Linguistically Regularized LSTMs for Sentiment Classification

文章来源知乎专栏:西土城的搬砖日常
原文链接:https://zhuanlan.zhihu.com/p/23906487
《Linguistically Regularized LSTMs for Sentiment Classification》阅读笔记
作者:Qiao Qian , Minlie Huang , Jinhao Lei , Xiaoyan Zhu
出处:arXiv 2017
论文相关领域:情感分析
主要工作:通过改变损失函数的方式,把语言学规则(情感词典,否定词和程度副词)融入到现有的句子级LSTM情感分类模型中。
一、相关工作
1、情感分类的神经网络模型
近年来,出现了很多解决情感分类问题的神经网络模型,主要有:
通过递归编码建立句子的语义表示,输入文本通常是树结构的,具体工作可参考:
[Socher et al. 2011] Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions
[Socher et al. 2013] Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
[Dong et al. 2014] Adaptive Multi-Compositionality for Recursive Neural Models with Applications to Sentiment Analysis
[Qian et al. 2015] Learning Tag Embeddings and Tag-specific Composition Functions in Recursive Neural Network
通过CNN建立句子的语义表示,输入是文本序列,具体工作可参考:
[Kim 2014] Convolutional Neural Networks for Sentence Classification
[Kalchbrenner, Grefenstette, and Blunsom 2014] A Convolutional Neural Network for Modelling Sentences
通过LSTM模型建立句子的语义表示,可以用在文本序列的建模上,也可以是树结构的输入,具体工作可参考:
[Zhu, Sobhani, and Guo 2015] Long Short-Term Memory Over Tree Structures
[Tai, Socher, and Manning 2015] Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks
2、情感分析任务的语言学知识
语言学知识对情感分析任务至关重要,主要包括情感词典、否定词(如not、nerer、neither等等)、程度副词(如very、extremely等)。
情感词典(sentiment lexicon)
情感词典(英文)应用比较广泛的有Hu and Liu2004年提出的情感词典和MPQA词典,详细介绍可分别参考以下两篇文章:
[Hu and Liu 2004] Mining and Summarizing Customer Reviews
[Wilson, Wiebe, and Hoffmann 2005] Recognizing Contextual Polarity in Phrase-Level Sentiment Analysis
否定词(negation)
否定词在情感分析中也是一个关键元素,它会改变文本表达的情感倾向。有很多相关研究:
[Polanyi and Zaenen 2006] Contextual Valence Shifters
[Taboada et al. 2011] Lexicon-Based Methods for Sentiment Analysis
[Zhu et al. 2014] An Empirical Study on the Effect of Negation Words on Sentiment
[Kiritchenko and Mohammad 2016] Sentiment Composition of Words with Opposing Polarities
其中,
文章1:对否定词的处理是将含有否定词的文本的情感倾向反转;
文章2:由于不同的否定表达以不同的方式不同程度影响着句子的情感倾向,文中提出否定词按照某个常量值的程度改变着文本的情感倾向;
文章3: 将否定词作为特征结合到神经网络模型中;
文章4: 将否定词和其他语言学知识与SVM结合在一起,分析文本情感倾向。
程度副词 (intensity words)
程度副词影响文本的情感强度,在细粒度情感中非常关键,相关研究可参考:
[Taboada et al. 2011] Lexicon-Based Methods for Sentiment Analysis
[Wei, Wu, and Lin 2011] A regression approach to affective rating of chinese words from anew
[Malandrakis et al. 2013] Distributional semantic models for affective text analysis
[Wang, Zhang, and Lan 2016] Ecnu at semeval-2016 task 7: An enhanced supervised learning method for lexicon sentiment intensity ranking
其中,
文章1:直接让程度副词通过一个固定值来改变情感强度;
文章2:利用线性回归模型来预测词语的情感强度值;
文章3:通过核函数结合语义信息预测情感强度得分;
文章4:提出一种learning-to-rank模型预测情感强度得分。
二、本文提出的模型(Linguistically Regularized LSTM)
Linguistically Regularized LSTM是把语言学规则(包括情感词典、否定词和程度副词)以约束的形式和LSTM结合起来。作者定义了四种规则来将语言学知识结合进来,每一个规则主要是考虑当前词和它相邻位置词的情感分布来定义的。
1、Non-Sentiment Regularizer(NSR)
NSR的基本想法是,如果相邻的两个词都是non-opinion(不表达意见)的词,那么这两个词的情感分布应该是比较相近的。
将这种想法结合到模型中,有如下定义:
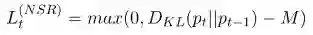
其中M是边界参数,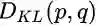
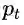
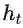
关于KL散度:
KL散度是用来衡量两个函数或者分布之间的差异性的一个指标,其原始定义式如下:

两个分布的差异越大,KL散度值越大;两个分布的差异越小,KL散度值越小;当两个分布相同时,KL散度值为0。
这里所用的对称KL散度定义如下:
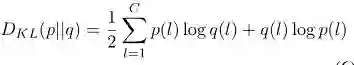
所以我们可以看到,当相邻的两个词分布较近,KL散度小于M时,NSR的值为0;随着两个词的分布差异增大时,NSR值变大。
2、Sentiment Regularizer(SR)
SR的基本想法是,如果当前词是情感词典中的词,那么它的情感分布应该和前一个词以及后一个词有明显不同。
例如:This movie is interesting. 在位置t=4处的词“interesting”是一个表达正向情感的词,所以在t=4处的情感分布应该比t=3处要positive得多。这个叫做sentiment drift(情感漂流)。
为了将这种想法结合到模型中,作者提出一个极性漂流分布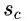
SR定义如下:
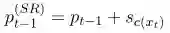

所以我们可以看到,当前词t是情感词典中的词的时候,前一个位置t-1的情感分布加上漂流分布之后,如果与位置t的分布相近的话,SR值为0,随着其分布差异的增大,SR值增大。
3、Negation Regularizer(NR)
否定词通常会反转文本的情感倾向(从正向变为负向,或者是从负向变为正向),但是具体情况是跟否定词本身和它所否定的对象有关的。
例如:“not good”和“not bad”中,“not”的角色并不一样,前者是将正向情感转为负向情感,后者是将负向情感转为正向情感。
对否定词的处理,本文是这样做的:针对每一个否定词,提出一个转化矩阵


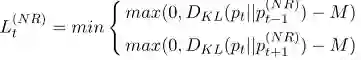
我们可以看到,如果在当前词是否定词的情况下,如果它的前一个词或者后一个词与当前词的分布较近,那么NR的值比较小。
4、Intensity Regularizer(IR)
程度副词改变文本的情感强度(比如从positive变为very positive),这种表达对细粒度情感分析很重要。
程度副词对于情感倾向的改变和否定词很像,只是改变的程度不同,这里也是通过一个转化矩阵来定义IR的。如果当前词是程度副词的话,那么它的前一个词或者后一个词,经过转化矩阵之后得到的分布,应该与当前词的分布比较接近。
5、将上述规则结合到LSTM模型中
定义一个新的损失函数将上述规则结合到模型中,
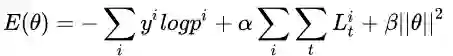
其中,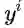


模型训练的目标是最小化损失函数,让样本的实际分布与预测分布尽可能接近的同时,让模型符合上述四种规则。
三、实验
1、数据
本文实验用了两个数据集来验证模型性能,
Movie Reviews,包括negative和positive两类;
Stanford Sentiment Treebank,包括very negative,negative,neural,positive,very positive五个类别。
两个数据集的具体统计信息如下图所示,
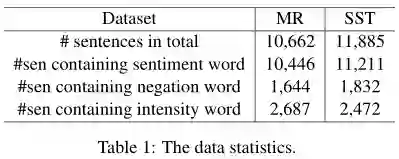
2、实验结果

从实验结果可以看出,
LR-LSTM和BI-LSTM与标准LSTM相比都有较大提升;
LR-BI-LSTM在句子级标注数据上的结果与BI-LSTM在短语级标注数据上的结果基本持平,通过引入LR,可以减少标注成本,并得到差不多的结果;
本文的LR-LSTM和LR-BI-LSTM和Tree-LSTM的结果基本持平,但是本文的模型更简单,效率更高,同时省去了短语级的标注工作。
3、不同规则的效果分析
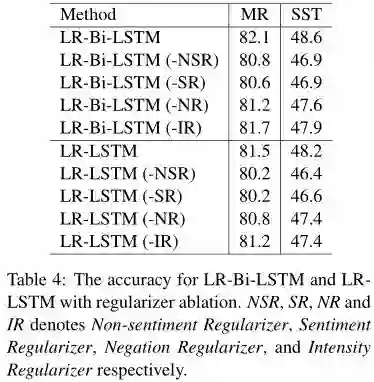
从实验结果可以看出,NSR和SR对提升模型性能最重要,NR和IR对模型性能提升重要性没有那么强,可能是因为在测试数据中只有14%的句子中含有否定词,只有23%的句子含有程度副词。
为了进一步研究NR和IR的作用,作者在又分别在仅包含否定词的子数据集(Neg.Sub)和仅包含程度副词的子数据集(Int.Sub)上做了对比实验,实验结果如下图,
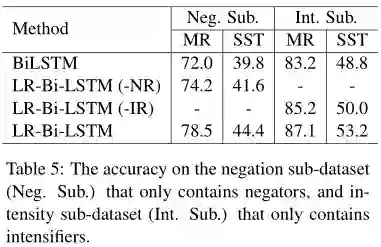
从实验结果可以看出,
在这些子数据集上,LR-Bi-LSTM的性能优于Bi-LSTM;
去掉NR或者IR的约束,在MR和SST两个数据集上模型性能都有明显下降。
四、总结
这篇文章通过损失函数将语言学规则引入现有的句子级情感分析的LSTM模型。在没有增大模型复杂度的情况下,有效的利用情感词典、否定词和程度副词的信息,在实验数据集上取得了较好效果。随着深度学习的发展,人们慢慢忽略了宝贵的经典自然语言资源,如何有效将这部分知识有效地融入到深度学习模型中是一个非常有意义的工作。
推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Highway Networks For Sentence Classification
 欢迎关注交流
欢迎关注交流



