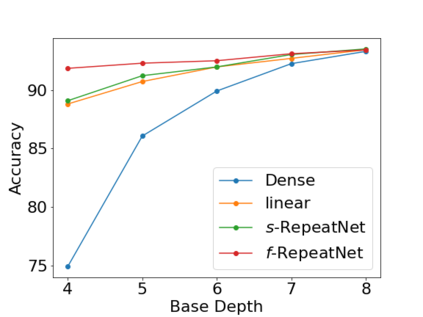
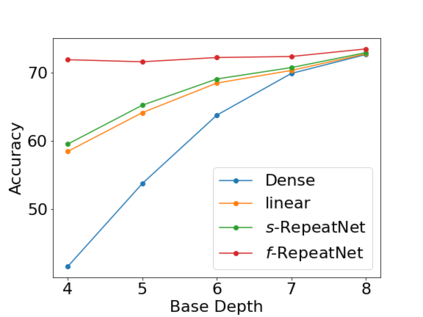
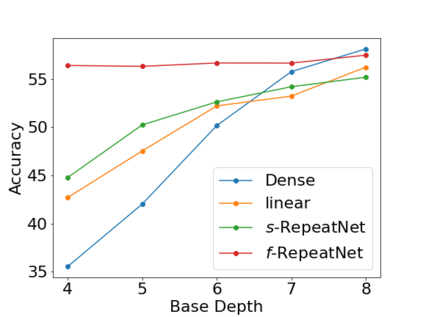
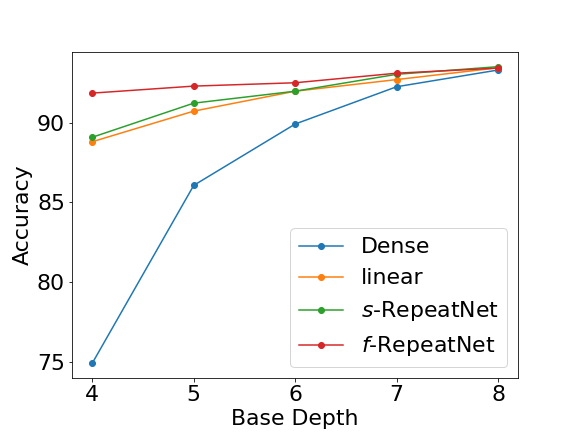
Deeper and wider CNNs are known to provide improved performance for deep learning tasks. However, most such networks have poor performance gain per parameter increase. In this paper, we investigate whether the gain observed in deeper models is purely due to the addition of more optimization parameters or whether the physical size of the network as well plays a role. Further, we present a novel rescaling strategy for CNNs based on learnable repetition of its parameters. Based on this strategy, we rescale CNNs without changing their parameter count, and show that learnable sharing of weights itself can provide significant boost in the performance of any given model without changing its parameter count. We show that small base networks when rescaled, can provide performance comparable to deeper networks with as low as 6% of optimization parameters of the deeper one. The relevance of weight sharing is further highlighted through the example of group-equivariant CNNs. We show that the significant improvements obtained with group-equivariant CNNs over the regular CNNs on classification problems are only partly due to the added equivariance property, and part of it comes from the learnable repetition of network weights. For rot-MNIST dataset, we show that up to 40% of the relative gain reported by state-of-the-art methods for rotation equivariance could actually be due to just the learnt repetition of weights.
翻译:深层和广度的CNN已知能为深层学习任务提供更好的业绩。 然而, 大部分这类网络的每个参数的增益都差。 在本文中, 我们调查深层模型中观察到的增益是否纯粹因为增加了更多优化参数, 或网络的物理大小也发挥了一定的作用。 此外, 我们为CNN提出了一个基于可学习的重复参数的新颖的调整战略。 基于这一战略, 我们重新提升CNN的比重, 不改变参数计数, 并显示可以学习的分量本身可以大大提升任何特定模型的性能, 而不会改变参数的计数。 我们显示, 重力的小型基础网络在重新标度时, 能够提供与深度网络的低至6%优化参数的更深网络相近的性能。 权重共享的相关性通过群体- QNCNN( CNN) 实例进一步得到进一步强调。 我们显示,在常规CNNCN( CNN) 的分类问题中, 群体- 变异性CNNNNNCN(S) 所取得的重大改进只能部分是由于增加了变异性属性,, 而部分是由于网络重度的特性的特性的特性的特性的特性, 部分来自网络重度的可学习重重度的重度的重度的重度的重度的重度的重度的重度的重度的重度。