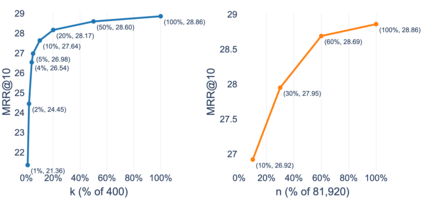
The semantic matching capabilities of neural information retrieval can ameliorate synonymy and polysemy problems of symbolic approaches. However, neural models' dense representations are more suitable for re-ranking, due to their inefficiency. Sparse representations, either in symbolic or latent form, are more efficient with an inverted index. Taking the merits of the sparse and dense representations, we propose an ultra-high dimensional (UHD) representation scheme equipped with directly controllable sparsity. UHD's large capacity and minimal noise and interference among the dimensions allow for binarized representations, which are highly efficient for storage and search. Also proposed is a bucketing method, where the embeddings from multiple layers of BERT are selected/merged to represent diverse linguistic aspects. We test our models with MS MARCO and TREC CAR, showing that our models outperforms other sparse models
翻译:神经信息检索的语义匹配能力可以改善象征性方法的同义和多细胞问题。然而,神经模型的密度表示由于效率低,更适合重新排列,但神经模型的密度表示由于其效率低而更适合重新排列。以象征或潜在形式出现的粗化表示,以反向指数更有效率。根据分散和密集的表示的优点,我们提议一个超高维(UHD)代表机制,配有直接可控制的聚度。UHD的巨大容量和最小的噪音及各维度的干扰使得能够进行二元化的表示,对于储存和搜索来说,这些表示效率很高。还提出了一种桶装方法,从多层BERT中挑选/合并嵌入,以代表不同的语言方面。我们用MS MARCO和TREC CAR测试我们的模型,显示我们的模型比其他稀少的模式要强。