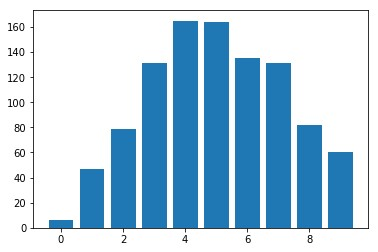
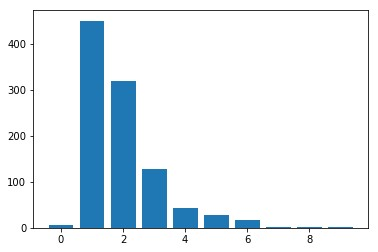
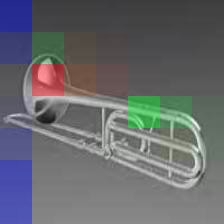
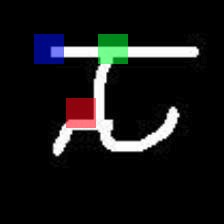
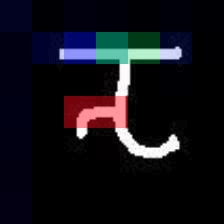
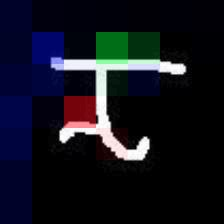
Given new tasks with very little data$-$such as new classes in a classification problem or a domain shift in the input$-$performance of modern vision systems degrades remarkably quickly. In this work, we illustrate how the neural network representations which underpin modern vision systems are subject to supervision collapse, whereby they lose any information that is not necessary for performing the training task, including information that may be necessary for transfer to new tasks or domains. We then propose two methods to mitigate this problem. First, we employ self-supervised learning to encourage general-purpose features that transfer better. Second, we propose a novel Transformer based neural network architecture called CrossTransformers, which can take a small number of labeled images and an unlabeled query, find coarse spatial correspondence between the query and the labeled images, and then infer class membership by computing distances between spatially-corresponding features. The result is a classifier that is more robust to task and domain shift, which we demonstrate via state-of-the-art performance on Meta-Dataset, a recent dataset for evaluating transfer from ImageNet to many other vision datasets.
翻译:鉴于新任务中的数据很少,例如分类问题中的新类别美元,或者现代视觉系统投入-美元表现的域变换等新任务,现代视觉系统投入-美元表现中的投入-美元方面的新类别等,这些新任务迅速退化。在这项工作中,我们举例说明了支持现代视觉系统的神经网络表现会如何导致监督崩溃,从而导致它们失去执行培训任务所不需要的任何信息,包括转移到新任务或领域所需的信息。我们然后提出缓解这一问题的两种方法。首先,我们采用自我监督的学习方法,鼓励更佳转让的通用特征。第二,我们提出了一个新的基于变异器的神经网络结构,称为Cross Transfex,它可以采取少量标签图像和未标注查询,在查询和标签图像之间找到粗糙的空间通信,然后通过计算空间对称响应功能之间的距离来推断阶级成员。结果是一个任务和域变更坚固的分类器,我们通过Met-Dataset的状态性能演示,这是用来评价从图像网络向许多其他视觉数据集传输的最新数据集。