预训练语言模型
·

https://ruder.io/recent-advances-lm-fine-tuning/index.html
在过去的三年里, fine-tuning的方法已经取代了从预训练embedding做特征提取的方法,而预训练语言模型由于其训练效率和出色的性能受到各种任务的青睐,如机器翻译,自然语言推理等,在这些方法上的成功经验也导致了后来像BERT,T5这样更大模型的出现。最近,如GPT-3这样的模型,数据规模实际上已经大到在不需要任何参数更新的情况下也可以取得非常优异的性能。然而,这种zero-shot场景毕竟存在着一定的限制。为了达到最佳性能或保持效率,在使用大型的预训练语言模型时,fine-tuning依然会作为主流方法而继续存在。
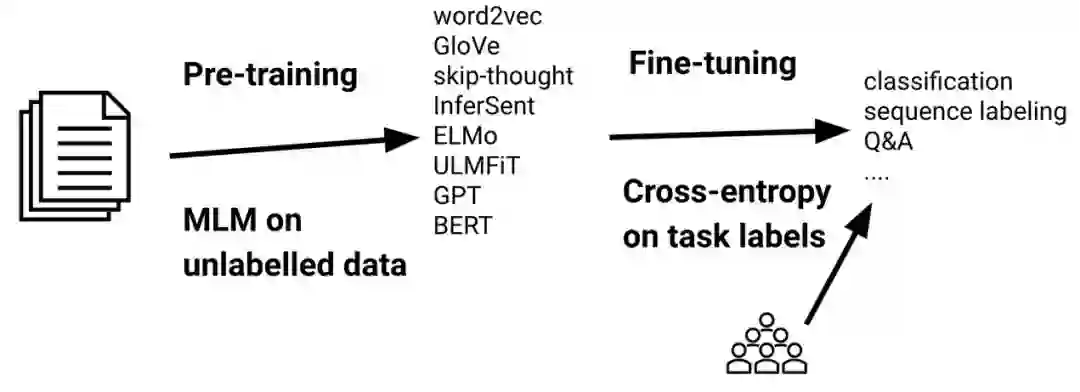
如下图,在标准的迁移学习场景中,首先在大规模无监督数据上使用建模语言特征的loss(如MLM)对一个模型做预训练,然后在下游任务的有标签数据上使用标准的cross-entropy loss对预训练模型做fine-tuning。
标准的pre-train —— fine-tuning 场景
虽然预训练依赖于大量的计算资源,但是fine-tuning只需要使用少量计算资源。因此,在对语言模型的实际使用中,fine-tuning就显得更为重要,例如,Hugging Face的模型库截至目前就已经被下载使用了数百万次之多。基于此,fine-tuning将是本文的讲述重点,尤其将重点介绍可能会影响我们fine-tune模型方式的一些近期进展。本文将分类介绍几种fine-tuning方法,如下图所示:

成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2019年5月6日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年5月6日