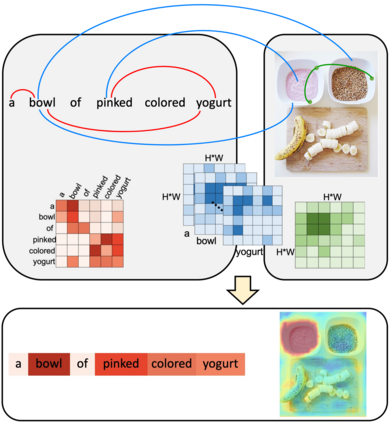
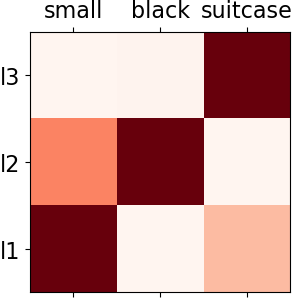
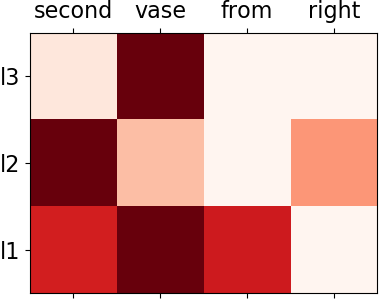
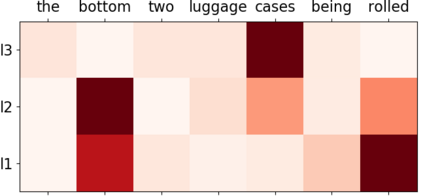
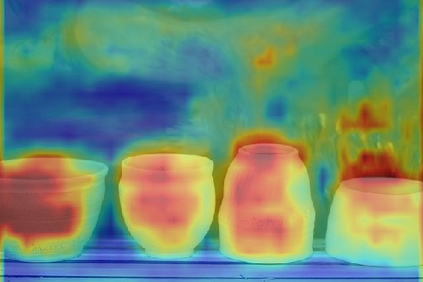
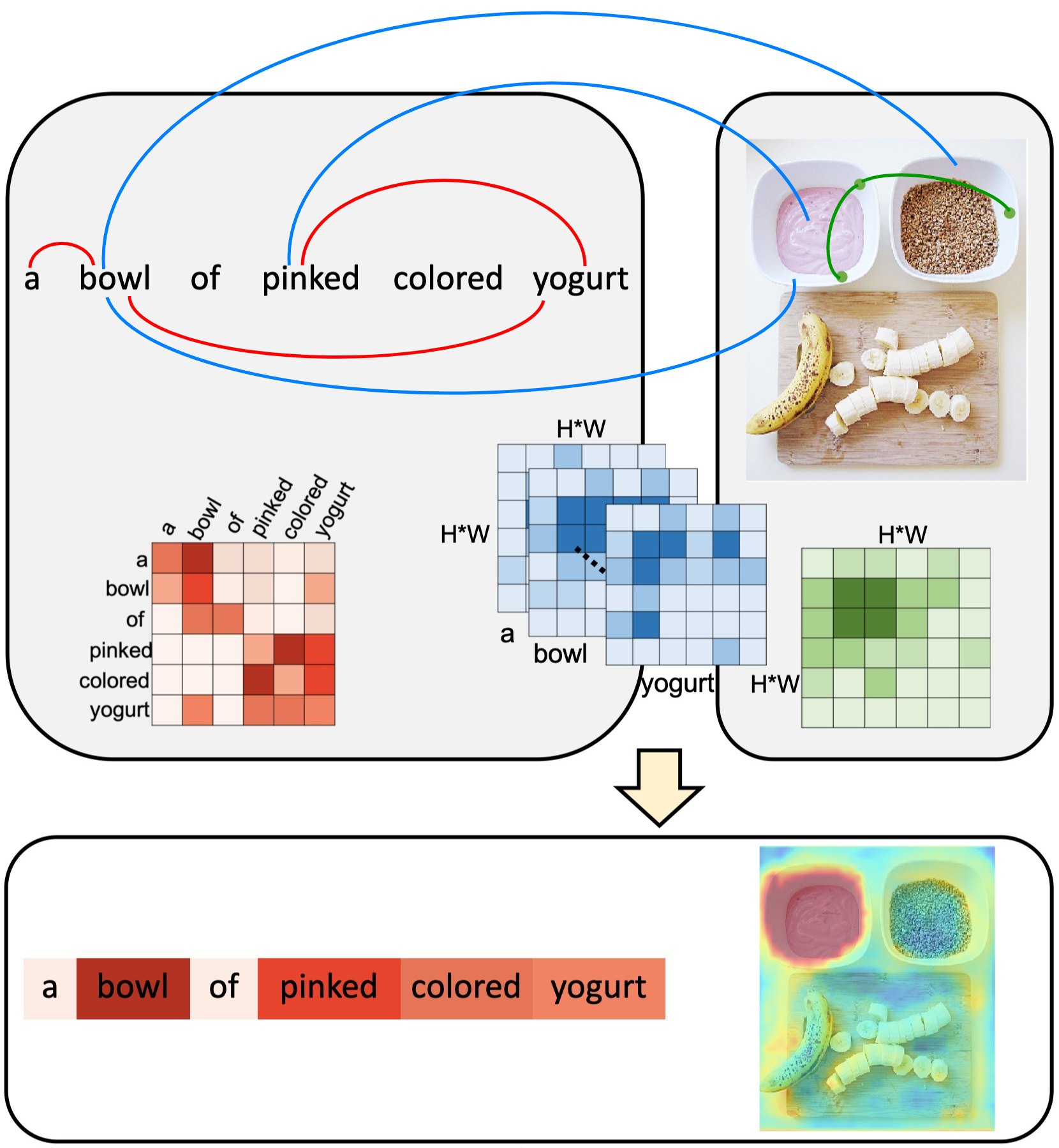
We consider the problem of referring image segmentation. Given an input image and a natural language expression, the goal is to segment the object referred by the language expression in the image. Existing works in this area treat the language expression and the input image separately in their representations. They do not sufficiently capture long-range correlations between these two modalities. In this paper, we propose a cross-modal self-attention (CMSA) module that effectively captures the long-range dependencies between linguistic and visual features. Our model can adaptively focus on informative words in the referring expression and important regions in the input image. In addition, we propose a gated multi-level fusion module to selectively integrate self-attentive cross-modal features corresponding to different levels in the image. This module controls the information flow of features at different levels. We validate the proposed approach on four evaluation datasets. Our proposed approach consistently outperforms existing state-of-the-art methods.
翻译:我们考虑的是图像分割的参考问题。根据输入图像和自然语言表达方式,我们的目标是分割图像中语言表达方式中提及的对象。这个领域的现有工作将语言表达方式和输入图像在表达方式中分开处理,它们没有足够地反映这两种模式之间的长期关联。我们在本文件中提议了一个跨模式的自我关注模块,以有效捕捉语言和视觉特征之间的长期依赖性。我们的模式可以适应性地侧重于引用表达方式和输入图像中重要区域中的信息化词汇。此外,我们提议了一个门式多级融合模块,有选择地整合与图像中不同级别相对应的自惯性跨模式特征。这个模块控制着不同层面的特征的信息流动。我们验证了四个评价数据集的拟议方法。我们提出的方法始终优于现有的最新方法。