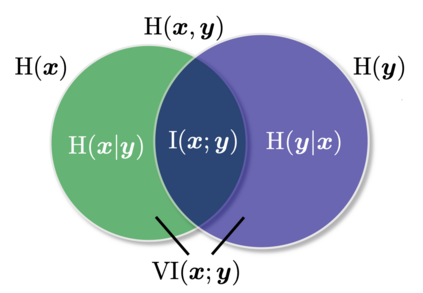
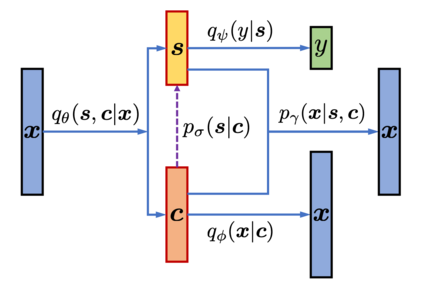
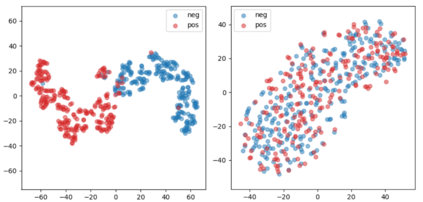
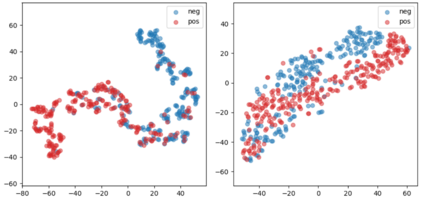
Learning disentangled representations of natural language is essential for many NLP tasks, e.g., conditional text generation, style transfer, personalized dialogue systems, etc. Similar problems have been studied extensively for other forms of data, such as images and videos. However, the discrete nature of natural language makes the disentangling of textual representations more challenging (e.g., the manipulation over the data space cannot be easily achieved). Inspired by information theory, we propose a novel method that effectively manifests disentangled representations of text, without any supervision on semantics. A new mutual information upper bound is derived and leveraged to measure dependence between style and content. By minimizing this upper bound, the proposed method induces style and content embeddings into two independent low-dimensional spaces. Experiments on both conditional text generation and text-style transfer demonstrate the high quality of our disentangled representation in terms of content and style preservation.
翻译:在信息理论的启发下,我们提出了一个新颖的方法,在对语义学不加任何监督的情况下,能够有效地体现相互不相干的文字表述。一个新的相互信息上限是用来衡量风格和内容之间依赖性的。通过尽量减少这一上限,拟议方法将风格和内容嵌入两个独立的低维空间。在有条件的文字生成和文本式传输两个方面进行实验都表明,在内容和风格保护方面,我们解脱的表述质量很高。