【简评】[CVPR2017]Loss Max-Pooling for Semantic Image Segmentation
这篇文章已经被CVPR2017收录,思想很明确,但是进行了很多数学证明,奈何数学功底不够啊,所以欢迎多多讨论交流。
论文地址:https://arxiv.org/abs/1704.02966
论文主要解决的是semantic segmentation中imbalanced training data distributions问题。在semantic segmentation数据集包括现实世界中存在明显的长尾分布的问题,即大多数的数据组成了小部分的类别,因此会导致学习器更偏向于这些类别。
现有方法
1.构建数据集时近似均匀地采样,保证每种类别分布较为均匀
这种方法在image-level上还比较方便操作,在semantic segmentation上难以保证
2.对minority classes进行上采样或者对majority classes进行下采样缺点:
会改变数据潜在分布
对数据不是最优利用(suboptimal exploitation),比如可能会丢掉一些majority classes的数据
增加计算成本和过拟合的风险,比如某些minority classes数据会被重复利用很多次
3.cost-sensitive learning
现在semantic segmentation datasets增加了更多的minority classes,这使得权重的划分更复杂
所以这篇文章提出了一种新的解决方法:Loss Max-Pooling
主要思想
1.通过pixel weighting functions自适应地对每个像素的contribution(实际展现的loss)进行re-weighting
引起更高loss的像素的权重更大,这直接对潜在的类内和类间不平衡进行了补偿
Focus on a family of weighting functions with bounded p-norm and
-norm
2.通过普通的max-pooling在pixel-loss level上对pixel weighting function取最大
3.而这个最大值是传统loss(即每个像素损失的权重是相等的)的上界
数学分析
Standard setting
语义分割任务中损失公式定义如下:
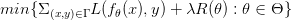
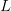
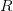
在普通semantic segmentation中,损失又可继续写成:
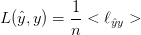
其中:
是每个像素的损失,
是定义的求和符号
可见每个像素损失的权重是均匀的,这将使学习器偏向于图像中的主要部分
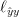

Loss Max-Pooling
文章设计了一个weighting function的convex, compact的空间,
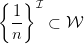
得到的损失函数如下:
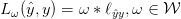
之后,文章定义了一个新的损失,即对不同weighting functions下的损失取最大:
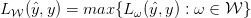
而这是文章中定义的所有损失函数的上界,包括传统的均匀加权的损失。文章提到这里的取最大值其实就是,max-pooling在pixel-loss level上的应用,所以这种方法才叫做 Loss Max-pooling。
Loss Max-Pooling的特性取决于空间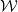
The space
of weighting functions
文章中关注的是由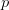
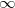
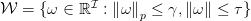
其中,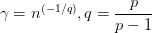

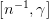
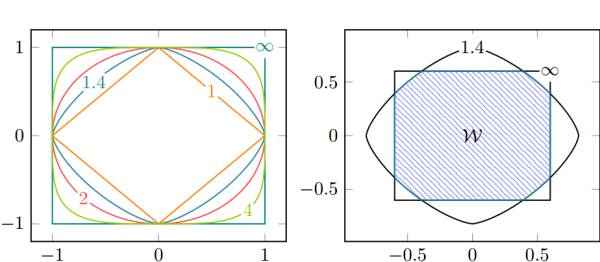
Left:二维情况下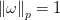
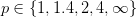
Right:当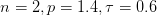
通过改变
一方面:
As
, the optimal weights will be in general concentrated around a single pixel
As
, the optimal weights will be uniformly spread across pixels
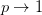
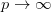
另一方面:
可以通过关系,
控制被optimal weighting function support的最小像素数(我的理解是,其实就是保证至少多少像素被赋予权重)
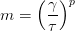
可以由下面两幅图来理解:
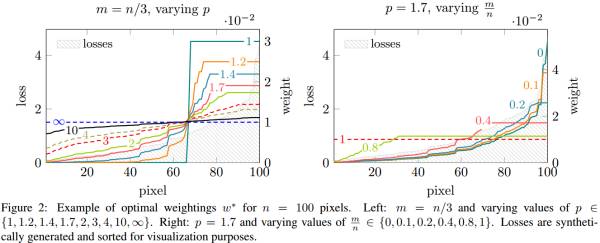
图中选取了100个像素,同时为了可视化对像素进行了排序。
由左图可以看到,当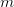
由右图可以看出,当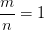

之后文章主要介绍了对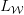

文中还提到了一个辅助的取样策略,综合考虑了均匀采样和模型性能。因为文中并未细说,同时也不是本文重点,所以在此不赘述了。
实验结果
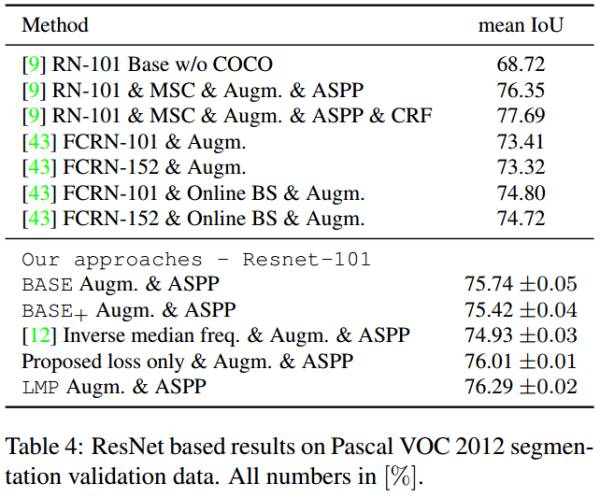
LMP是Loss Max-pooling+辅助取样策略的结果;Proposed loss only是不加辅助取样策略的结果;所有结果没有使用multi-scale input和CRF做进一步优化。
本文转自知乎,作者:ycszen 点击阅读原文查看原文。
相关文章
简评|Difficulty-aware Semantic Segmentation via Deep Layer Cascade





