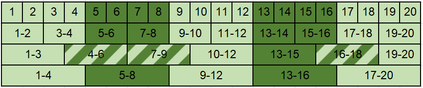
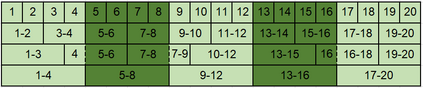
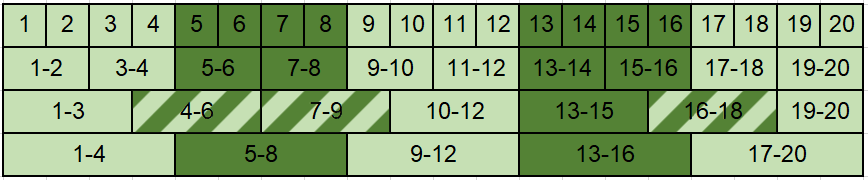
Character-based representations have important advantages over subword-based ones for morphologically rich languages. They come with increased robustness to noisy input and do not need a separate tokenization step. However, they also have a crucial disadvantage: they notably increase the length of text sequences. The GBST method from Charformer groups (aka downsamples) characters to solve this, but allows information to leak when applied to a Transformer decoder. We solve this information leak issue, thereby enabling character grouping in the decoder. We show that Charformer downsampling has no apparent benefits in NMT over previous downsampling methods in terms of translation quality, however it can be trained roughly 30% faster. Promising performance on English--Turkish translation indicate the potential of character-level models for morphologically-rich languages.
翻译:基于字符的表示方式比基于子词的表达方式对形态丰富语言的基于子词的表达方式具有重要的优势。 它们随着对噪音输入的强度的增强而产生,而不需要单独的象征性步骤。 但是,它们也有一个关键性的不利之处:它们明显地增加了文本序列的长度。 Charref Group( aka downsamples) 字符的GBST 方法可以解决这个问题,但允许在应用到变异器解码器时泄漏信息。 我们解决了这个信息泄漏问题,从而在解码器中进行字符分组。 我们显示,Charfrent 下标在NMT中与先前的下标方法相比,在翻译质量方面没有明显的好处,但是可以更快地对其进行大约30%的培训。 英文-土耳其文翻译的预测性能显示了形态丰富语言的品位模型的潜力。