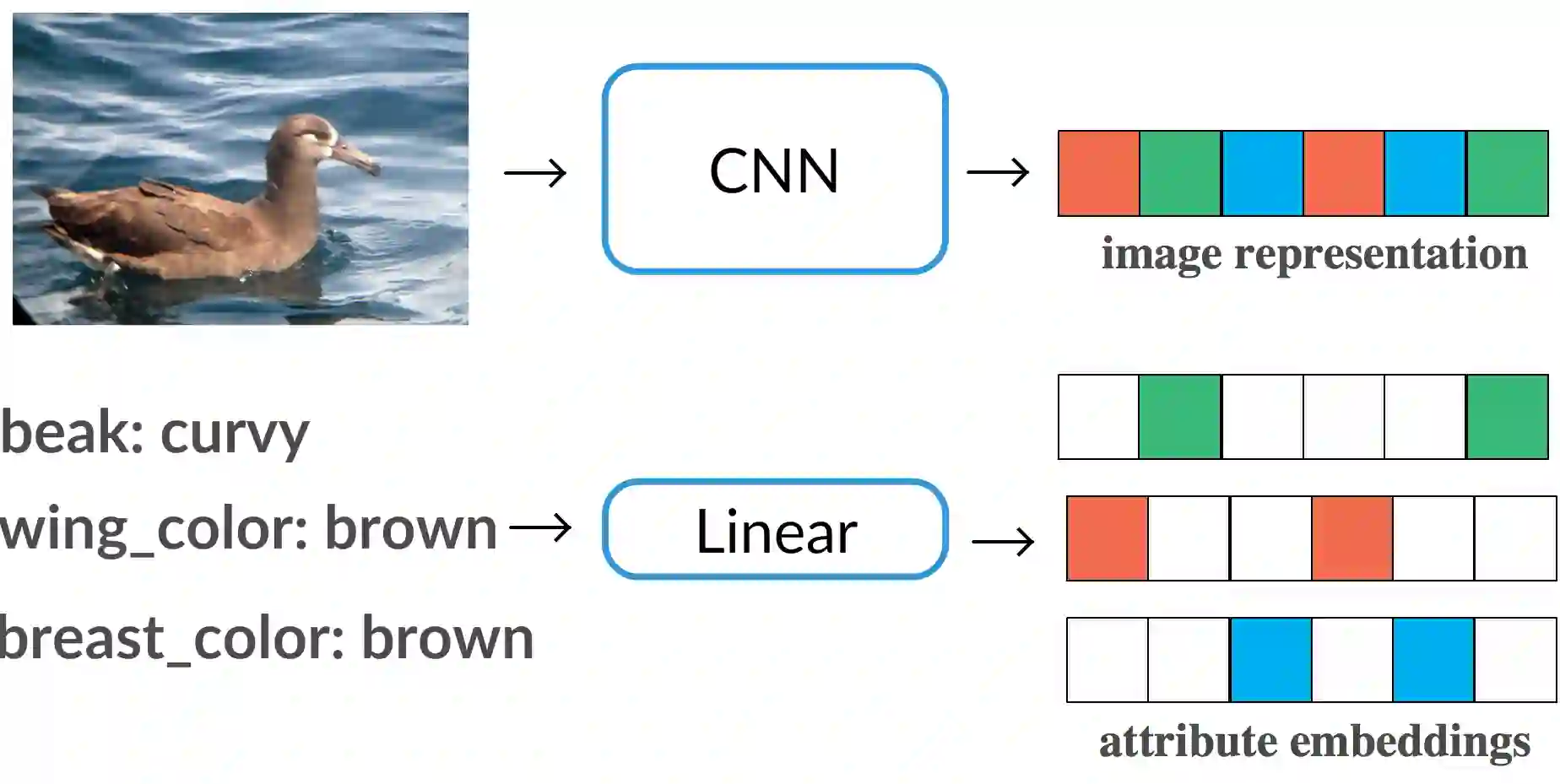
One of the key limitations of modern deep learning based approaches lies in the amount of data required to train them. Humans, on the other hand, can learn to recognize novel categories from just a few examples. Instrumental to this rapid learning ability is the compositional structure of concept representations in the human brain - something that deep learning models are lacking. In this work we make a step towards bridging this gap between human and machine learning by introducing a simple regularization technique that allows the learned representation to be decomposable into parts. We evaluate the proposed approach on three datasets: CUB-200-2011, SUN397, and ImageNet, and demonstrate that our compositional representations require fewer examples to learn classifiers for novel categories, outperforming state-of-the-art few-shot learning approaches by a significant margin.
翻译:现代深层次学习方法的主要局限性之一在于培训它们所需要的数据数量。另一方面,人类可以从几个例子中学会识别新类别。这种快速学习能力的工具是人类大脑中概念表达的构成结构,这是深层次学习模式所缺乏的。在这项工作中,我们采取了简单的正规化技术,使学习到的表述可以分解为部分,从而缩小人类学习与机器学习之间的差距。我们评估了三个数据集:CUB-200-2011、SUN397和图像网络的拟议方法,并表明我们的组合表现需要较少的例子来学习新类别分类,表现优于最先进的少见的学习方法。