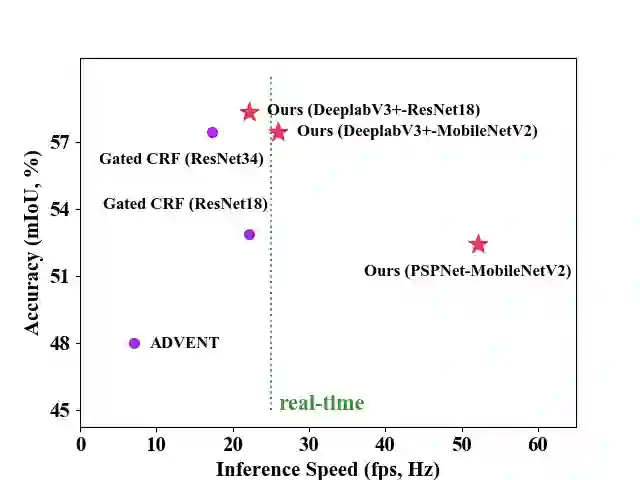
Compared with tedious per-pixel mask annotating, it is much easier to annotate data by clicks, which costs only several seconds for an image. However, applying clicks to learn video semantic segmentation model has not been explored before. In this work, we propose an effective weakly-supervised video semantic segmentation pipeline with click annotations, called WeClick, for saving laborious annotating effort by segmenting an instance of the semantic class with only a single click. Since detailed semantic information is not captured by clicks, directly training with click labels leads to poor segmentation predictions. To mitigate this problem, we design a novel memory flow knowledge distillation strategy to exploit temporal information (named memory flow) in abundant unlabeled video frames, by distilling the neighboring predictions to the target frame via estimated motion. Moreover, we adopt vanilla knowledge distillation for model compression. In this case, WeClick learns compact video semantic segmentation models with the low-cost click annotations during the training phase yet achieves real-time and accurate models during the inference period. Experimental results on Cityscapes and Camvid show that WeClick outperforms the state-of-the-art methods, increases performance by 10.24% mIoU than baseline, and achieves real-time execution.
翻译:与单击单击单击分解语义类样本,从而节省了艰苦的语义分解努力。 由于详细语义分解模式不是通过点击获取的, 直接通过点击标签进行的培训导致分解预测不准确。 但是, 应用点击来学习视频语义分解模式之前还没有被探索过。 在这项工作中, 我们提出一个有效的微弱监督的视频语义分解管道, 配有点击注释, 称为 WeClick, 以节省人工的语义分解努力。 由于详细语义信息不是通过点击获取的, 直接通过点击标签进行分解培训, 导致分解预测差。 然而, 为了缓解这一问题, 我们设计了一个新颖的记忆流知识蒸馏战略, 利用大量未加标签的视频框中的时间信息( 记忆流) 。 通过估计动作向目标框架提炼邻近的预测, 称为 WeClick, 我们采用范拉知识分解模式压缩。 在本案中, WeClick 学习精密的视频语义分解模型模型, 在培训阶段中, 而不是实时和精确的分解模型, 在测试中, 我们的模型将显示10进市的运行中, 显示的运行中, 显示10 直观的运行的模型, 。