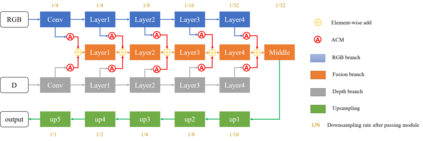
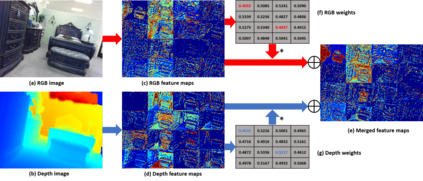
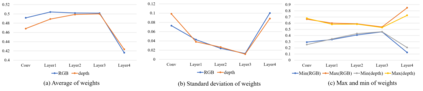
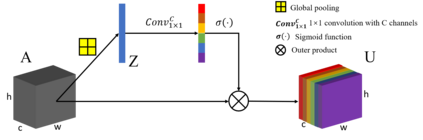Compared to RGB semantic segmentation, RGBD semantic segmentation can achieve better performance by taking depth information into consideration. However, it is still problematic for contemporary segmenters to effectively exploit RGBD information since the feature distributions of RGB and depth (D) images vary significantly in different scenes. In this paper, we propose an Attention Complementary Network (ACNet) that selectively gathers features from RGB and depth branches. The main contributions lie in the Attention Complementary Module (ACM) and the architecture with three parallel branches. More precisely, ACM is a channel attention-based module that extracts weighted features from RGB and depth branches. The architecture preserves the inference of the original RGB and depth branches, and enables the fusion branch at the same time. Based on the above structures, ACNet is capable of exploiting more high-quality features from different channels. We evaluate our model on SUN-RGBD and NYUDv2 datasets, and prove that our model outperforms state-of-the-art methods. In particular, a mIoU score of 48.3\% on NYUDv2 test set is achieved with ResNet50. We will release our source code based on PyTorch and the trained segmentation model at https://github.com/anheidelonghu/ACNet.
翻译:与 RGB 语义区段相比, RGBD 语义区段可以通过考虑深度信息实现更好的绩效。然而,当代段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段,但当代段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段,因为RGB和深度图像段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段段,