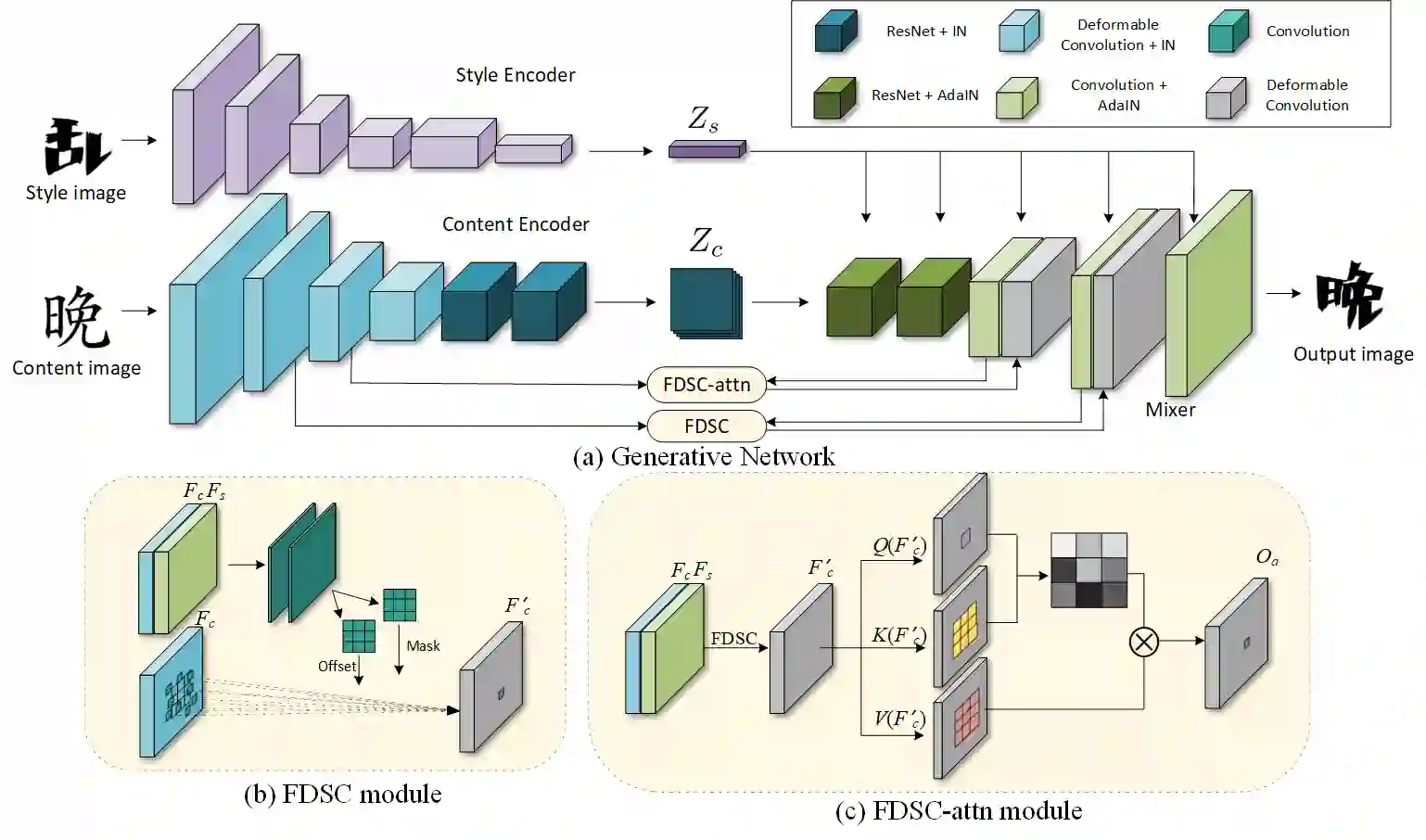
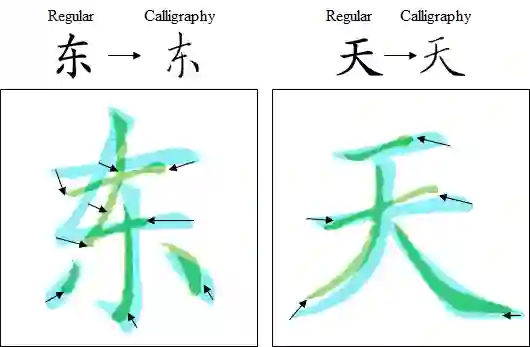
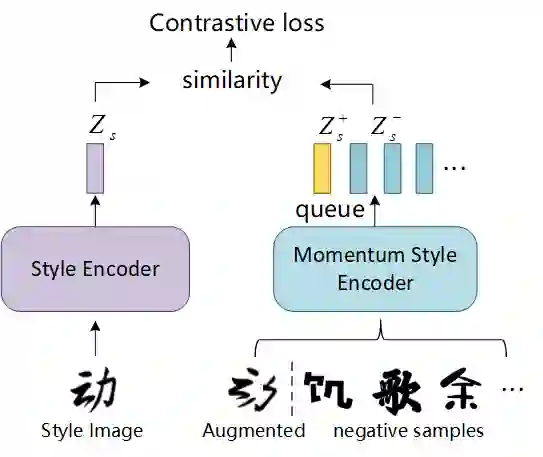
Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
翻译:没有人类专家自动生成自动图像是一个实际和严重的问题,特别是对于一些由大量字符组成的语言来说,这是一个由大量字符组成的高空字体生成是一个非常实际和严重的问题。用于创建字体的现有方法往往是在监督的学习中。它们需要大量配对数据,这些数据需要劳动密集型和昂贵的收集。相比之下,常见的未经监督的图像到图像翻译方法不适用于字体生成,因为它们通常将样式定义为纹理和颜色的组合。在这项工作中,我们建议为未经监督的字体生成(以 DGFont++为缩放格式)建立一个强而可变的更高变异的变异型网络。我们引入了一个功能变异的连接(FDSC),以学习本地字体的相似性和不相异性,我们引入了一个功能的变异性跳动连接(FDSC) 来学习本地和字体的变异性(FDSC ) 来学习本地化的图像。为了区分本地和字体的超常变异性(FDSDS) 格式,我们用不同的样式来分析不同的变异性格式,我们用另一种模式来模拟的变异性格式的变换格式的图像,我们用另一种格式的模型来计算来计算。