
https://www.zhuanzhi.ai/paper/ed630ac577c1df4b28acd624e58a0432
当前主流的视频文本检索模型基本上都采用了基于 Transformer[1] 的多模态学习框架,主要可以分成 3 类:
Two-stream,文本和视觉信息分别通过独立的 Vision Transformer 和 Text Transformer,然后在多模态 Transformer 中融合,代表方法例如 ViLBERT[2]、LXMERT[3] 等。
Single-stream,文本和视觉信息只通过一个多模态 Transformer 进行融合,代表方法例如 VisualBERT[4]、Unicoder-VL[5] 等。
Dual-stream,文本和视觉信息仅仅分别通过独立的 Vision Transformer 和 Text Transformer,代表方法例如 COOT[6]、T2VLAD[7] 等。
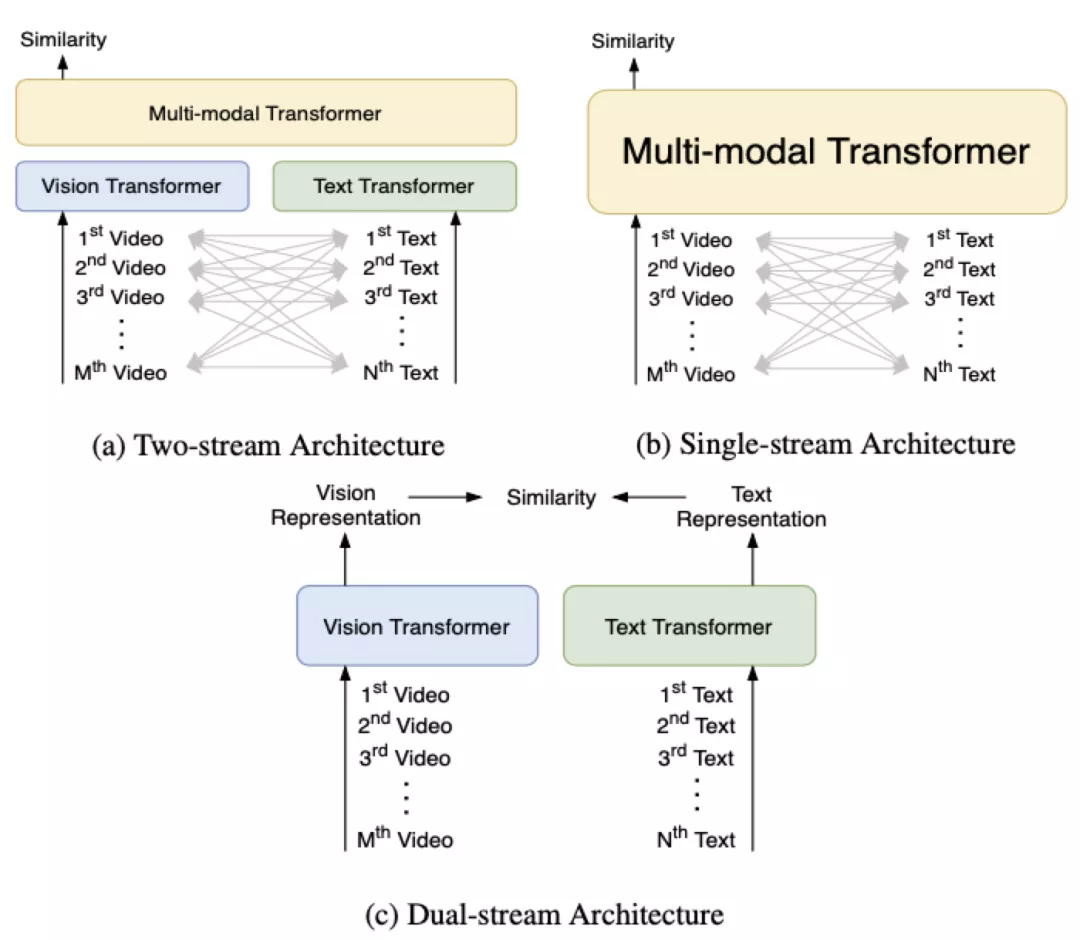
由于类别 1 和类别 2 方法在时间开销上的限制,本文提出的 HiT( Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval)[8] 模型采用了类别 3 Dual-stream 的 Transformer 框架,以满足大规模视频文本检索的需求。然而现有基于 Transformer 的多模态学习方法会有两个局限性:
Transformer 不同网络层的输出具有不同层次的特性,而现有方法并没有充分利用这一特性;
端到端模型受到显存容量的限制,无法在一个 batch 内利用较多的负样本。
针对上述 2 个局限,本文提出(1)层次跨模态对比匹配(Hierarchical Cross-modal Contrast Matching,HCM),对 Transformer 的底层网络和高层网络分别进行对比匹配,解决局限 1 的问题;(2)引入 MoCo[9] 的动量更新机制到跨模态对比匹配中,使跨模态对比匹配的过程中能充分利用更多的负样本,解决局限 2 的问题。实验表明 HiT 在多个视频-文本检索数据集上取得 SOTA 的效果。
HiT 模型主要有两个创新点:
提出层次跨模态对比匹配 HCM。Transformer 的底层和高层侧重编码不同层次的信息,以文本输入和 BERT[10] 模型为例,底层 Transformer 侧重于编码相对简单的基本语法信息,而高层 Transformer 则侧重于编码相对复杂的高级语义信息。因此使用 HCM 进行多次对比匹配,可以利用 Transformer 这一层次特性,从而得到更好的视频文本检索性能;
引入 MoCo 的动量更新机制到跨模态对比匹配中,提出动量跨模态对比 MCC。MCC 为文本信息和视觉信息分别维护了一个容量很大并且表征一致的负样本队列,从而克服端到端训练方法受到显存容量的限制,只能在一个相对较小的 batch 内寻找负样本这一缺点,利用更多的负例,从而得到更好的视频和文本表征。

