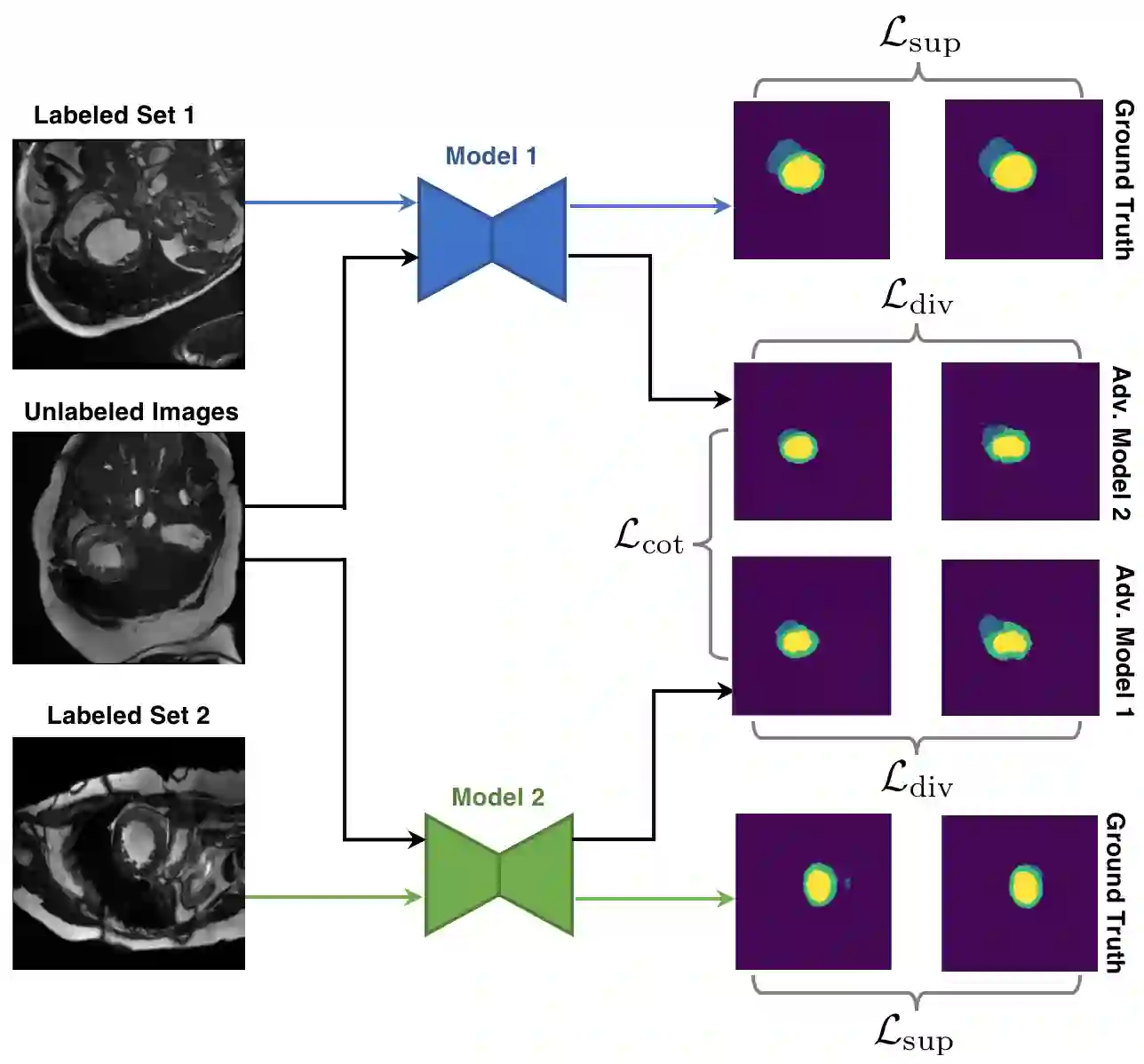
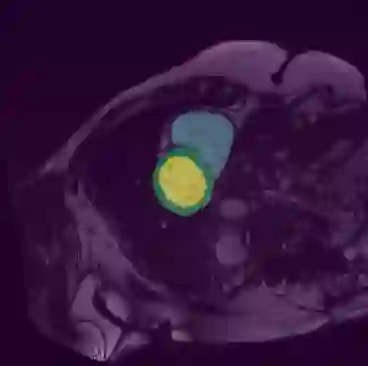
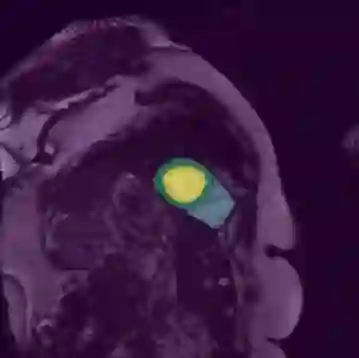
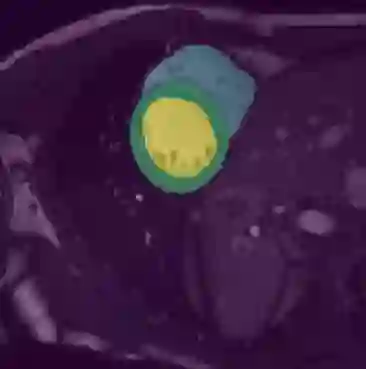
In this paper, we aim to improve the performance of semantic image segmentation in a semi-supervised setting in which training is effectuated with a reduced set of annotated images and additional non-annotated images. We present a method based on an ensemble of deep segmentation models. Each model is trained on a subset of the annotated data, and uses the non-annotated images to exchange information with the other models, similar to co-training. Even if each model learns on the same non-annotated images, diversity is preserved with the use of adversarial samples. Our results show that this ability to simultaneously train models, which exchange knowledge while preserving diversity, leads to state-of-the-art results on two challenging medical image datasets.
翻译:在本文中,我们的目标是提高半监督环境下语义图像分解的性能,在半监督环境下,通过减少一组附加说明的图像和额外的非附加说明的图像进行培训,我们展示了一种基于一系列深层分解模型的方法,每个模型都接受过附加说明数据子集的培训,并使用非附加说明的图像与其他模型交流信息,类似于共同培训。即使每个模型都学习了相同的非附加说明的图像,但通过使用对抗性样本保留了多样性。我们的结果显示,这种同时培训模型的能力,既交流知识,又维护多样性,导致在两个挑战性医学图像数据集中取得最新的结果。