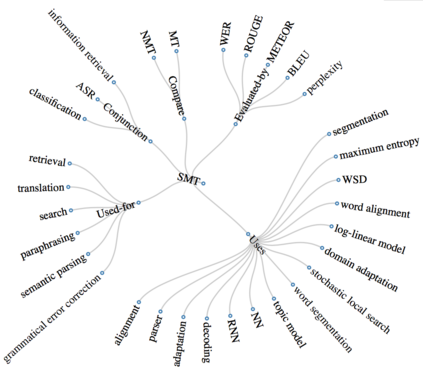
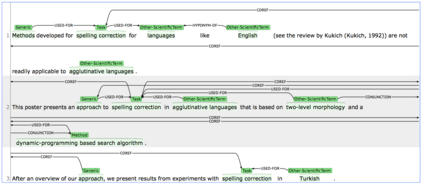
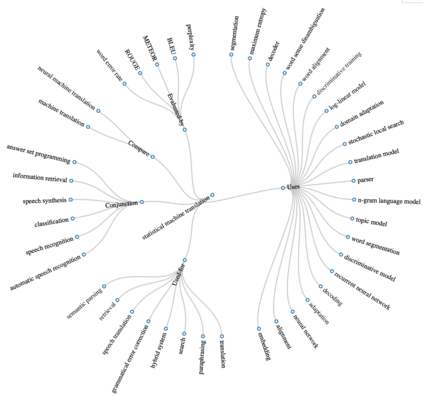
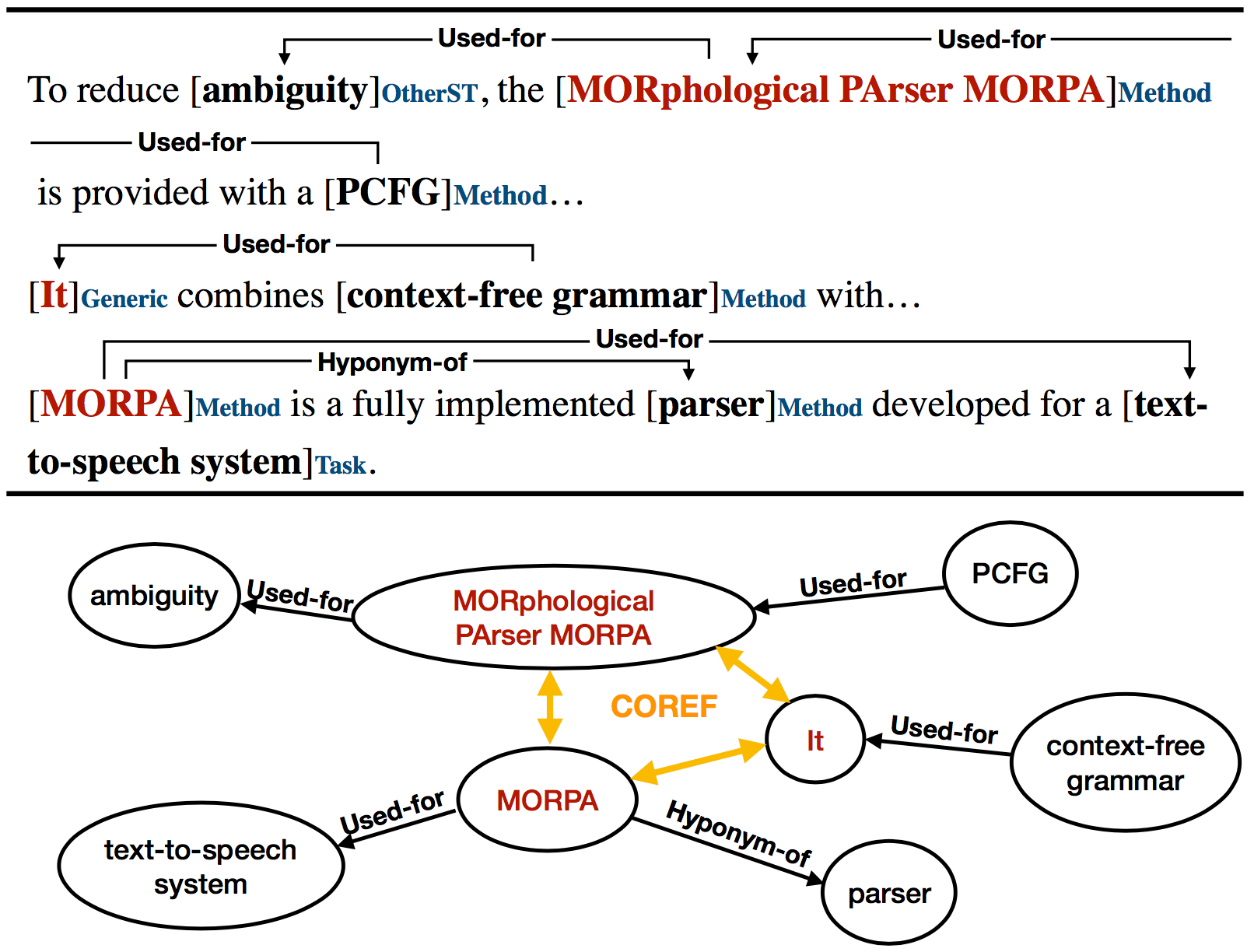
We introduce a multi-task setup of identifying and classifying entities, relations, and coreference clusters in scientific articles. We create SciERC, a dataset that includes annotations for all three tasks and develop a unified framework called Scientific Information Extractor (SciIE) for with shared span representations. The multi-task setup reduces cascading errors between tasks and leverages cross-sentence relations through coreference links. Experiments show that our multi-task model outperforms previous models in scientific information extraction without using any domain-specific features. We further show that the framework supports construction of a scientific knowledge graph, which we use to analyze information in scientific literature.
翻译:我们引入了多种任务设置,在科学文章中识别和分类实体、关系和共同参照群集。我们创建了SciERC,这是一个包含所有三项任务说明的数据集,并开发了一个称为科学信息提取器(SciIE)的统一框架,用于共享跨区域代表。多任务设置可以减少任务之间的层层错误,并通过连接连接影响交叉供述关系。实验表明,我们的多任务模型在科学信息提取中优于以往的模型,而没有使用任何特定领域特征。我们进一步表明,该框架支持构建科学知识图表,我们用它来分析科学文献中的信息。