【论文推荐】最新5篇目标检测相关论文——显著目标检测、弱监督One-Shot检测、多框检测器、携带物体检测、假彩色图像检测
【导读】专知内容组整理了最近目标检测相关文章,为大家进行介绍,欢迎查看!
1. MSDNN: Multi-Scale Deep Neural Network for Salient Object Detection(MSDNN: 基于多尺度深度神经网络的显著目标检测)
作者:Fen Xiao,Wenzheng Deng,Liangchan Peng,Chunhong Cao,Kai Hu,Xieping Gao
摘要:Salient object detection is a fundamental problem and has been received a great deal of attentions in computer vision. Recently deep learning model became a powerful tool for image feature extraction. In this paper, we propose a multi-scale deep neural network (MSDNN) for salient object detection. The proposed model first extracts global high-level features and context information over the whole source image with recurrent convolutional neural network (RCNN). Then several stacked deconvolutional layers are adopted to get the multi-scale feature representation and obtain a series of saliency maps. Finally, we investigate a fusion convolution module (FCM) to build a final pixel level saliency map. The proposed model is extensively evaluated on four salient object detection benchmark datasets. Results show that our deep model significantly outperforms other 12 state-of-the-art approaches.

期刊:arXiv, 2018年1月12日
网址:
http://www.zhuanzhi.ai/document/4e0a1be0e6121feadd4f2a0acec752aa
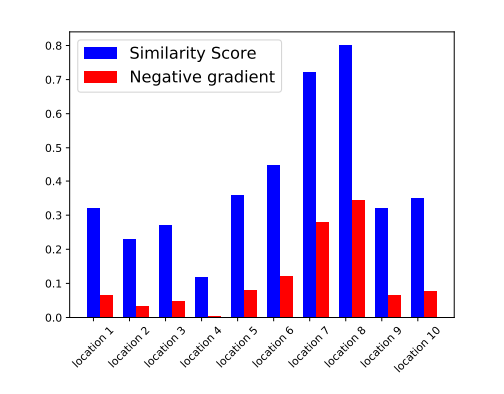
2. Weakly Supervised One-Shot Detection with Attention Siamese Networks(基于注意力机制的Siamese网络的弱监督One-Shot检测)
作者: Gil Keren,Maximilian Schmitt,Thomas Kehrenberg,Björn Schuller
摘要:We consider the task of weakly supervised one-shot detection. In this task, we attempt to perform a detection task over a set of unseen classes, when training only using weak binary labels that indicate the existence of a class instance in a given example. The model is conditioned on a single exemplar of an unseen class and a target example that may or may not contain an instance of the same class as the exemplar. A similarity map is computed by using a Siamese neural network to map the exemplar and regions of the target example to a latent representation space and then computing cosine similarity scores between representations. An attention mechanism weights different regions in the target example, and enables learning of the one-shot detection task using the weaker labels alone. The model can be applied to detection tasks from different domains, including computer vision object detection. We evaluate our attention Siamese networks on a one-shot detection task from the audio domain, where it detects audio keywords in spoken utterances. Our model considerably outperforms a baseline approach and yields a 42.6% average precision for detection across 10 unseen classes. Moreover, architectural developments from computer vision object detection models such as a region proposal network can be incorporated into the model architecture, and results show that performance is expected to improve by doing so.
期刊:arXiv, 2018年1月12日
网址:
http://www.zhuanzhi.ai/document/80f3bdfa4352eb512e0381b011eb0cc3
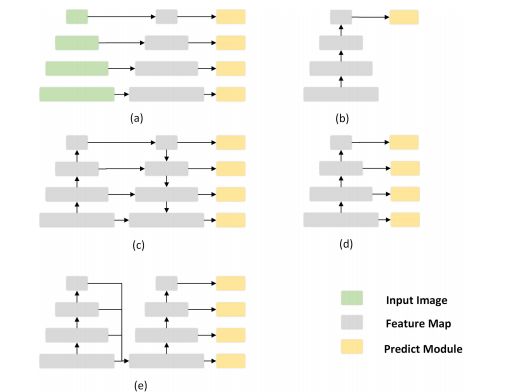
3. FSSD: Feature Fusion Single Shot Multibox Detector(FSSD: 基于特征融合和单次学习的多框检测器)
作者:Zuoxin Li,Fuqiang Zhou
摘要:SSD (Single Shot Multibox Detetor) is one of the best object detection algorithms with both high accuracy and fast speed. However, SSD's feature pyramid detection method makes it hard to fuse the features from different scales. In this paper, we proposed FSSD (Feature Fusion Single Shot Multibox Detector), an enhanced SSD with a novel and lightweight feature fusion module which can improve the performance significantly over SSD with just a little speed drop. In the feature fusion module, features from different layers with different scales are concatenated together, followed by some down-sampling blocks to generate new feature pyramid, which will be fed to multibox detectors to predict the final detection results. On the Pascal VOC 2007 test, our network can achieve 82.7 mAP (mean average precision) at the speed of 65.8 FPS (frame per second) with the input size 300$\times$300 using a single Nvidia 1080Ti GPU. In addition, our result on COCO is also better than the conventional SSD with a large margin. Our FSSD outperforms a lot of state-of-the-art object detection algorithms in both aspects of accuracy and speed. Code is available at https://github.com/lzx1413/CAFFE_SSD/tree/fssd.
期刊:arXiv, 2018年1月12日
网址:
http://www.zhuanzhi.ai/document/c36923f4e7fabe48f08c3cf8761353de
4. From Superpixel to Human Shape Modelling for Carried Object Detection(携带物体检测:从超像素到人体形状的建模方法)
作者:Farnoosh Ghadiri,Robert Bergevin,Guillaume-Alexandre Bilodeau
摘要:Detecting carried objects is one of the requirements for developing systems to reason about activities involving people and objects. We present an approach to detect carried objects from a single video frame with a novel method that incorporates features from multiple scales. Initially, a foreground mask in a video frame is segmented into multi-scale superpixels. Then the human-like regions in the segmented area are identified by matching a set of extracted features from superpixels against learned features in a codebook. A carried object probability map is generated using the complement of the matching probabilities of superpixels to human-like regions and background information. A group of superpixels with high carried object probability and strong edge support is then merged to obtain the shape of the carried object. We applied our method to two challenging datasets, and results show that our method is competitive with or better than the state-of-the-art.

期刊:arXiv, 2018年1月11日
网址:
http://www.zhuanzhi.ai/document/ba031e3396d77bcaa435ab62296aab7e
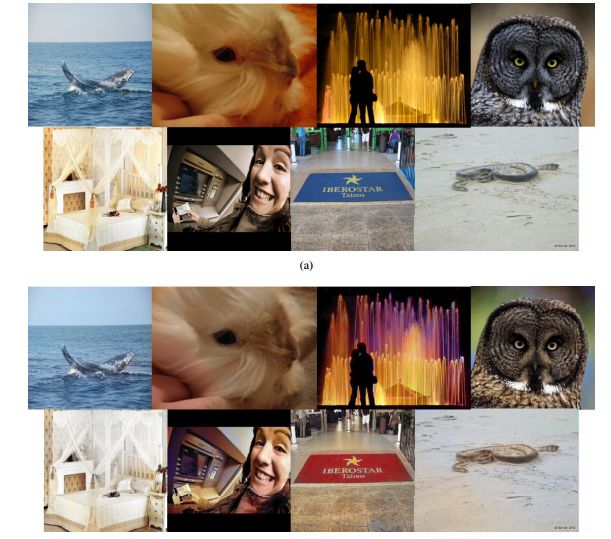
5. Fake Colorized Image Detection(假彩色图像检测)
作者:Yuanfang Guo,Xiaochun Cao,Wei Zhang,Rui Wang
摘要:Image forensics aims to detect the manipulation of digital images. Currently, splicing detection, copy-move detection and image retouching detection are drawing much attentions from researchers. However, image editing techniques develop with time goes by. One emerging image editing technique is colorization, which can colorize grayscale images with realistic colors. Unfortunately, this technique may also be intentionally applied to certain images to confound object recognition algorithms. To the best of our knowledge, no forensic technique has yet been invented to identify whether an image is colorized. We observed that, compared to natural images, colorized images, which are generated by three state-of-the-art methods, possess statistical differences for the hue and saturation channels. Besides, we also observe statistical inconsistencies in the dark and bright channels, because the colorization process will inevitably affect the dark and bright channel values. Based on our observations, i.e., potential traces in the hue, saturation, dark and bright channels, we propose two simple yet effective detection methods for fake colorized images: Histogram based Fake Colorized Image Detection (FCID-HIST) and Feature Encoding based Fake Colorized Image Detection (FCID-FE). Experimental results demonstrate that both proposed methods exhibit a decent performance against multiple state-of-the-art colorization approaches.
期刊:arXiv, 2018年1月14日
网址:
http://www.zhuanzhi.ai/document/7ba03632fa7f61fb8172f312de77552f
更多论文请上专知查看:PC登录 www.zhuanzhi.ai 点击论文查看
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知



