摘要
在只有很少数据的情况下,如分类问题中的新类别或输入中的域变换,现代视觉系统的性能会急剧下降。在这项工作中,我们说明了支撑现代视觉系统的神经网络表征如何受到监督崩塌的影响,从而丢失了执行训练任务所不需要的任何信息,包括迁移到新任务或领域所需要的信息。然后我们提出了两种方法来缓解这一问题。首先,我们采用自监督学习来鼓励能够更好地迁移的通用特性。第二,我们提出一种新颖的基于Transformer的神经网络结构称为CrossTransformers,这可能需要少量的标记图像和一个无标签查询,发现粗空间对应查询和标签之间的图像,然后通过计算相应空间之间的距离特性推断相似类别的样本。结果是一个分类器在任务和领域迁移方面更加具有鲁棒性,我们通过在Meta-Dataset上的最先进的性能来证明这一点,Meta-Dataset是一个最近的数据集,用于评估从ImageNet到许多其他视觉数据集的迁移。
介绍
通用视觉系统必须具有适应性。比如家庭机器人必须能够在新的、看不见的家庭中操作;照片组织软件必须能够识别看不见的物体(例如,寻找我六年级儿子的抽象艺术作品的样本);工业质量保证体系必须发现新产品中的缺陷。深度神经网络表示可以从像ImageNet这样的数据集中带来一些视觉知识,用于ImageNet之外的不同任务,但从经验上讲,这需要在新任务中使用大量的标记数据。如果标签数据太少,或者在分布上有大的变化,这样的系统在实际上会表现很差。元学习研究直接衡量适应性。在训练时,算法会收到大量的数据和伴随的监督(如标签)。然而,在测试时,算法会接收到一系列的片段,每个片段都由一小部分数据点组成,这些数据点来自不同于训练集的分布(例如,不同的域或不同的类别)。只有这些数据的一个子集有伴随的监督(称为支持集);算法必须对其余部分(查询集)进行预测。元数据集尤其与视觉相关,因为它的挑战是小样本细粒度图像分类。训练数据是ImageNet类的子集。在测试时,每一集都包含来自其他ImageNet类的图像,或者来自其他九个细粒度识别数据集之一的图像。算法必须快速调整其表示以适应新的类别和域。 简单的基于中心的算法,如Prototypical Nets在Meta-Dataset方面处于或接近最先进的水平,并且在支持集的外置ImageNet类上可以达到大约50%的精度(概率大约是1 / 20)。在同样的挑战下,在这些外面的类上训练等价的分类器可以达到84%的准确率。是什么导致了性能上的巨大差异分布内样本和分布外样本?我们假设典型的网络,像大多数元学习算法一样,很少要求表示捕获训练集以外的任何东西。由于核心神经网络是为分类而设计的,它们倾向于这样做:只表示类别信息,而丢失可能在训练类别之外有用的信息。我们称这个问题为监督崩塌,并在图1中说明了这个问题。

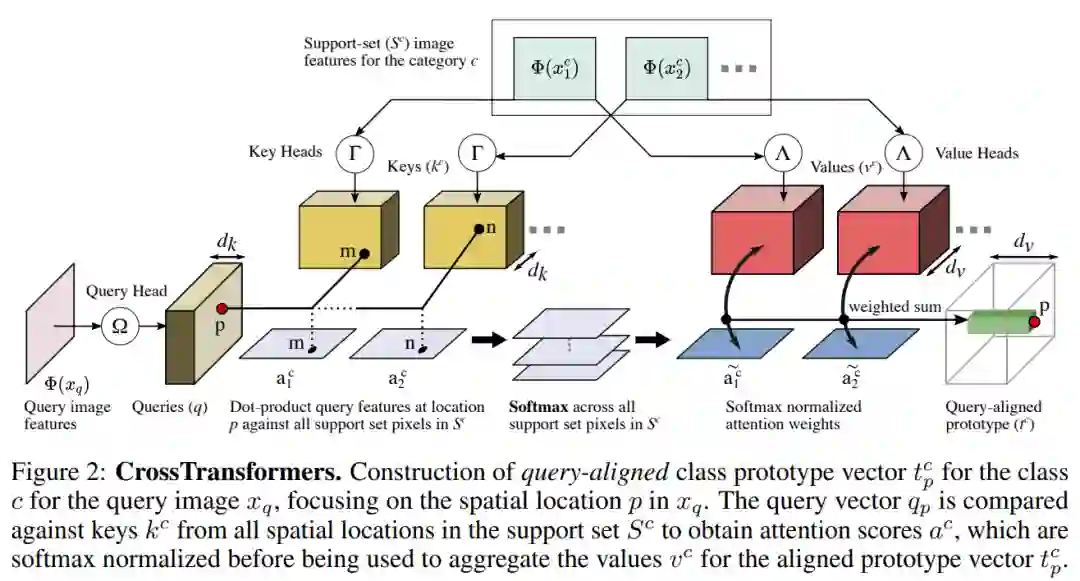
我们的第一个贡献是探索用自我监督来克服监督崩塌。我们使用SimCLR学习嵌入,区分数据集中的每个图像,同时保持不变的转换(例如,裁剪和颜色转移),因此捕获的不仅仅是类别的信息。然而,与其将SimCLR视为一种辅助损失,不如将SimCLR重新定制为可以以同样的方式分类为训练插曲的插曲。我们的第二个贡献是提出一种被称为CrossTransformers的新架构,它将Transformer扩展到小样本的细粒度分类。我们的关键见解是,物体和场景通常由较小的部分组成,局部外观可能与训练时看到的相似。这方面的经典例子是出现在早期几篇关于视觉的论文中的半人马,其中人和马的部分组成了半人马。
CrossTransformers的操作持有这一观点(i)基于部分的局部比较,和(2)考虑空间对齐,让程序去比较与底层类无关的图像。更详细地说,首先使用Transformer中的注意力来构建查询集和支持集图像中的几何或功能部分之间的粗对齐。然后,给定这种对齐方式,计算相应局部特征之间的距离来指导分类。我们将演示这将改进未见类和域的泛化。
综上所述,我们在本文中的贡献是:(i)我们通过自监督技术提高了局部特征的鲁棒性,修改了最先进的SimCLR算法。(ii)我们提出了CrossTransformers,这是一种空间感知的网络架构,使用更多的局部特征进行小样本分类,从而改进了迁移。最后,(iii)我们评估和分析了这些算法的选择如何影响Meta-Dataset集的性能,并在其中几乎每一个数据集上展示最先进的结果。