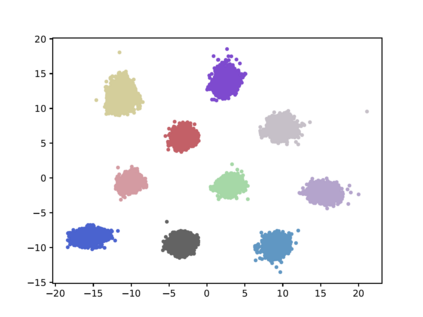
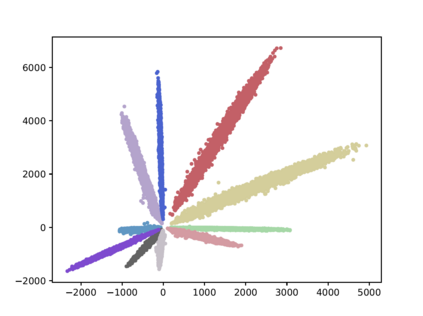
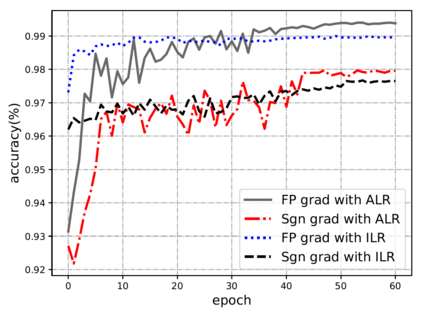
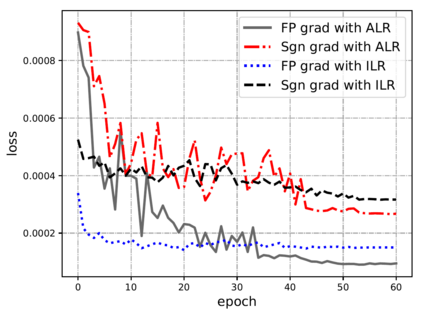
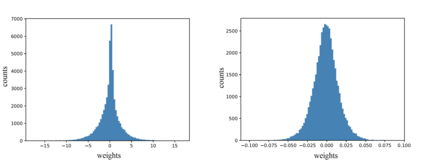
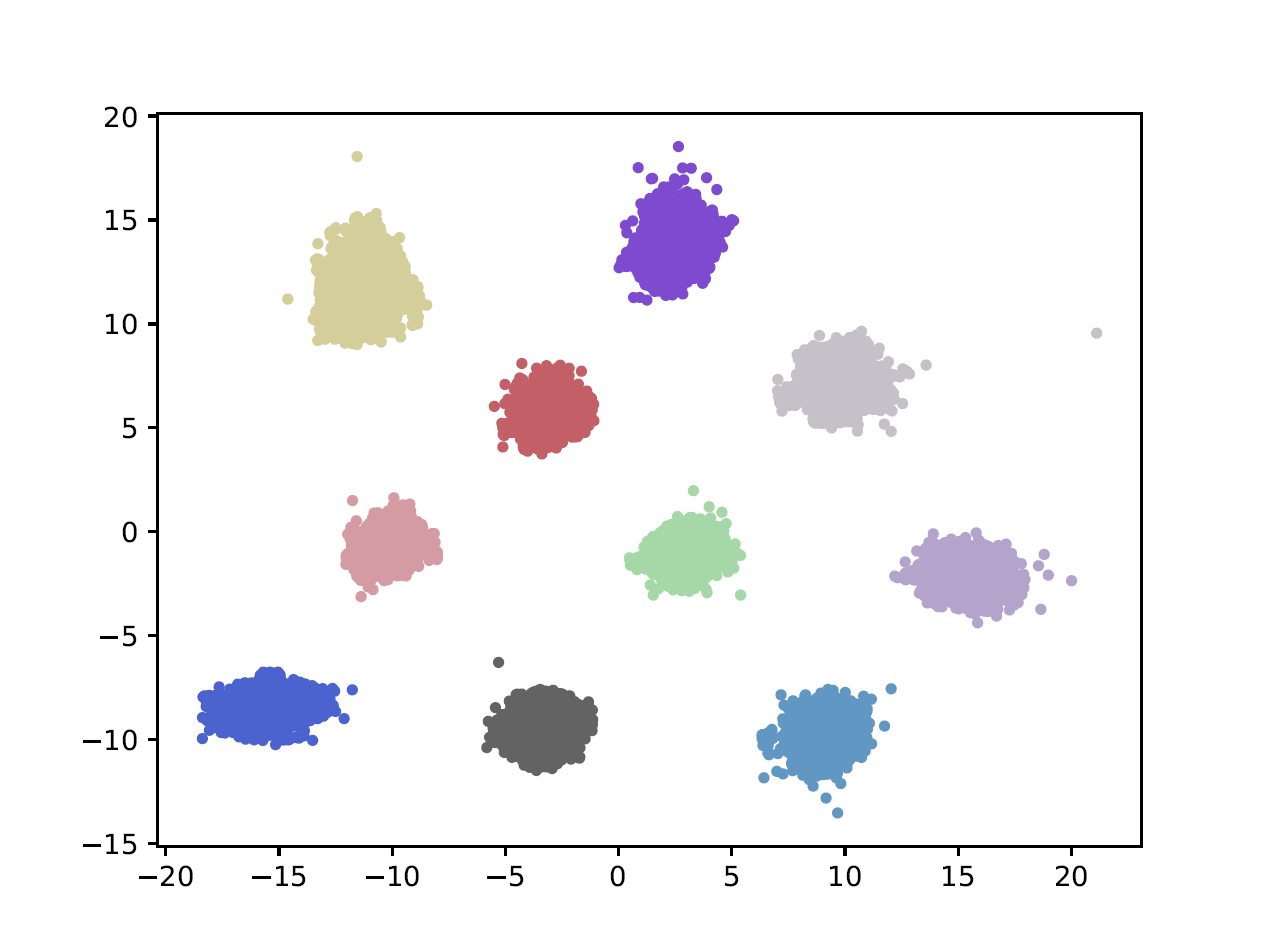
Compared with cheap addition operation, multiplication operation is of much higher computation complexity. The widely-used convolutions in deep neural networks are exactly cross-correlation to measure the similarity between input feature and convolution filters, which involves massive multiplications between float values. In this paper, we present adder networks (AdderNets) to trade these massive multiplications in deep neural networks, especially convolutional neural networks (CNNs), for much cheaper additions to reduce computation costs. In AdderNets, we take the $\ell_1$-norm distance between filters and input feature as the output response. The influence of this new similarity measure on the optimization of neural network have been thoroughly analyzed. To achieve a better performance, we develop a special back-propagation approach for AdderNets by investigating the full-precision gradient. We then propose an adaptive learning rate strategy to enhance the training procedure of AdderNets according to the magnitude of each neuron's gradient. As a result, the proposed AdderNets can achieve 74.9% Top-1 accuracy 91.7% Top-5 accuracy using ResNet-50 on the ImageNet dataset without any multiplication in convolution layer.
翻译:与廉价的附加操作相比, 倍增操作的计算复杂程度要高得多。 深神经网络中广泛使用的变异是精确的交叉关系, 以测量输入特性和变动过滤器之间的相似性, 其中包括浮点值之间的巨大乘法。 在本文中, 我们展示加热网络( AdderNets), 将这些巨大的倍增用于深神经网络, 特别是进化神经网络( CNNs ), 以更廉价的增量来降低计算成本。 在 AdderNets 中, 我们将过滤器和输入特性之间的$@ $_ 1 $- 诺姆距离作为输出响应。 已经对这一新相似度测量神经网络优化的影响进行了彻底分析。 为了取得更好的性能, 我们为AdderNets开发了一种特殊的反向调整方法, 通过调查全精度梯度梯度, 特别是进化神经网络( CNNs), 我们然后提出一个适应性学习率战略, 以根据每个神经梯度的大小来增强AdderNet的培训程序。 作为结果, 拟议的AdderNet 可以在不实现74.9% 顶- 1- 1%- 顶- 5- 顶级 顶部- 5 的图像- 精确度- 5 Restregiplational/ vicilentalational/ 任何图像- SS- 10/ 任何 。