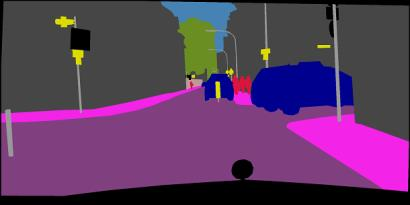
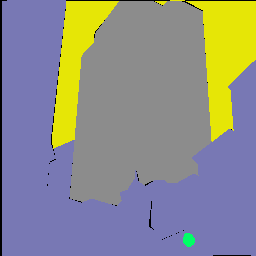
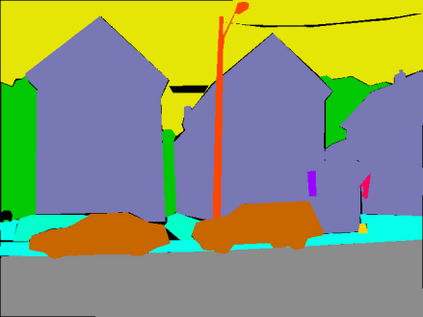
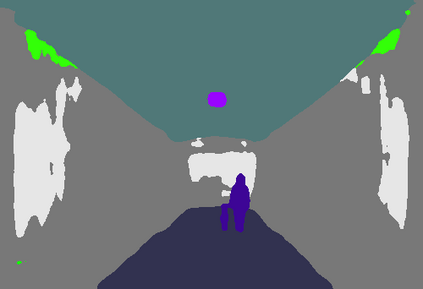
In this paper, we address the problem of semantic segmentation and focus on the context aggregation strategy for robust segmentation. Our motivation is that the label of a pixel is the category of the object that the pixel belongs to. We present a simple yet effective approach, object-contextual representations, characterizing a pixel by exploiting the representation of the corresponding object class. First, we construct object regions based on a feature map supervised by the ground-truth segmentation, and then compute the object region representations. Second, we compute the representation similarity between each pixel and each object region, and augment the representation of each pixel with an object contextual representation, which is a weighted aggregation of all the object region representations according to their similarities with the pixel. We empirically demonstrate that the proposed approach achieves competitive performance on six challenging semantic segmentation benchmarks: Cityscapes, ADE20K, LIP, PASCAL VOC 2012, PASCAL-Context and COCO-Stuff. Notably, we achieved the \nth{2} place on the Cityscapes leader-board with a single model.
翻译:在本文中,我们处理语义分解问题, 并侧重于动态分解的背景聚合战略。 我们的动机是像素标签是像素所属对象的类别。 我们展示了简单而有效的方法, 对象- 逻辑表达, 通过利用相应对象类的表示来描述像素。 首先, 我们根据地面- 真实分解所监督的地貌图构建目标区域, 然后计算对象区域表示。 其次, 我们计算每个像素和每个对象区域之间的相似性, 并以对象背景表示方式增加每个像素的表示方式, 这是根据所有对象区域表示与像素的相似性, 对所有对象区域表示进行加权汇总。 我们从经验上证明, 提议的方法在六种具有挑战性的语义分解基准上取得了竞争性的表现: 城市景、 ADE20K、 LIP、 PASAL VOC 2012、 PASAL- Context 和 CO- Stuff。 值得注意的是, 我们用单一模型在市景领袖- 板板上实现了\nth{2} 位置。