【表示学习(Representation Learning)】8篇 NeurIPS 2019论文选读
NeurIPS 2019(Neural Information Processing Systems)将在12月8日-14日在加拿大温哥华举行。NeurIPS 是全球最受瞩目的AI、机器学习顶级学术会议之一,每年全球的人工智能爱好者和科学家都会在这里聚集,发布最新研究。今天小编整理了表示学习相关论文。
![]()
1. Self-attention with Functional Time Representation Learning

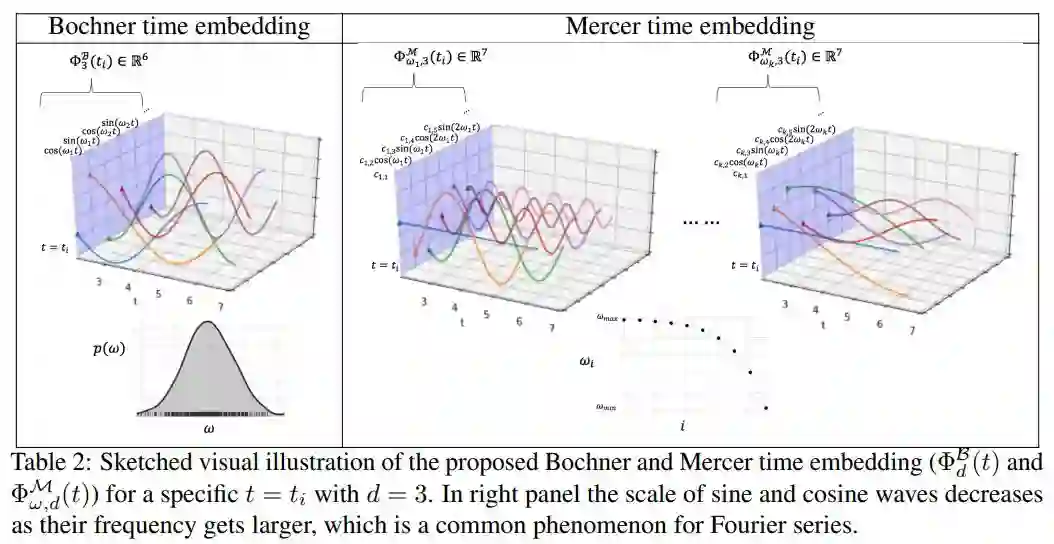
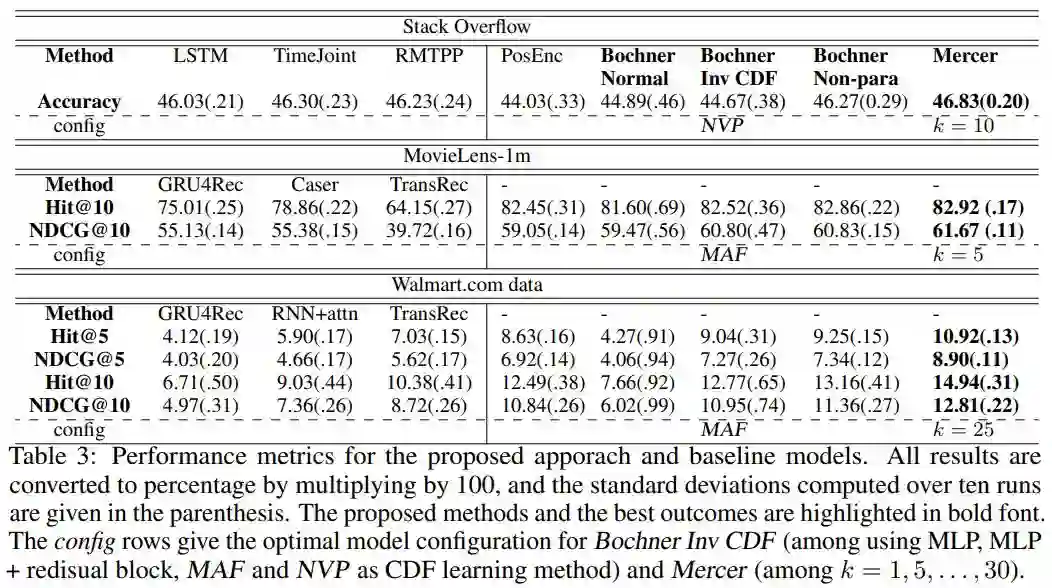
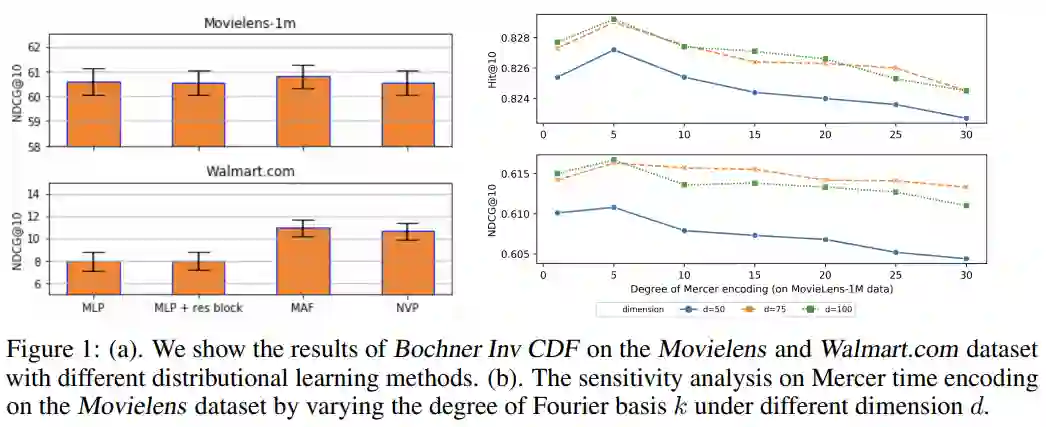
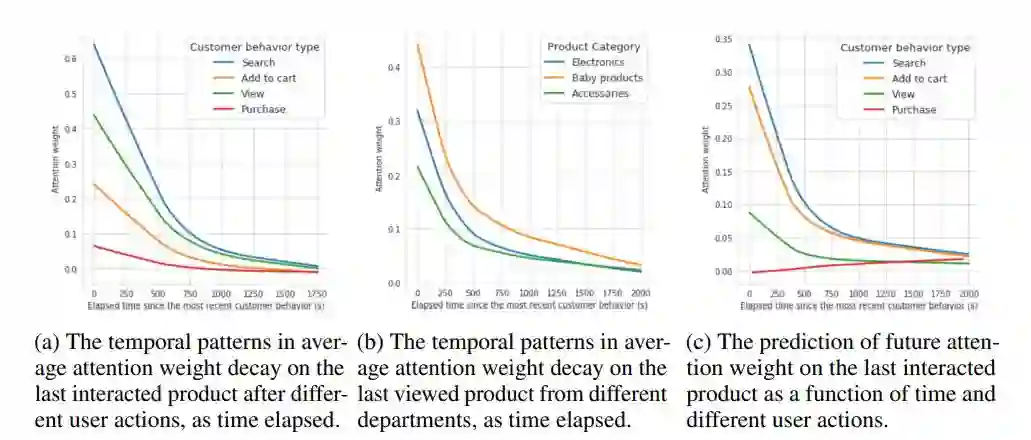
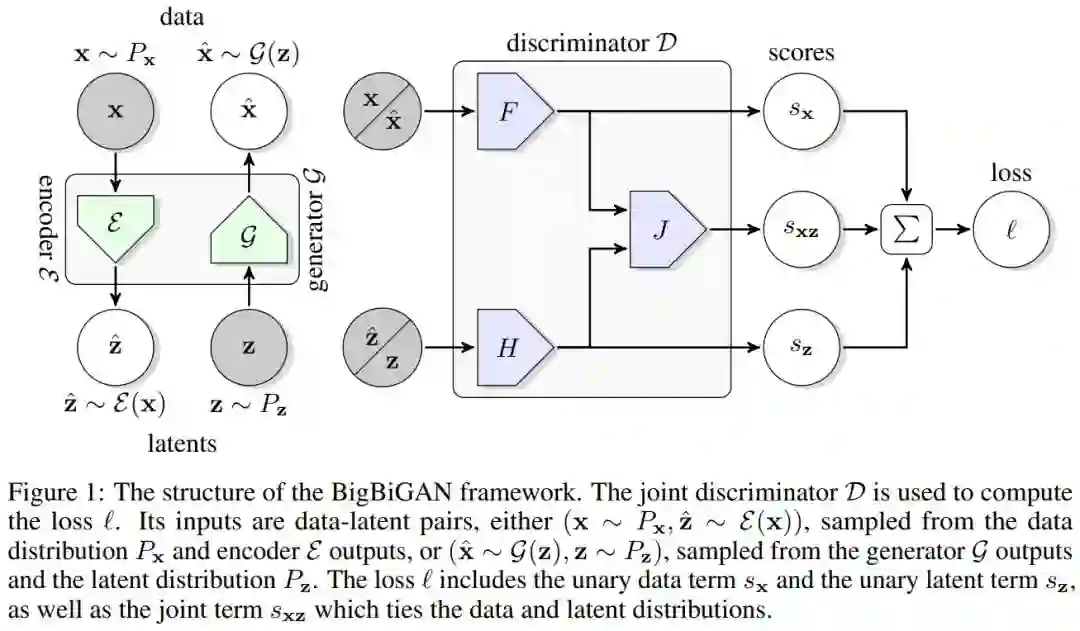
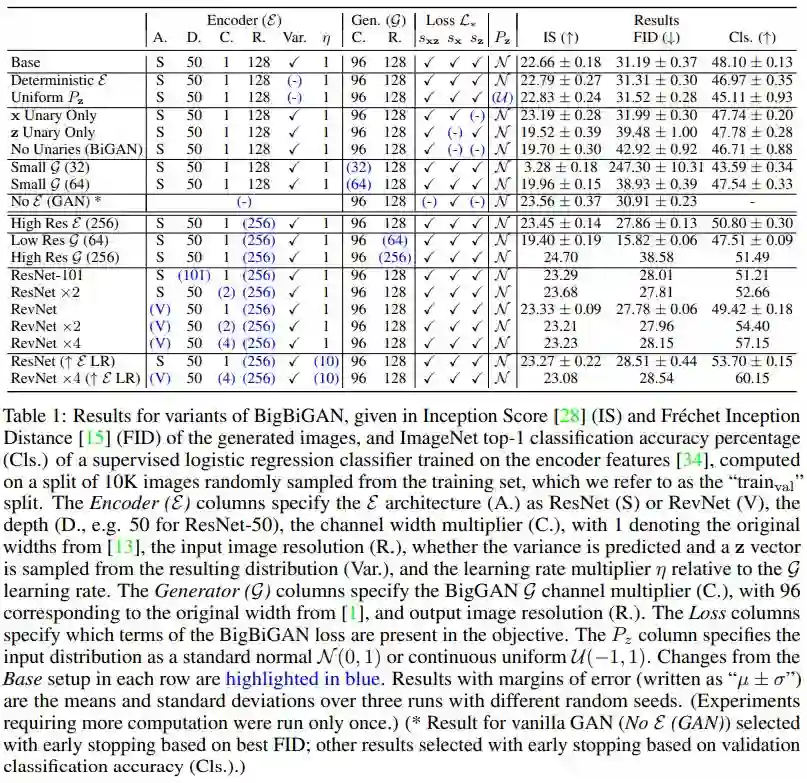
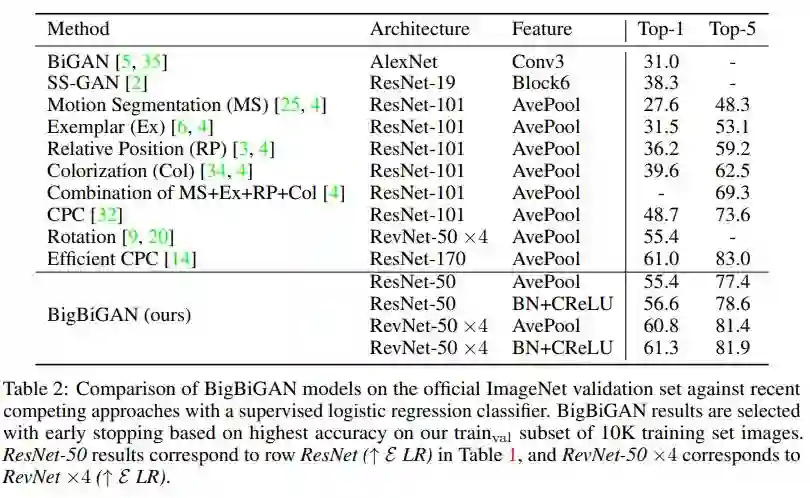
2. Large Scale Adversarial Representation Learning

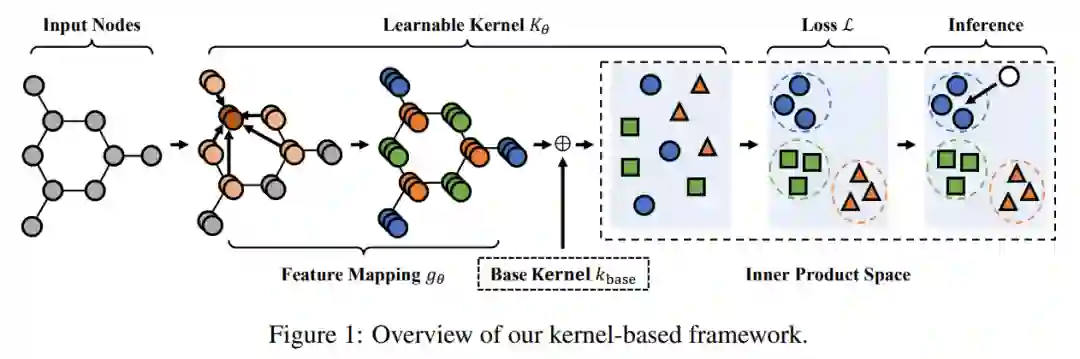
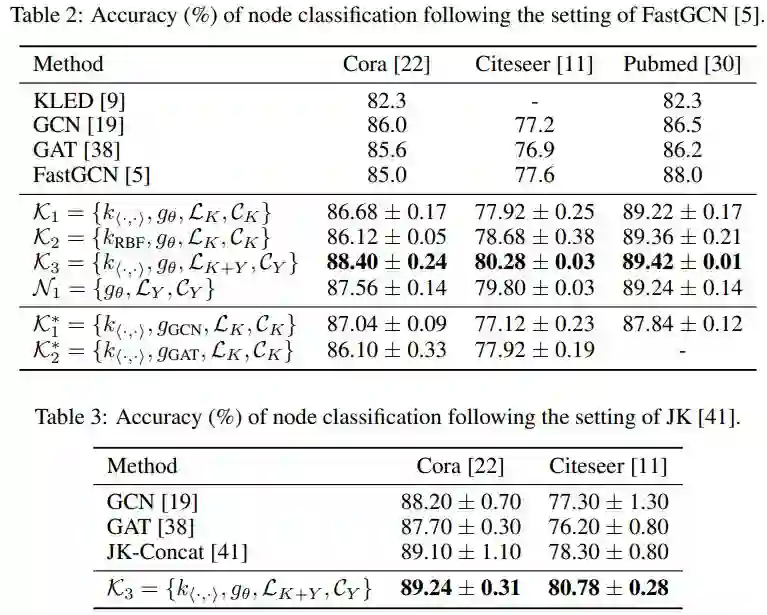
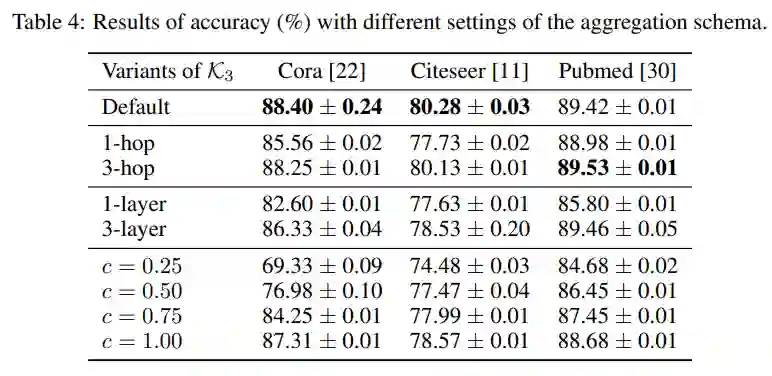
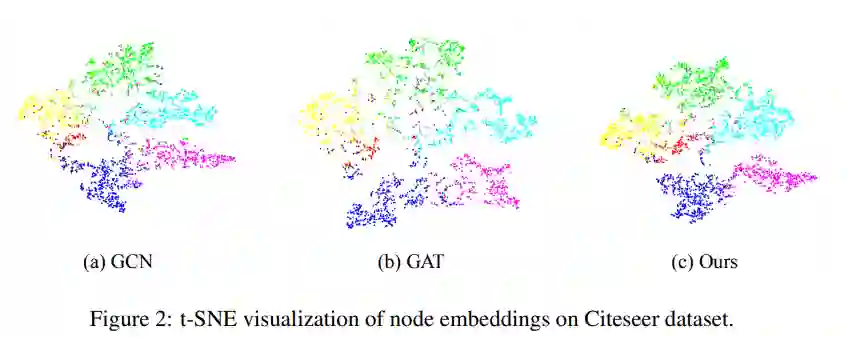
3. Rethinking Kernel Methods for Node Representation Learning on Graphs
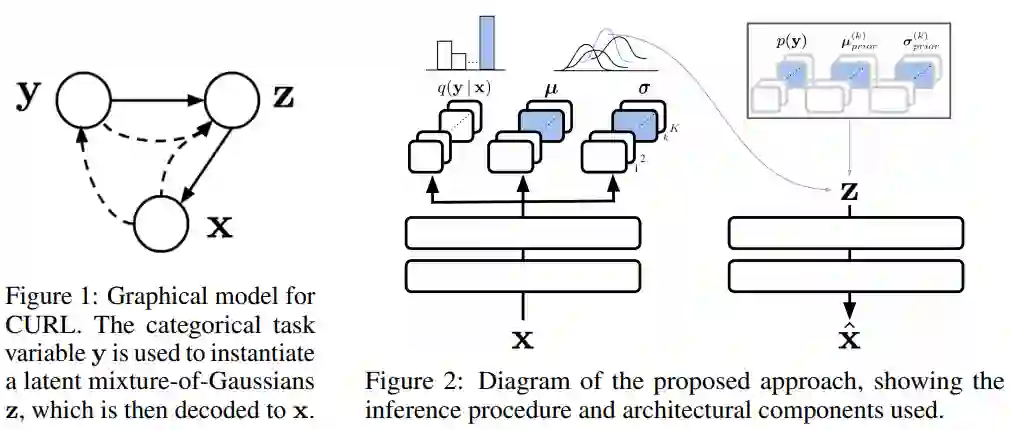
4. Continual Unsupervised Representation Learning
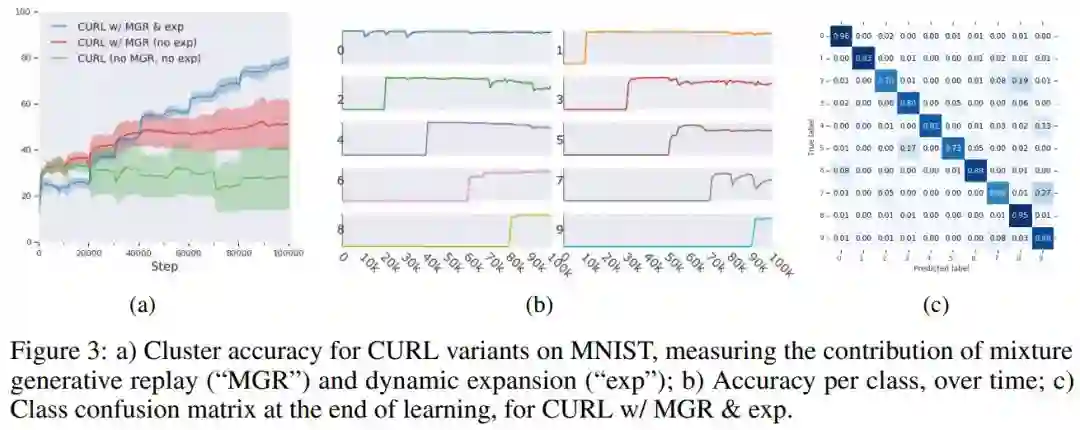
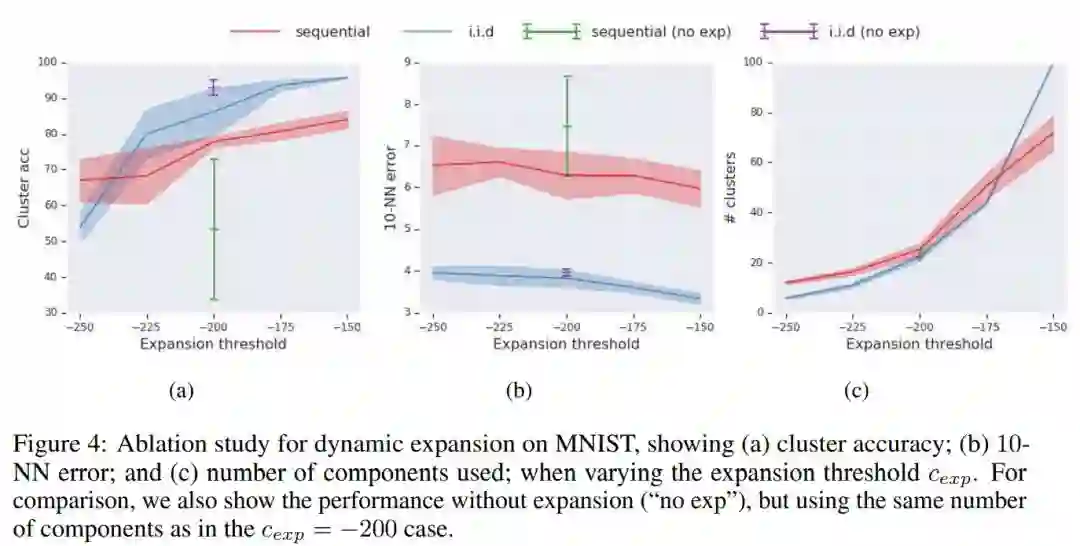
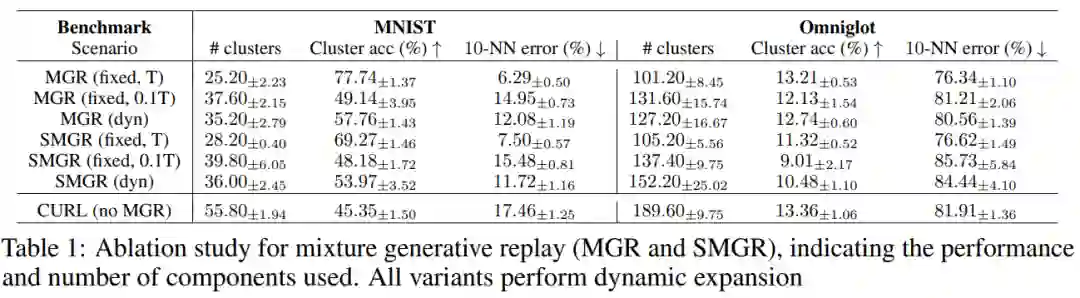
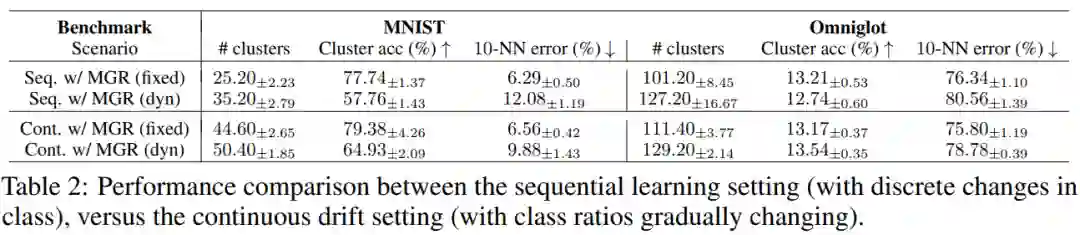
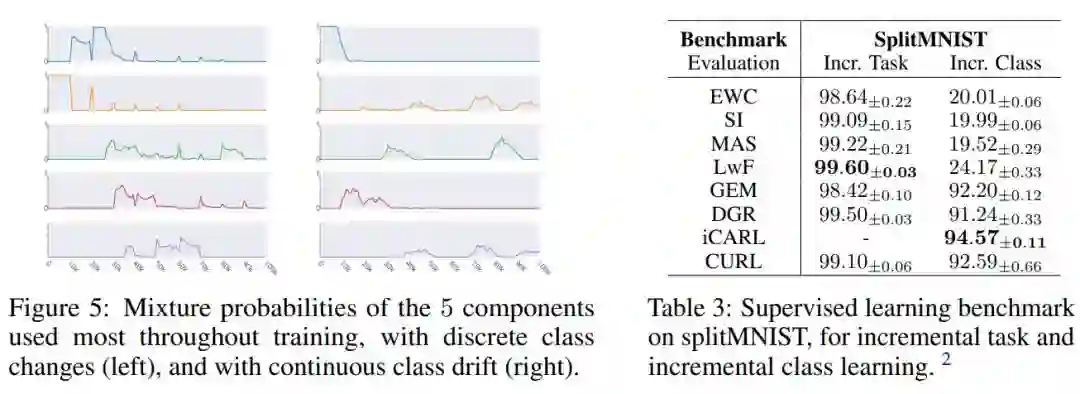 论文链接:
论文链接:
5. Unsupervised Scalable Representation Learning for Multivariate Time Series
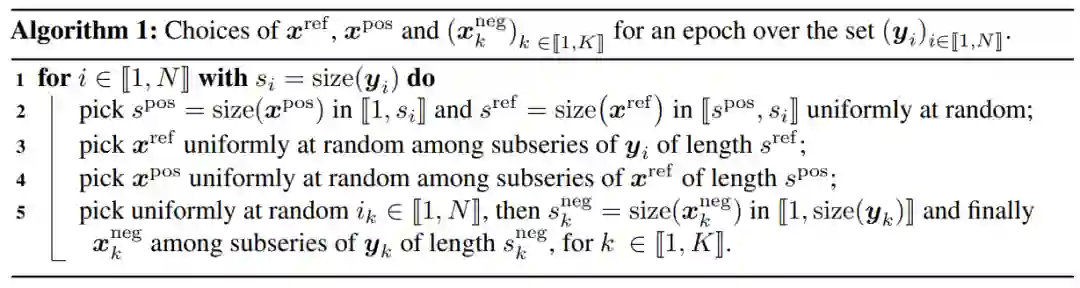
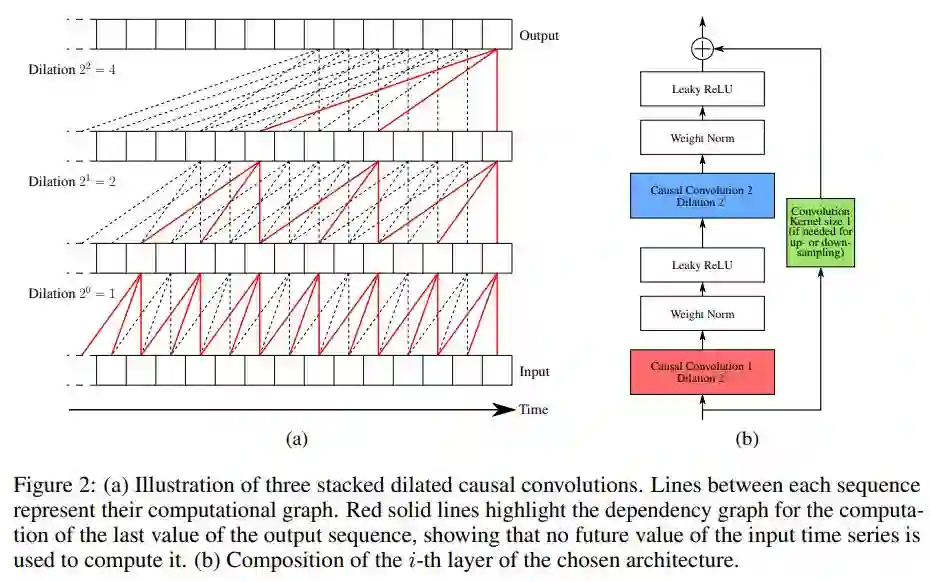
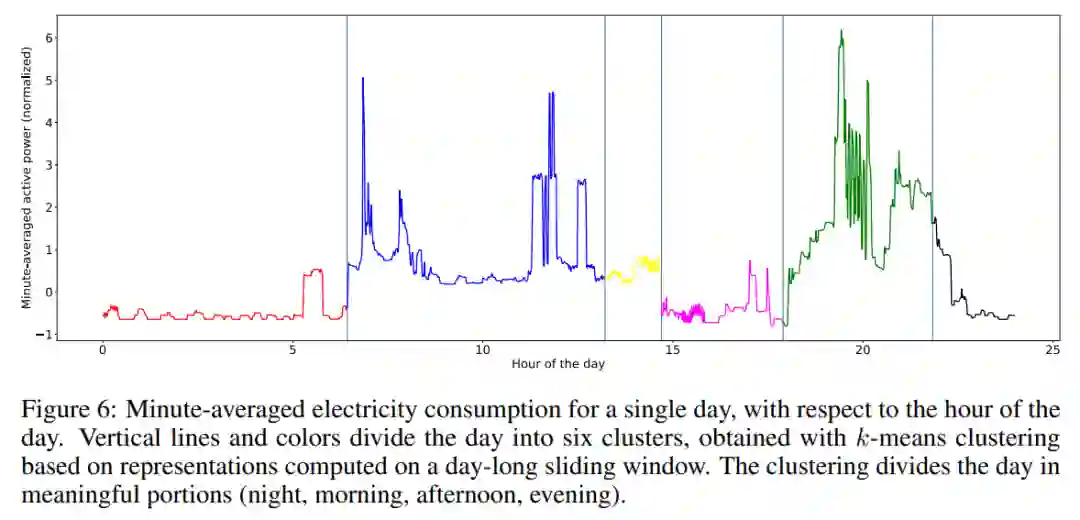
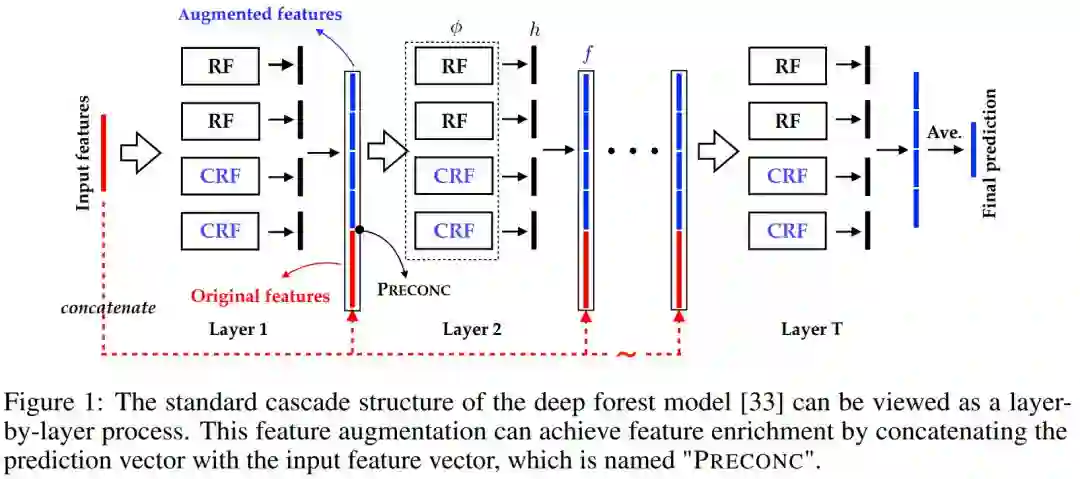
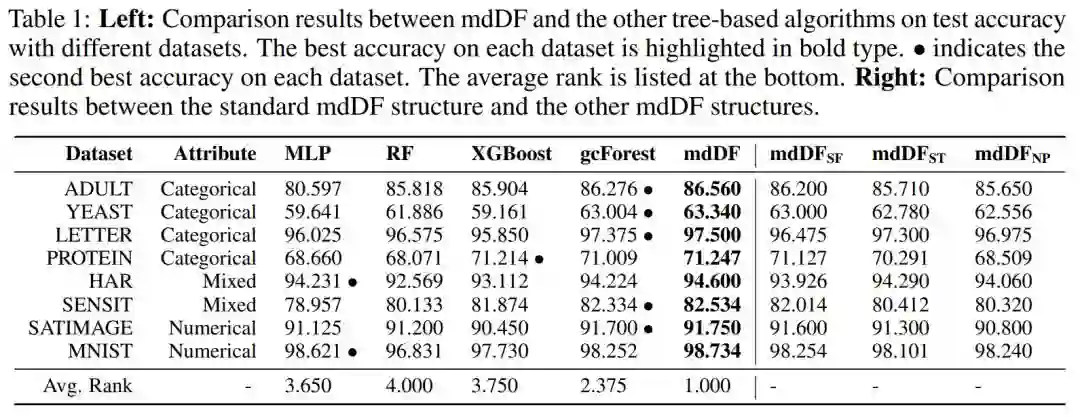
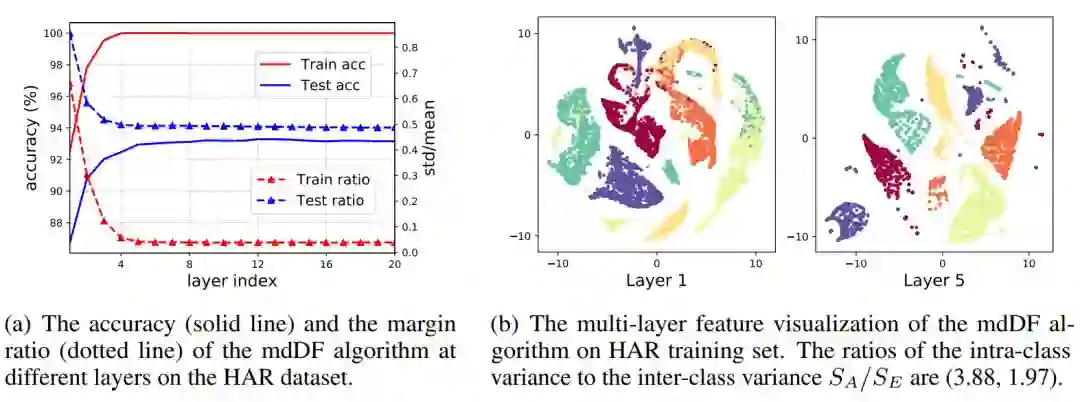
6. A Refined Margin Distribution Analysis for Forest Representation Learning

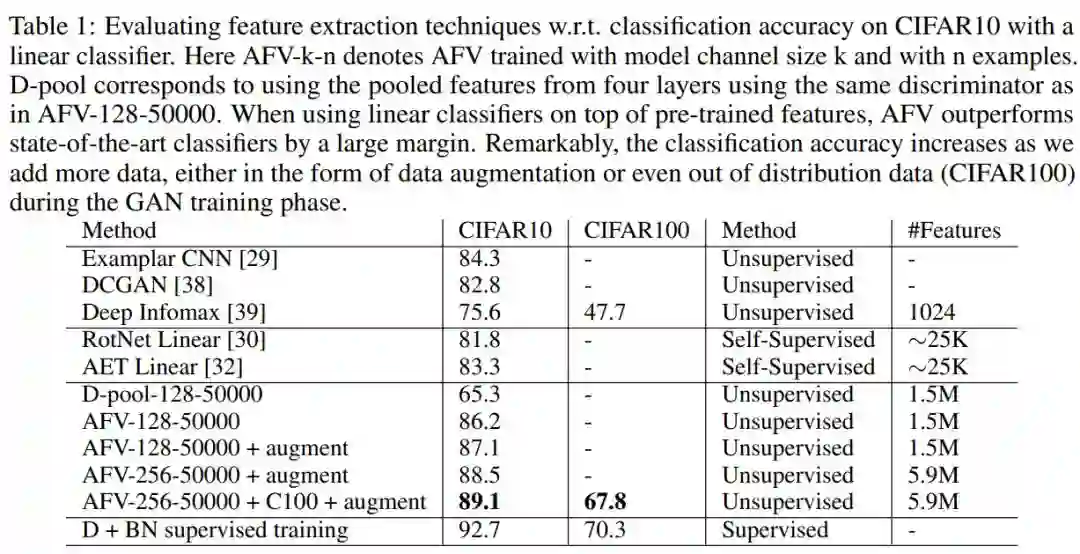
7. Adversarial Fisher Vectors for Unsupervised Representation Learning

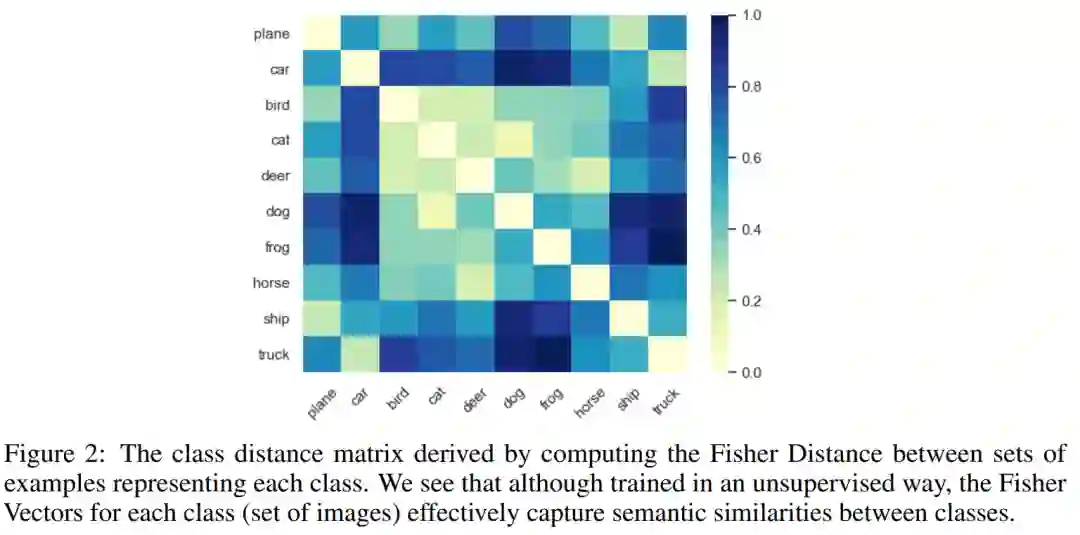
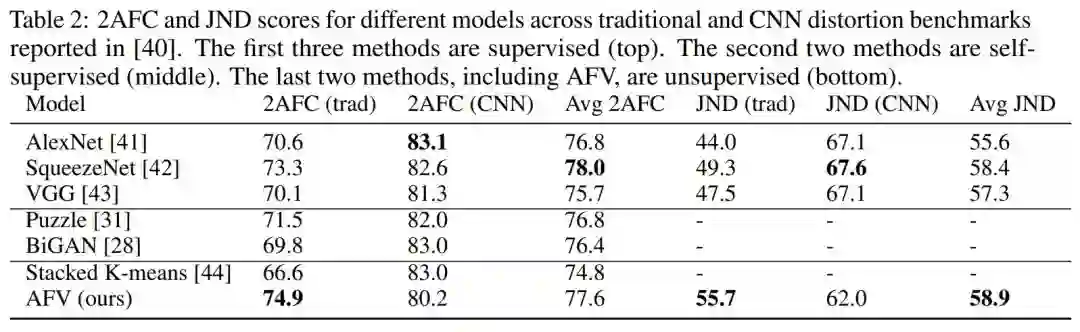
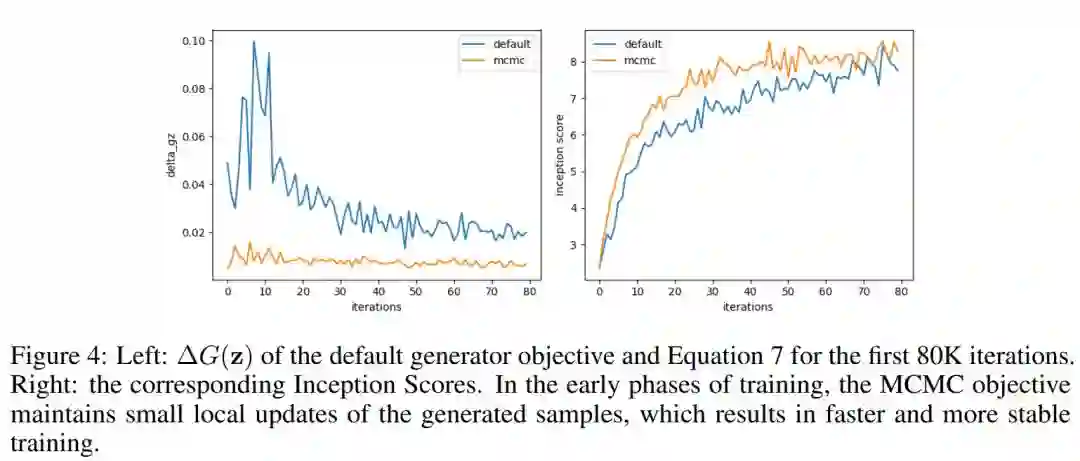
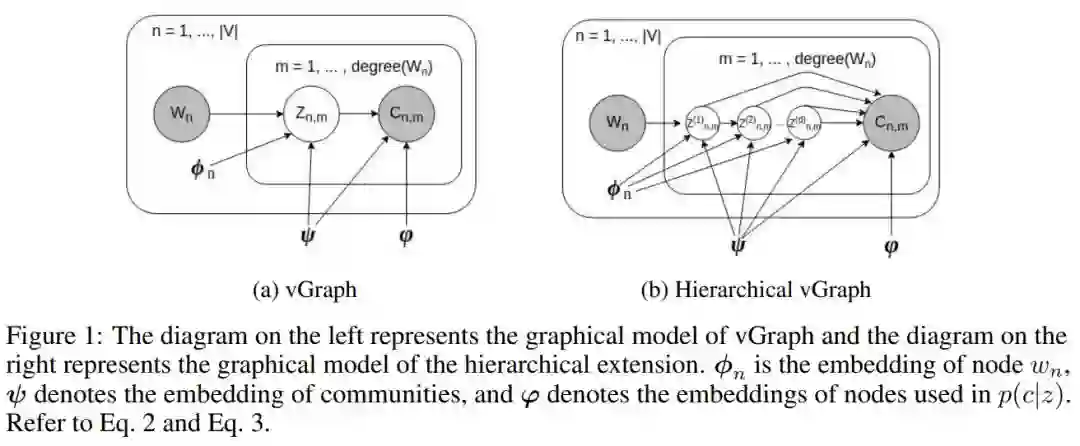
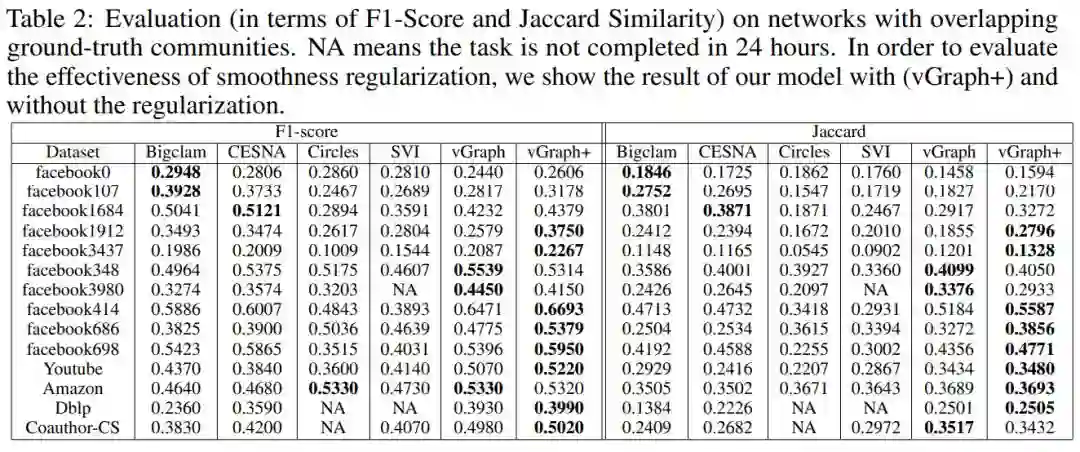
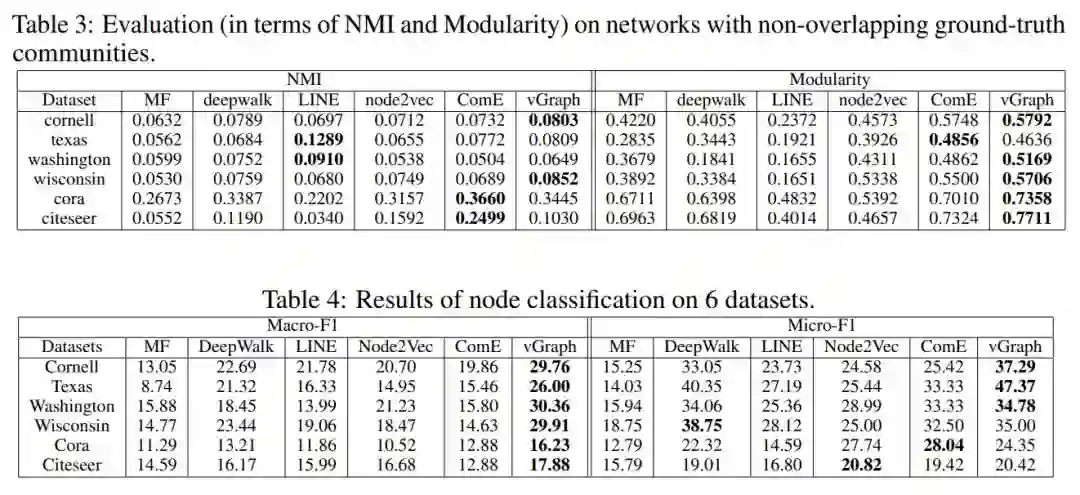
8. vGraph: A Generative Model for Joint Community Detection and Node Representation Learning

便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RLNP” 就可以获取8篇《表示学习》论文下载链接索引~


登录查看更多
相关内容

表示学习是通过利用训练数据来学习得到向量表示,这可以克服人工方法的局限性。 表示学习通常可分为两大类,无监督和有监督表示学习。大多数无监督表示学习方法利用自动编码器(如去噪自动编码器和稀疏自动编码器等)中的隐变量作为表示。 目前出现的变分自动编码器能够更好的容忍噪声和异常值。 然而,推断给定数据的潜在结构几乎是不可能的。 目前有一些近似推断的策略。 此外,一些无监督表示学习方法旨在近似某种特定的相似性度量。提出了一种无监督的相似性保持表示学习框架,该框架使用矩阵分解来保持成对的DTW相似性。 通过学习保持DTW的shaplets,即在转换后的空间中的欧式距离近似原始数据的真实DTW距离。有监督表示学习方法可以利用数据的标签信息,更好地捕获数据的语义结构。 孪生网络和三元组网络是目前两种比较流行的模型,它们的目标是最大化类别之间的距离并最小化了类别内部的距离。
专知会员服务
42+阅读 · 2020年4月11日
专知会员服务
74+阅读 · 2019年11月20日




相关VIP内容
专知会员服务
42+阅读 · 2020年4月11日
专知会员服务
74+阅读 · 2019年11月20日
相关资讯
相关论文