
来自UIUC的Transformers最新教程。
Transformer 架构 architecture Attention models Implementation details Transformer-based 语言模型 language models BERT GPT Other models
Transformer 视觉 Applications of Transformers in vision
成为VIP会员查看完整内容
相关内容

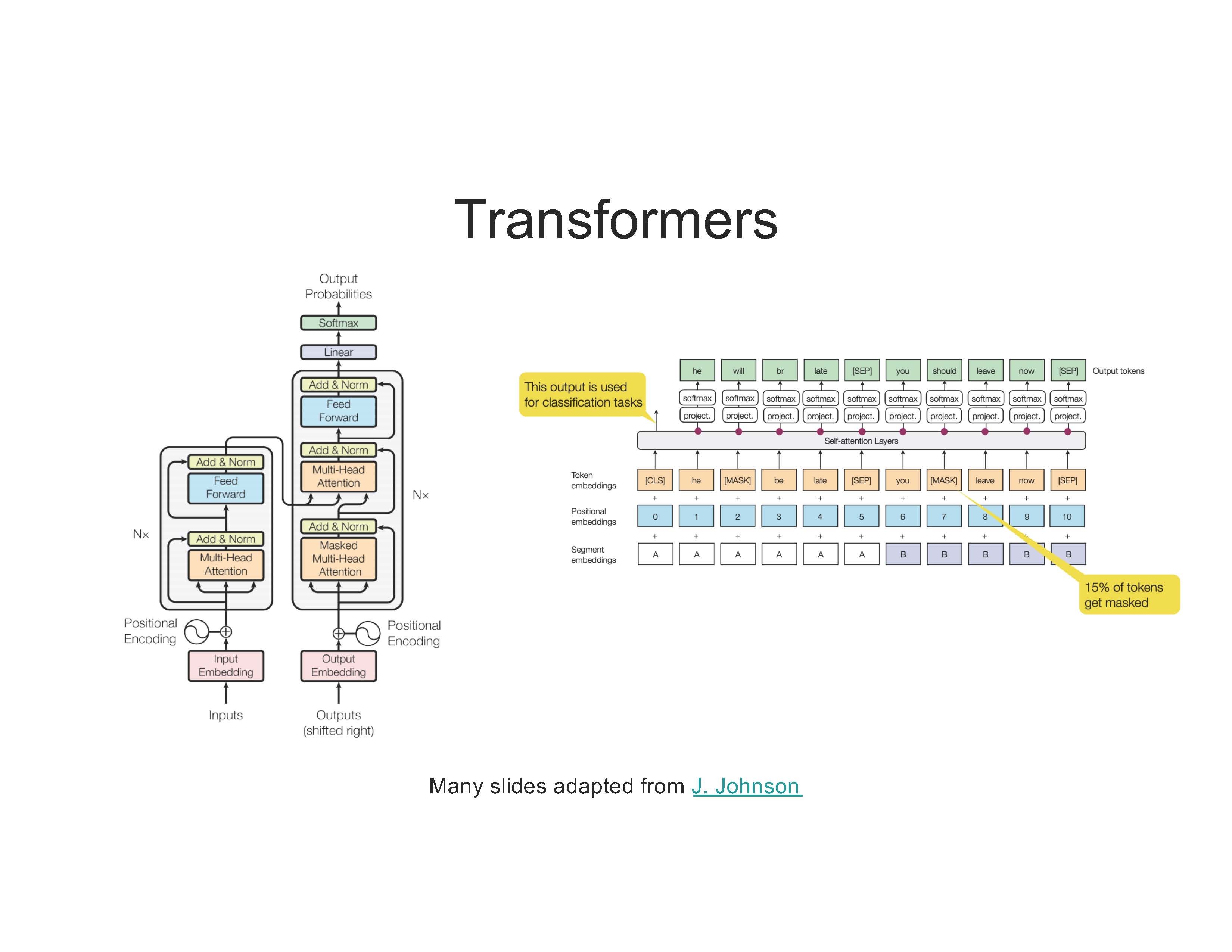
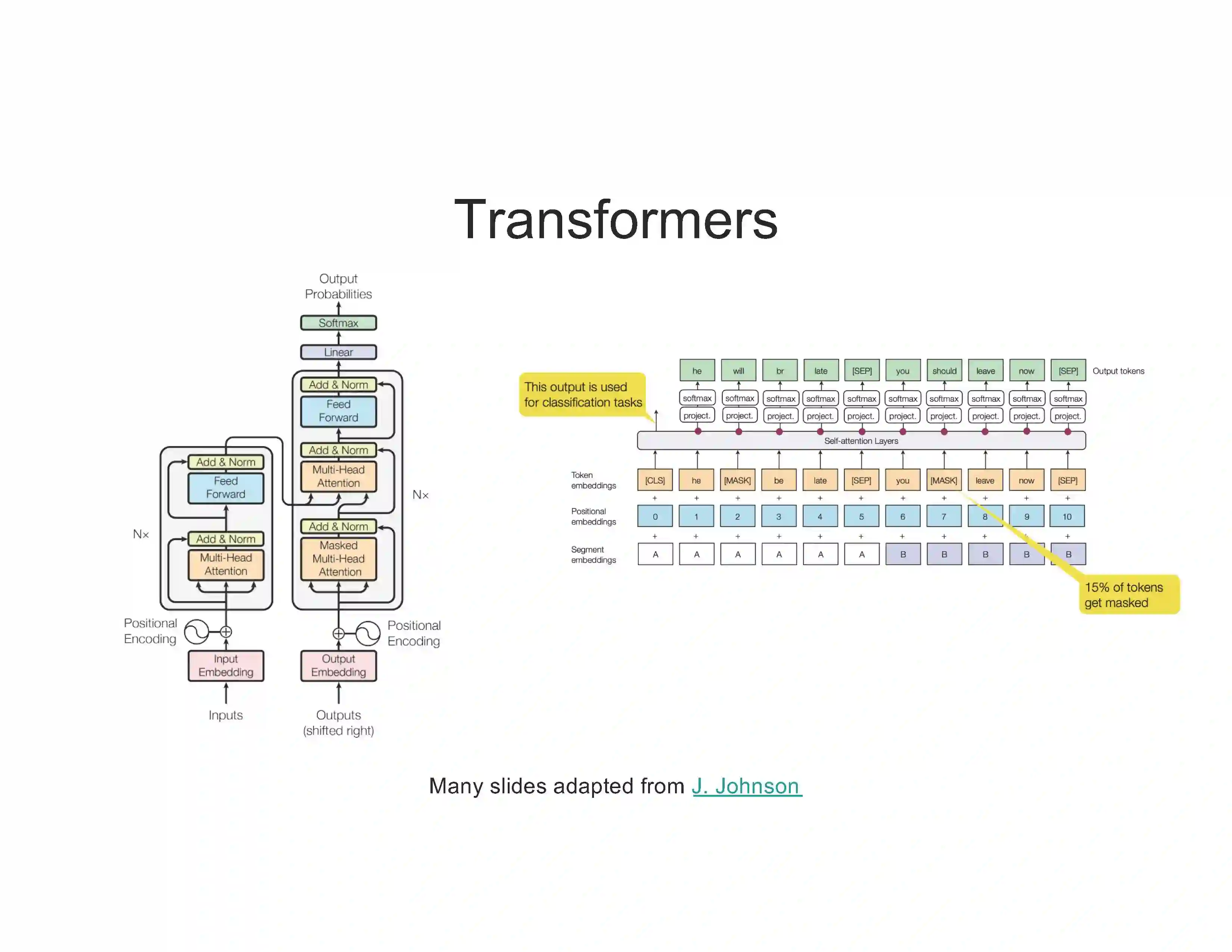
Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
相关主题
相关VIP内容
相关资讯
相关论文