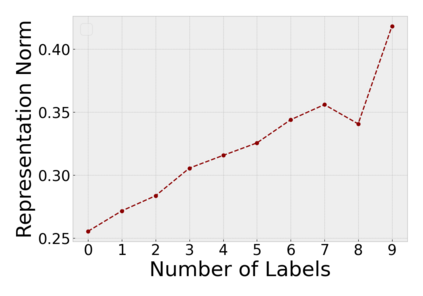
Although self-/un-supervised methods have led to rapid progress in visual representation learning, these methods generally treat objects and scenes using the same lens. In this paper, we focus on learning representations for objects and scenes that preserve the structure among them. Motivated by the observation that visually similar objects are close in the representation space, we argue that the scenes and objects should instead follow a hierarchical structure based on their compositionality. To exploit such a structure, we propose a contrastive learning framework where a Euclidean loss is used to learn object representations and a hyperbolic loss is used to encourage representations of scenes to lie close to representations of their constituent objects in a hyperbolic space. This novel hyperbolic objective encourages the scene-object hypernymy among the representations by optimizing the magnitude of their norms. We show that when pretraining on the COCO and OpenImages datasets, the hyperbolic loss improves downstream performance of several baselines across multiple datasets and tasks, including image classification, object detection, and semantic segmentation. We also show that the properties of the learned representations allow us to solve various vision tasks that involve the interaction between scenes and objects in a zero-shot fashion. Our code can be found at \url{https://github.com/shlokk/HCL/tree/main/HCL}.
翻译:虽然自我/不受监督的方法导致视觉演示学习的迅速进展,但这些方法一般使用相同的镜头来对待物体和场景。在本文中,我们侧重于学习能保护物体和场景结构的物体和场景的显示方式。受在显示空间内视觉相似物体接近的观察的驱使,我们主张场景和对象应采用基于其构成性的等级结构。为了利用这种结构,我们提议了一个对比式学习框架,即用欧立底体损失来学习物体的显示方式,用双曲体损失来鼓励场景的显示方式接近其组成物体在双向空间的显示方式的显示方式。这个新颖的双面目标通过优化其规范的大小来鼓励显示场景和场景之间的超音性格。我们表明,在对CO和Openimages数据集进行预先训练时,超单体损失可以改善多个数据集和任务(包括图像分类、物体探测和语义分分化)的下游业绩。我们还表明,学习过的场景特性使我们能够在各种视觉任务中解决涉及互动场景和SHCR/CLSHL/commass。