Jointly Improving Summarization and Sentiment Classification

本文来自知乎专栏:西土城的搬砖日常
论文题目:
《A Hierarchical End-to-End Model for Jointly Improving Text Summarization and Sentiment Classification》
abstract: 本文旨在联合训练文本摘要和情感分类两个任务,其想法在于,他认为情感分类是一种更抽象的“摘要”,所以,本文在摘要输出层上加上了一个情感分类层,进一步抽取情感信息。本文为生成式摘要任务,情感分类为五分类。
model:
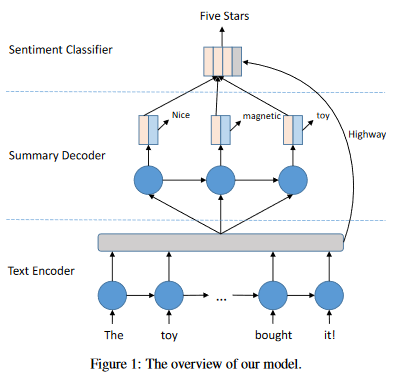
本文所用的模型很简单,基本都是基于state-of-the-art结构。其模型如图
首先定义符号:
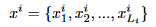
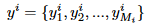
x为原始输入文本, y为输出的摘要文本,并且定义 l为情感标签。
下面分层介绍模型:
Text Encoder: 利用目前最优的序列编码模型Bi-LSTM,公式如下:
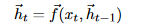
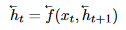
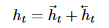
Summary Decoder: 分为三个部分:
1. uni-directional LSTM
2. multi-view attention mechanism
3.word generator
1. uni-directional LSTM: 经典S2S decoder:
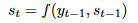
其中,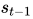
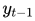
2. multi-view attention mechanism:由于该模型为联合任务,而情感分类和文本摘要对于文本的抽取是应该有区别的,比如,情感分类专注于情感性强的词,文本摘要专注于关键性强的词。所以对encode的信息需要进行权重加权。
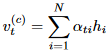
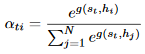
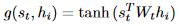
上面的公式是针对于文本摘要,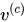
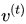
3. word generator: softmax layer
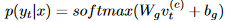
Summary-Aware Sentiment Classifier: 本文利用两部分信息,decode输出的情感分类向量与encode的context向量。
并利用softmax输出标签概率。
Joint Loss Function:
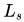
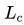
Experiment:
dataset: Amazon SNAP Review Dataset (SNAP):
-Toys & Games
-Sports & Outdoors
-Movie & TV
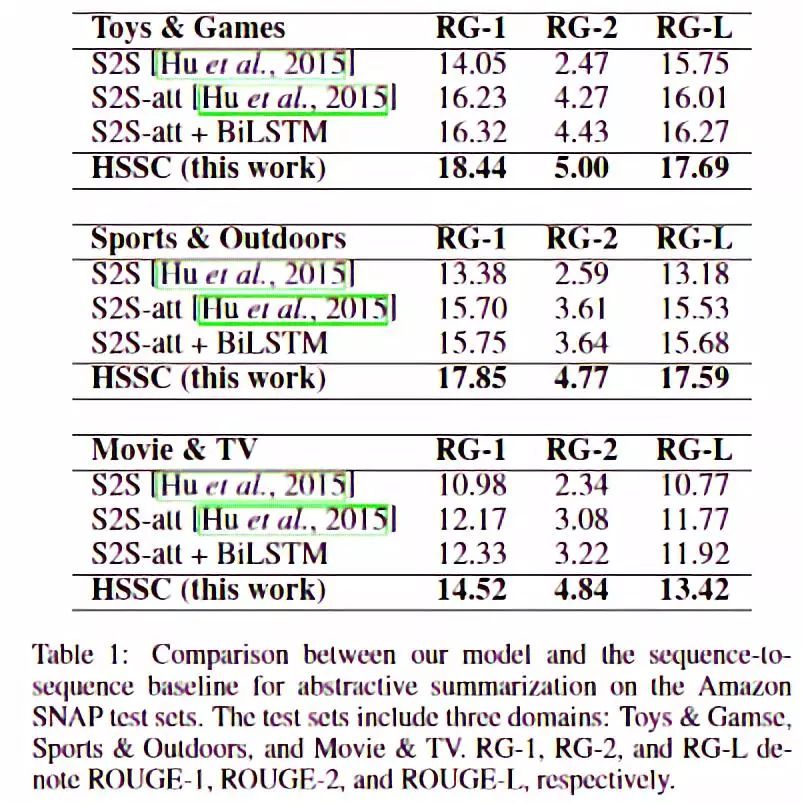
文本摘要的三个指标都有提升。
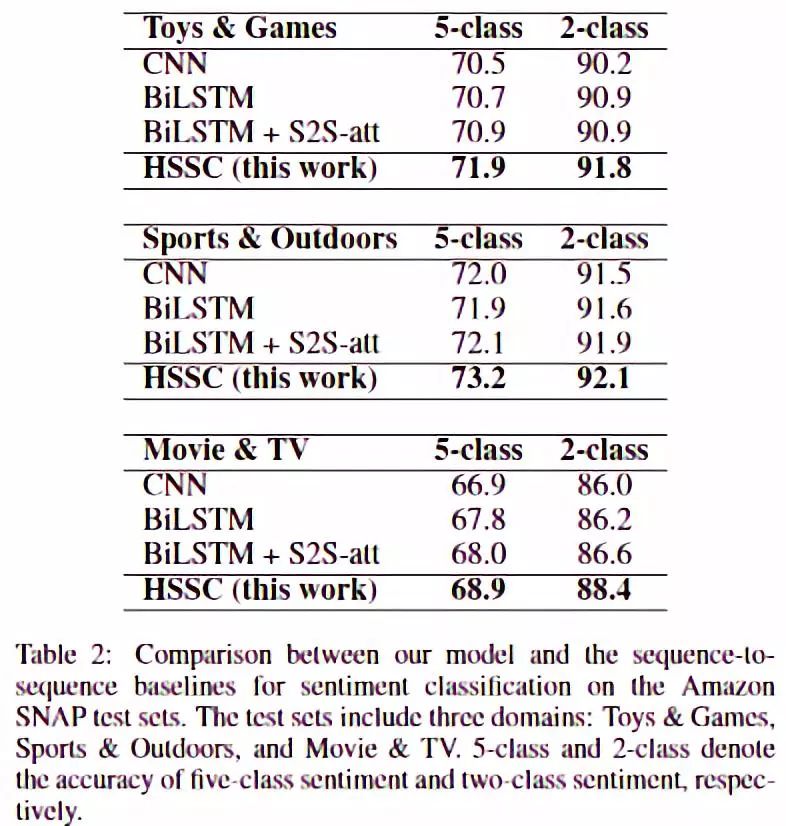
情感分类的结果显示也有一定的提升,效果不明显。
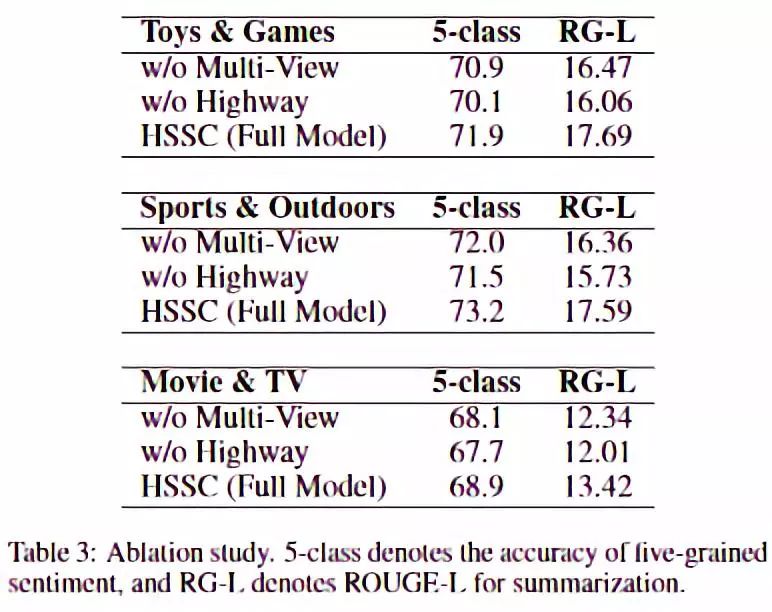
特征消融实验结果如图,其实比较奇怪的结果,highway重要性比attention的高,这证明了其实在encode阶段对sentiment classification的监督信号要更重要,因为文本摘要和情感分类的区别太大。当然在decode阶段的attention也是有效的。

attention weight distribution如图,可以直观的看到两个任务的注意力是不同的。
Conclusion: 本文的想法很直观,也符合联合任务的一贯做法,即启发式学习及更强的监督信号。并且实验结果也证明了文本摘要和情感分类确实有相关性,并且联合训练可以寻找到双方的更优解。在结果的解释性上有更大的优势。


推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流