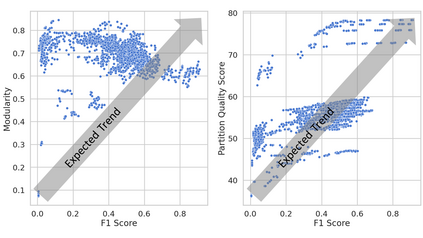
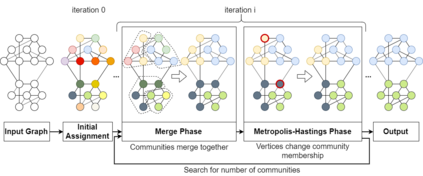
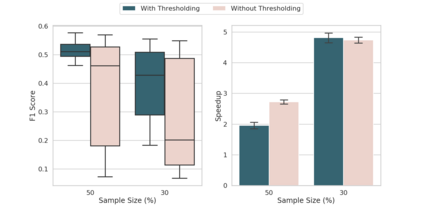
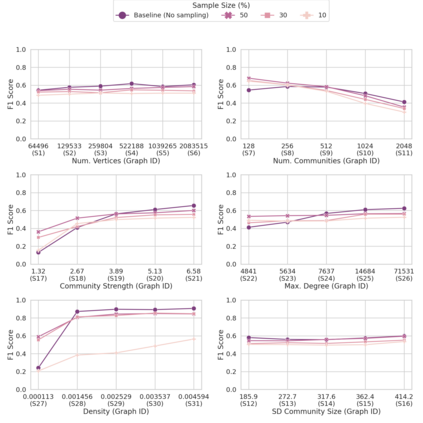
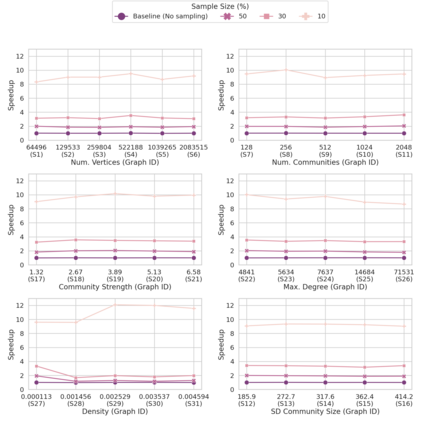
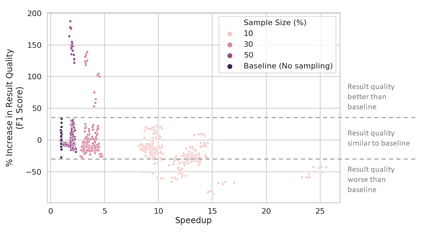
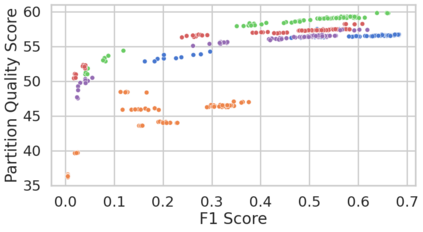
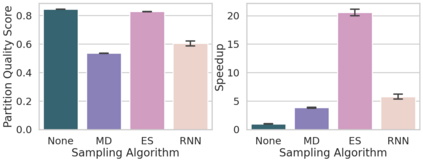
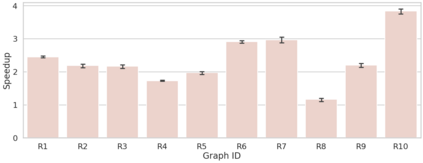
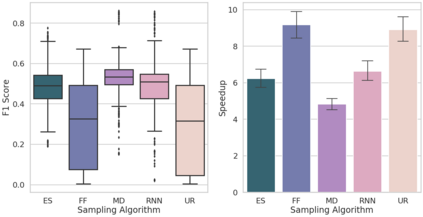
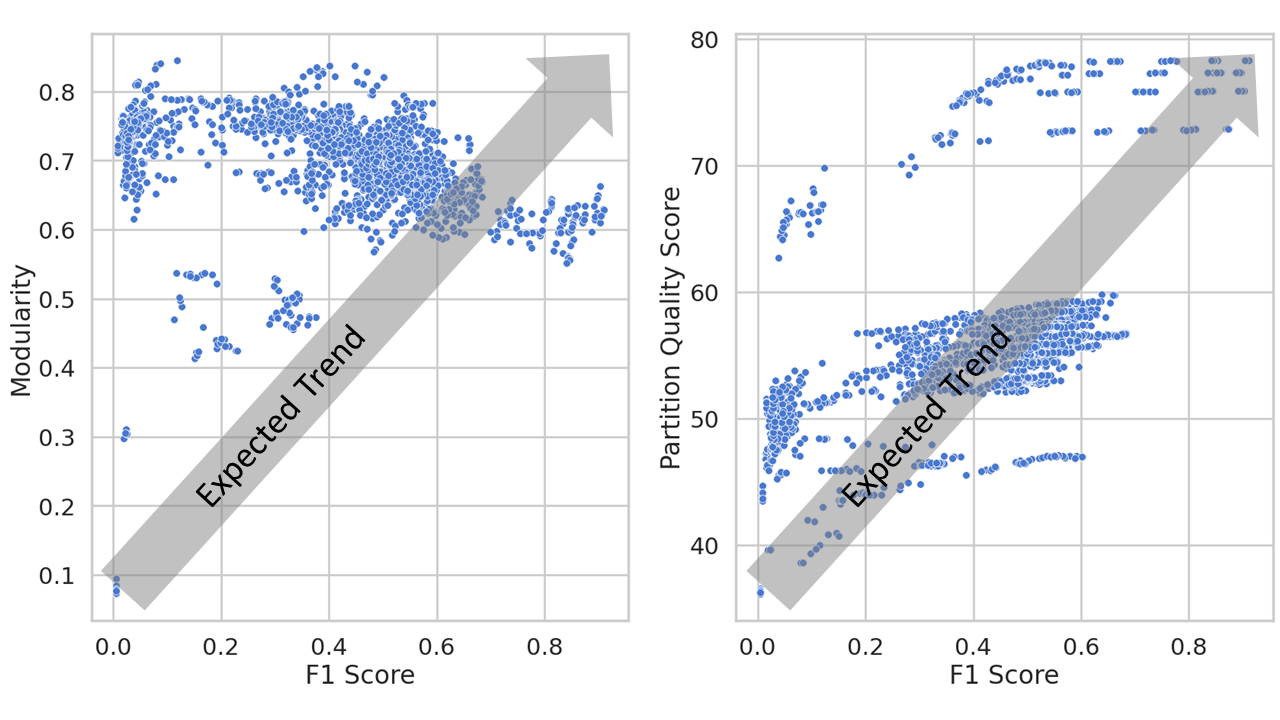
Community detection is a well-studied problem with applications in domains ranging from networking to bioinformatics. Due to the rapid growth in the volume of real-world data, there is growing interest in accelerating contemporary community detection algorithms. However, the more accurate and statistically robust methods tend to be hard to parallelize. One such method is stochastic block partitioning (SBP) - a community detection algorithm that works well on graphs with complex and heterogeneous community structure. In this paper, we present a sampling-based SBP (SamBaS) for accelerating SBP on sparse graphs. We characterize how various graph parameters affect the speedup and result quality of community detection with SamBaS and quantify the trade-offs therein. To evaluate SamBas on real-world web graphs without known ground-truth communities, we introduce partition quality score (PQS), an evaluation metric that outperforms modularity in terms of correlation with F1 score. Overall, SamBaS achieves speedups of up to 10X while maintaining result quality (and even improving result quality by over 150% on certain graphs, relative to F1 score).
翻译:社区探测是一个在从网络到生物信息学的各个领域应用的很好研究的问题。由于实际世界数据量的迅速增长,人们越来越关心加速当代社区检测算法的加速和结果质量。然而,更准确和统计上更健全的方法往往难以平行。这种方法之一是随机区块分隔法(SBP),这是一种社区检测算法,在与复杂和多样化社区结构的图表上运作良好。在本文中,我们展示了一种基于抽样的SBP(SamBAS),用稀薄的图表加速SBP(SamBAS),我们描述各种图表参数如何影响社区与SamBAS的检测速度和结果质量,并量化其中的取舍。为了在没有已知的地铁社区的情况下评估现实世界网络图上的SamBas(SamBas),我们引入了分区质量评分(PQS),这是一种在与F1得分的关系方面优于模块性的评估指标。总体而言,SamBAS在保持结果质量(甚至提高某些图表的结果质量150%以上,相对于F1得分)。