【论文推荐】最新六篇对抗自编码器相关论文—多尺度网络节点表示、生成对抗自编码、逆映射、Wasserstein、条件对抗、去噪
【导读】专知内容组整理了最近六篇对抗自编码器(Adversarial Autoencoder)相关文章,为大家进行介绍,欢迎查看!
1. AAANE: Attention-based Adversarial Autoencoder for Multi-scale Network Embedding(AAANE: 基于注意力机制对抗自编码器的多尺度网络节点表示)
作者:Lei Sang,Min Xu,Shengsheng Qian,Xindong Wu
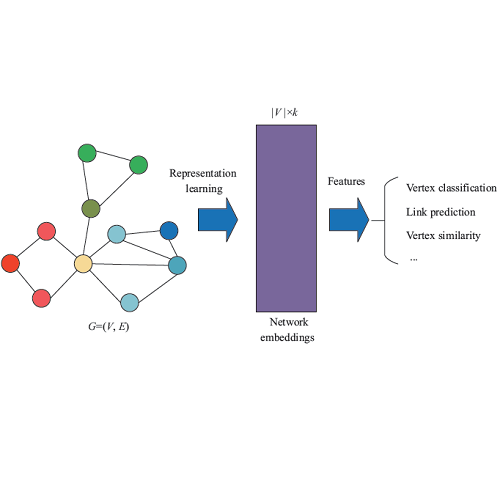
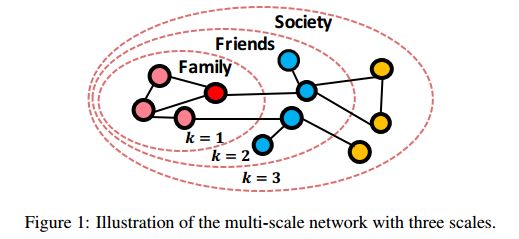
摘要:Network embedding represents nodes in a continuous vector space and preserves structure information from the Network. Existing methods usually adopt a "one-size-fits-all" approach when concerning multi-scale structure information, such as first- and second-order proximity of nodes, ignoring the fact that different scales play different roles in the embedding learning. In this paper, we propose an Attention-based Adversarial Autoencoder Network Embedding(AAANE) framework, which promotes the collaboration of different scales and lets them vote for robust representations. The proposed AAANE consists of two components: 1) Attention-based autoencoder effectively capture the highly non-linear network structure, which can de-emphasize irrelevant scales during training. 2) An adversarial regularization guides the autoencoder learn robust representations by matching the posterior distribution of the latent embeddings to given prior distribution. This is the first attempt to introduce attention mechanisms to multi-scale network embedding. Experimental results on real-world networks show that our learned attention parameters are different for every network and the proposed approach outperforms existing state-of-the-art approaches for network embedding.
期刊:arXiv, 2018年3月24日
网址:
http://www.zhuanzhi.ai/document/2eff4f2b546ad1be81c27bc8436fe570
2. Generative Adversarial Autoencoder Networks(生成对抗自编码器网络)
作者:Ngoc-Trung Tran,Tuan-Anh Bui,Ngai-Man Cheung
摘要:We introduce an effective model to overcome the problem of mode collapse when training Generative Adversarial Networks (GAN). Firstly, we propose a new generator objective that finds it better to tackle mode collapse. And, we apply an independent Autoencoders (AE) to constrain the generator and consider its reconstructed samples as "real" samples to slow down the convergence of discriminator that enables to reduce the gradient vanishing problem and stabilize the model. Secondly, from mappings between latent and data spaces provided by AE, we further regularize AE by the relative distance between the latent and data samples to explicitly prevent the generator falling into mode collapse setting. This idea comes when we find a new way to visualize the mode collapse on MNIST dataset. To the best of our knowledge, our method is the first to propose and apply successfully the relative distance of latent and data samples for stabilizing GAN. Thirdly, our proposed model, namely Generative Adversarial Autoencoder Networks (GAAN), is stable and has suffered from neither gradient vanishing nor mode collapse issues, as empirically demonstrated on synthetic, MNIST, MNIST-1K, CelebA and CIFAR-10 datasets. Experimental results show that our method can approximate well multi-modal distribution and achieve better results than state-of-the-art methods on these benchmark datasets. Our model implementation is published here: https://github.com/tntrung/gaan

期刊:arXiv, 2018年3月24日
网址:
http://www.zhuanzhi.ai/document/457bfc0e3182e83d292caf940b5a4a17
3. Learning Inverse Mappings with Adversarial Criterion(基于对抗标准学习逆映射)
作者:Jiyi Zhang,Hung Dang,Hwee Kuan Lee,Ee-Chien Chang
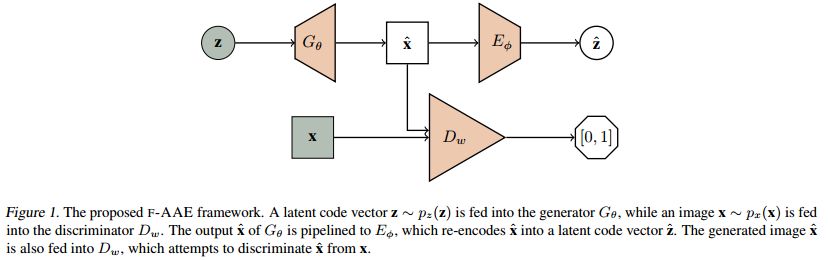
摘要:We propose a flipped-Adversarial AutoEncoder (FAAE) that simultaneously trains a generative model G that maps an arbitrary latent code distribution to a data distribution and an encoder E that embodies an "inverse mapping" that encodes a data sample into a latent code vector. Unlike previous hybrid approaches that leverage adversarial training criterion in constructing autoencoders, FAAE minimizes re-encoding errors in the latent space and exploits adversarial criterion in the data space. Experimental evaluations demonstrate that the proposed framework produces sharper reconstructed images while at the same time enabling inference that captures rich semantic representation of data.
期刊:arXiv, 2018年3月21日
网址:
http://www.zhuanzhi.ai/document/8f4c39a2488948d49d9d6e074019fa83
4.Wasserstein Auto-Encoders(Wasserstein自编码)
作者:Ilya Tolstikhin,Olivier Bousquet,Sylvain Gelly,Bernhard Schoelkopf
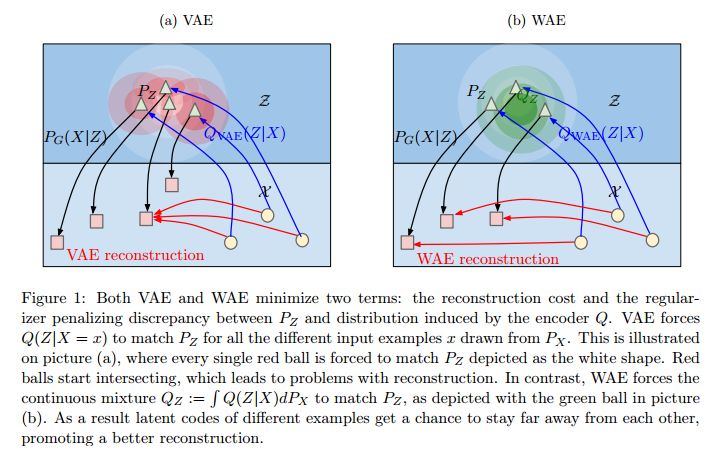
摘要:We propose the Wasserstein Auto-Encoder (WAE)---a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE). This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality, as measured by the FID score.
期刊:arXiv, 2018年3月12日
网址:
http://www.zhuanzhi.ai/document/5a47a71e6da5b52ed1c88b55a5d724a0
5.Sounderfeit: Cloning a Physical Model with Conditional Adversarial Autoencoders(Sounderfeit:基于条件对抗自编码器克隆一个物理模型)
作者:Stephen Sinclair
摘要:An adversarial autoencoder conditioned on known parameters of a physical modeling bowed string synthesizer is evaluated for use in parameter estimation and resynthesis tasks. Latent dimensions are provided to capture variance not explained by the conditional parameters. Results are compared with and without the adversarial training, and a system capable of "copying" a given parameter-signal bidirectional relationship is examined. A real-time synthesis system built on a generative, conditioned and regularized neural network is presented, allowing to construct engaging sound synthesizers based purely on recorded data.
期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/0e9ec08b2ee6bdfe86c3207ffeaabe16
6.Denoising Adversarial Autoencoders(去噪对抗自编码)
作者:Antonia Creswell,Anil Anthony Bharath
机构:Imperial College London
摘要:Unsupervised learning is of growing interest because it unlocks the potential held in vast amounts of unlabelled data to learn useful representations for inference. Autoencoders, a form of generative model, may be trained by learning to reconstruct unlabelled input data from a latent representation space. More robust representations may be produced by an autoencoder if it learns to recover clean input samples from corrupted ones. Representations may be further improved by introducing regularisation during training to shape the distribution of the encoded data in latent space. We suggest denoising adversarial autoencoders, which combine denoising and regularisation, shaping the distribution of latent space using adversarial training. We introduce a novel analysis that shows how denoising may be incorporated into the training and sampling of adversarial autoencoders. Experiments are performed to assess the contributions that denoising makes to the learning of representations for classification and sample synthesis. Our results suggest that autoencoders trained using a denoising criterion achieve higher classification performance, and can synthesise samples that are more consistent with the input data than those trained without a corruption process.
期刊:arXiv, 2018年1月5日
网址:
http://www.zhuanzhi.ai/document/ebadc455b2ed3cd9d83f6c1365f25449
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!