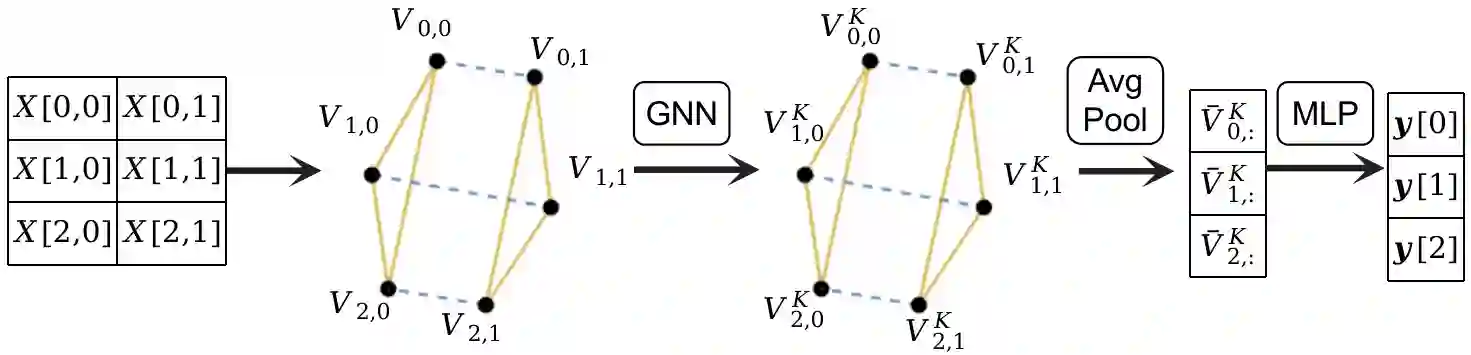
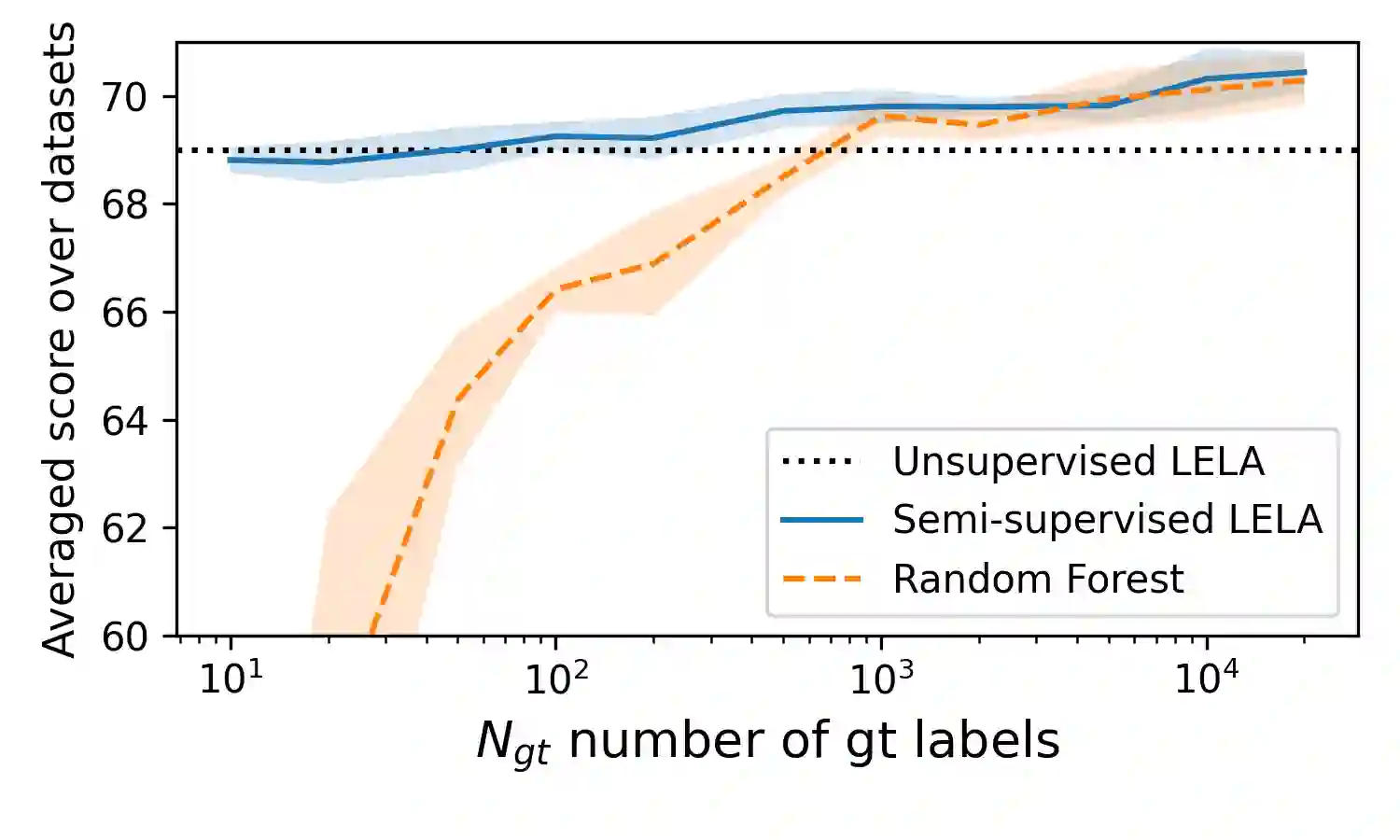
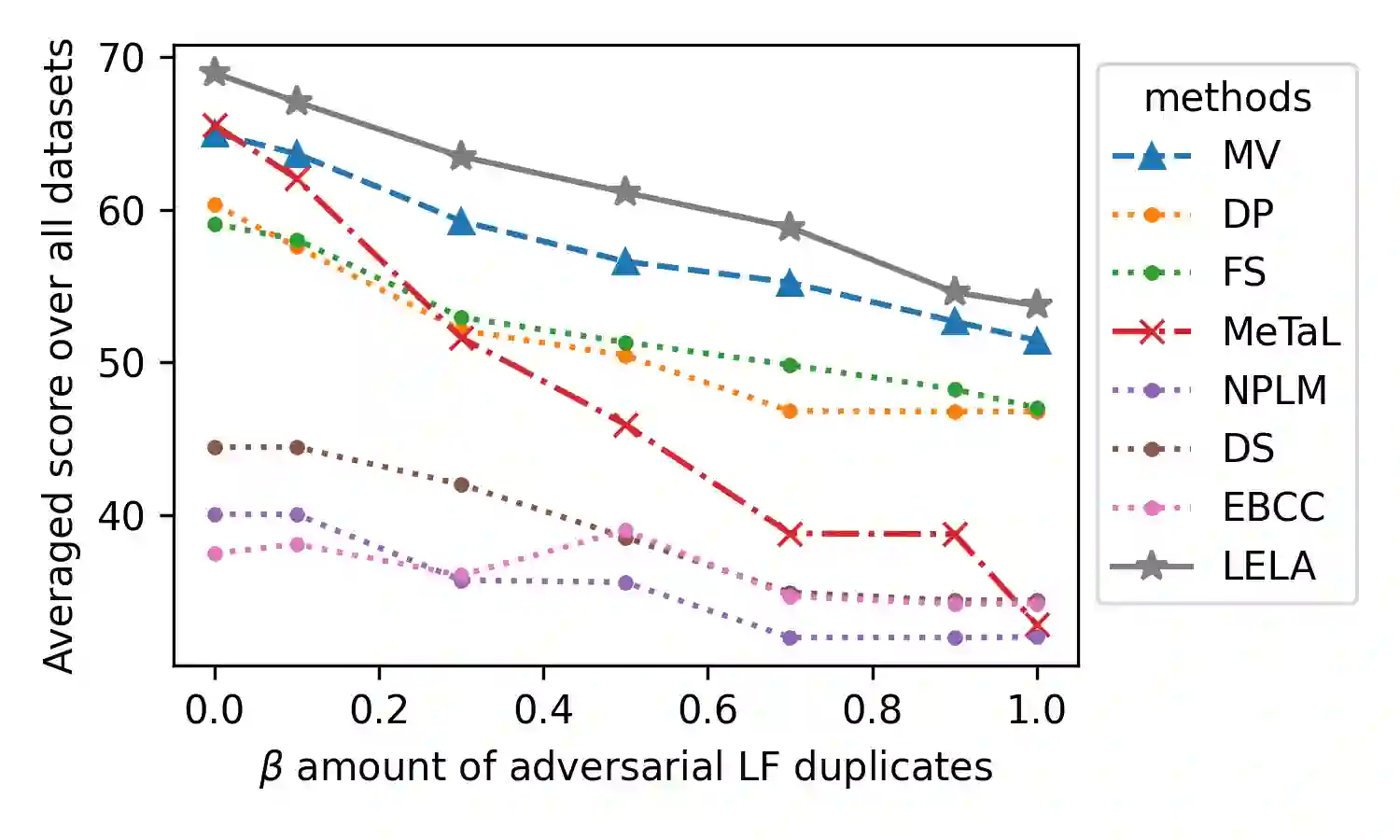
The lack of labeled training data is the bottleneck of machine learning in many applications. To resolve the bottleneck, one promising direction is the data programming approach that aggregates different sources of weak supervision signals to generate labeled data easily. Data programming encodes each weak supervision source with a labeling function (LF), a user-provided program that predicts noisy labels. The quality of the generated labels depends on a label aggregation model that aggregates all noisy labels from all LFs to infer the ground-truth labels. Existing label aggregation methods typically rely on various assumptions and are not robust across datasets, as we will show empirically. We for the first time provide an analytical label aggregation method that makes minimum assumption and is optimal in minimizing a certain form of the averaged prediction error. Since the complexity of the analytical form is exponential, we train a model that learns to be the analytical method. Once trained, the model can be used for any unseen datasets and the model predicts the ground-truth labels for each dataset in a single forward pass in linear time. We show the model can be trained using synthetically generated data and design an effective architecture for the model. On 14 real-world datasets, our model significantly outperforms the best existing methods in both accuracy (by 3.5 points on average) and efficiency (by six times on average).
翻译:缺少标签培训数据是许多应用程序中机器学习的瓶颈。 要解决瓶颈问题, 一个有希望的方向是数据编程方法, 整合不同来源的薄弱监督信号, 以容易生成标签数据。 数据编程将每个薄弱监督源编码为标签功能(LF), 这是一个用户提供的预测噪音标签的程序。 生成的标签的质量取决于一个标签汇总模型, 该模型将所有来自低频的吵杂标签汇总起来, 以推导地面真相标签。 现有的标签汇总方法通常依赖各种假设, 而不是可靠的跨数据集, 正如我们将用经验来显示的那样。 我们第一次提供了一种分析标签汇总方法, 以最小的假设形式, 并且最优化地将平均预测错误的某种形式最小化。 由于分析形式的复杂性是指数化的, 我们训练了一个模型, 学会成为分析方法。 一旦经过培训, 该模型可以用于任何看不见的数据集, 并且模型预测每个数据集在线性时间单个前通过的地面标签, 并且不可靠地显示。 我们第一次提供分析标签汇总方法, 。 在模型上, 可以大量地用现有平均数据设计模型 。