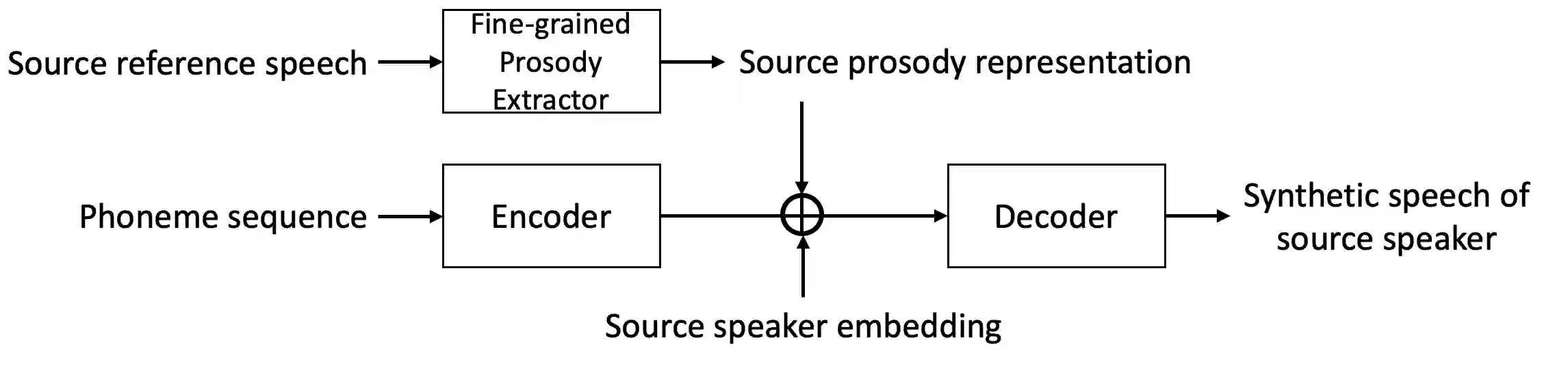
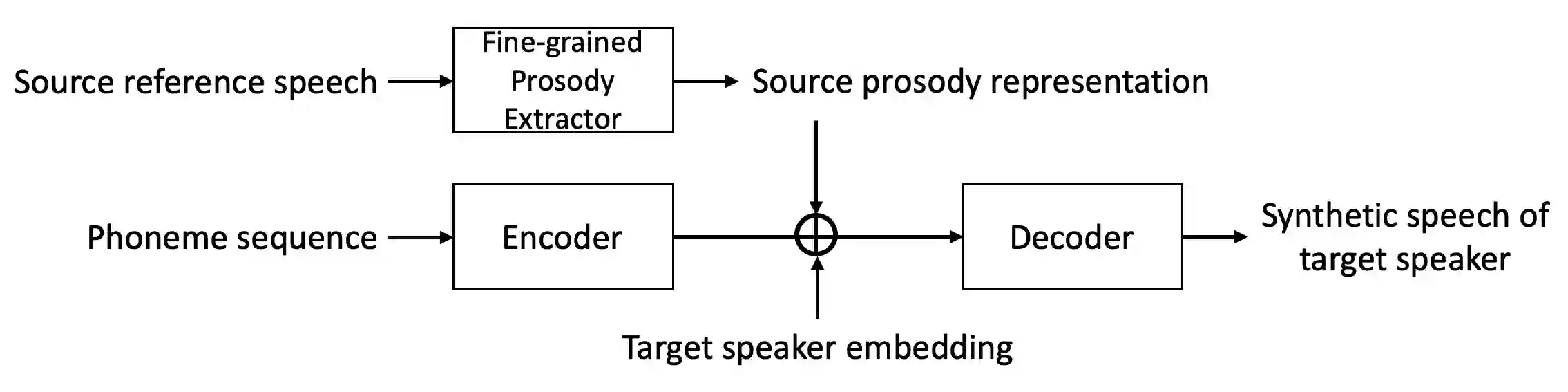
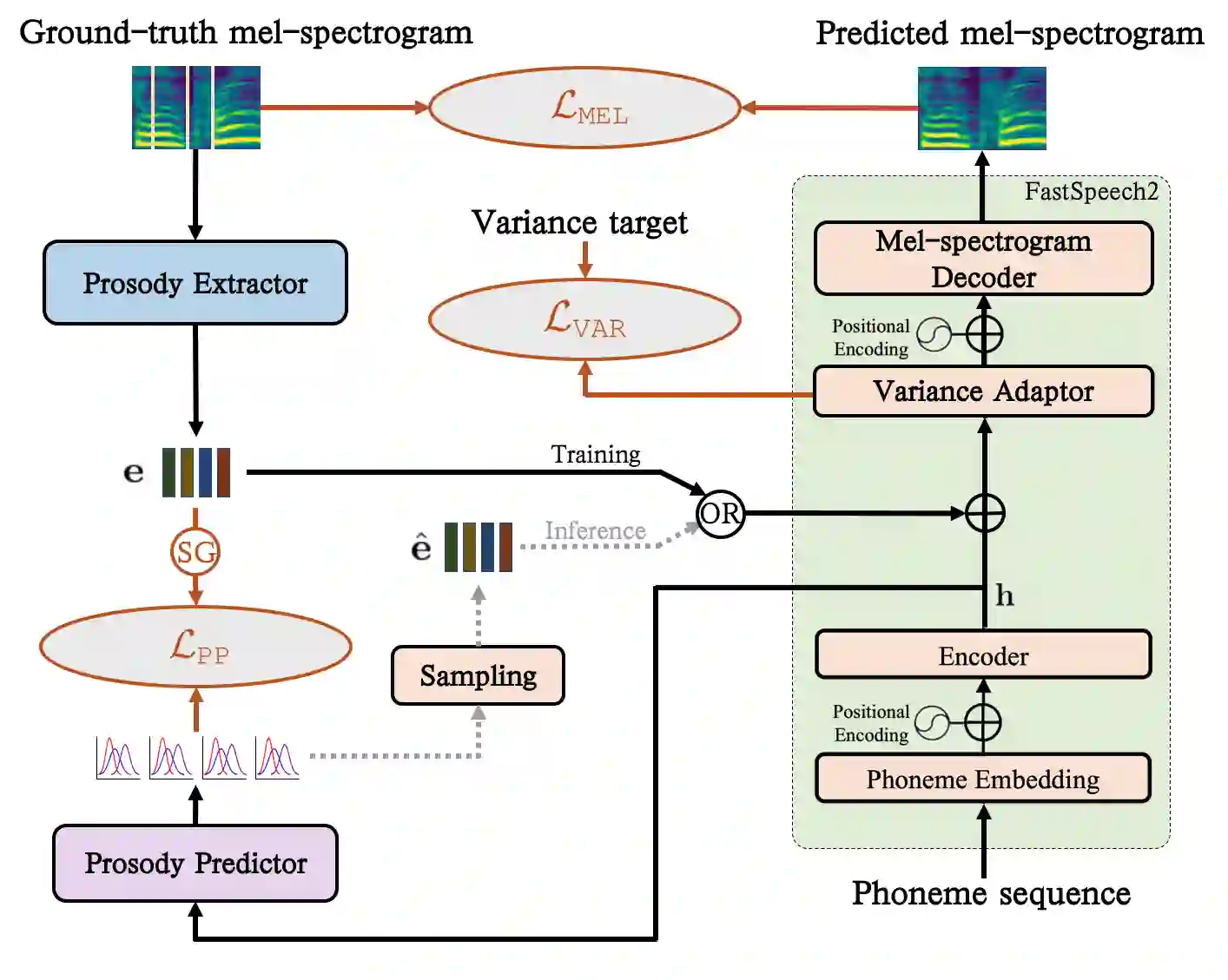
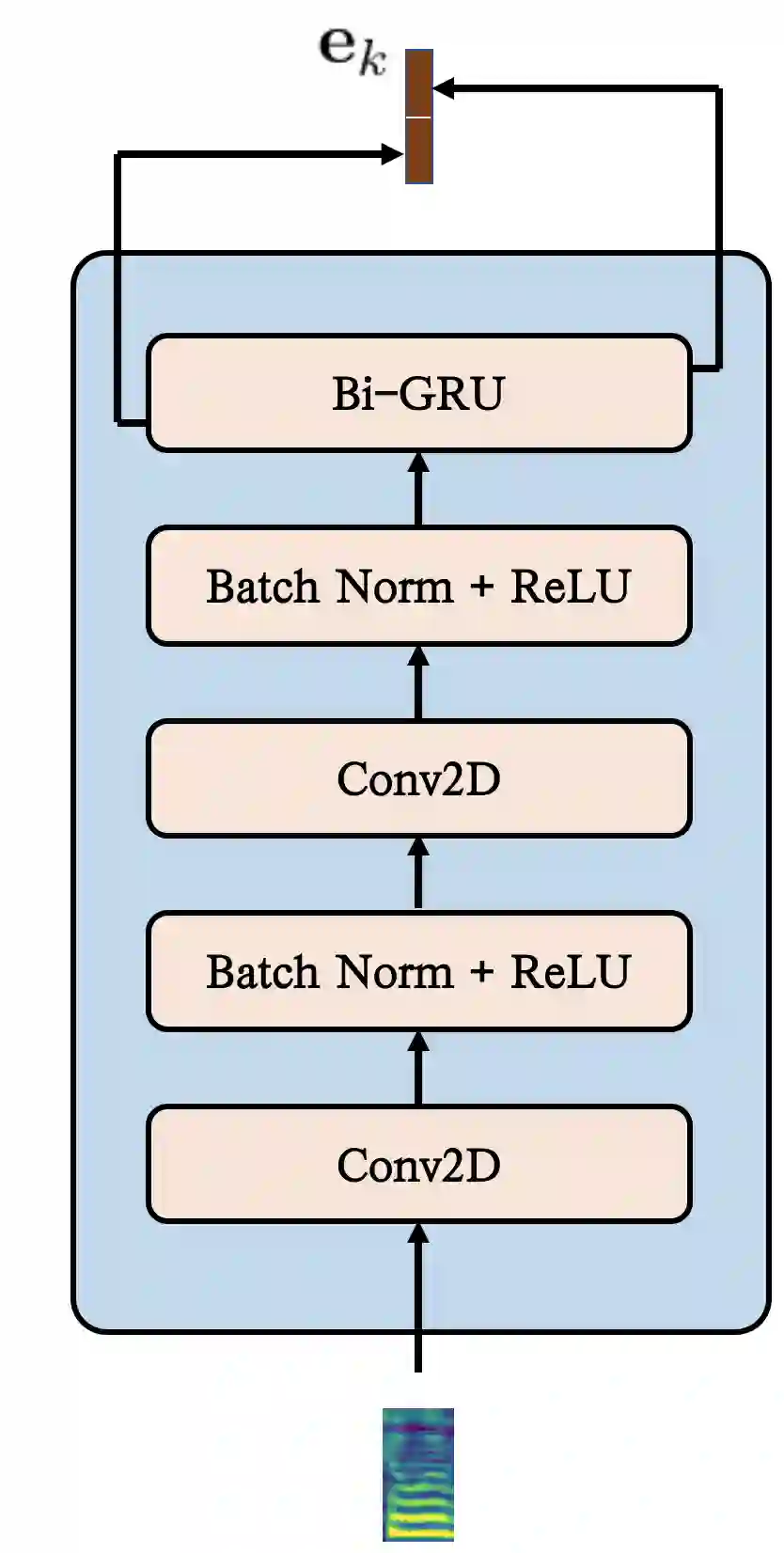
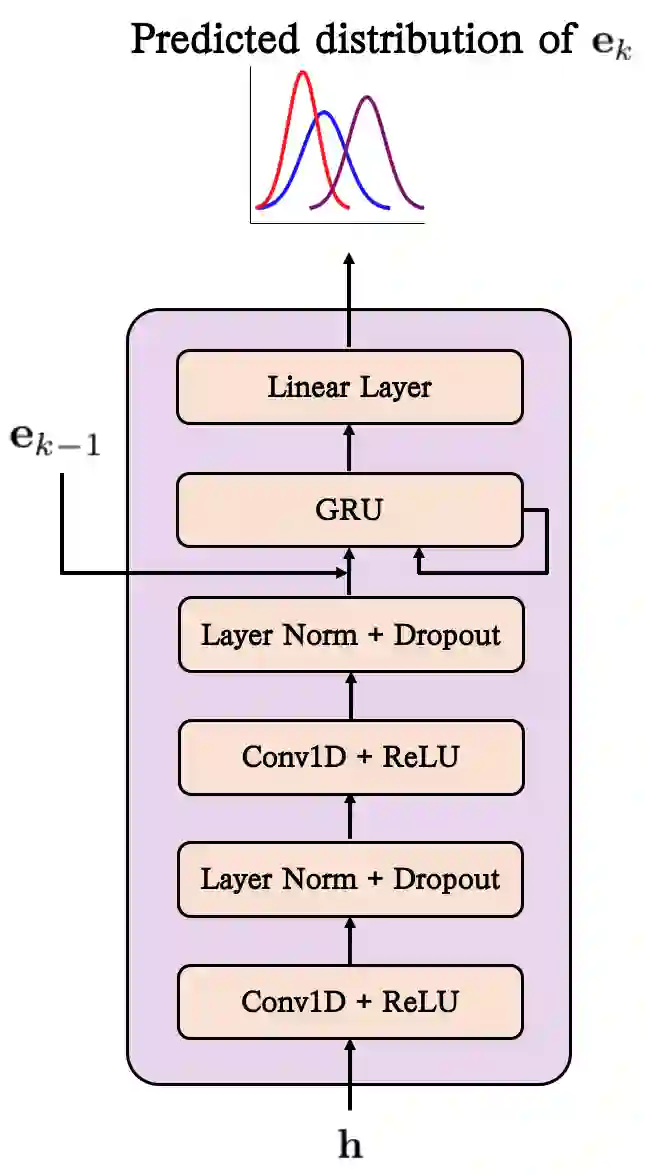
Generating natural speech with diverse and smooth prosody pattern is a challenging task. Although random sampling with phone-level prosody distribution has been investigated to generate different prosody patterns, the diversity of the generated speech is still very limited and far from what can be achieved by human. This is largely due to the use of uni-modal distribution, such as single Gaussian, in the prior works of phone-level prosody modelling. In this work, we propose a novel approach that models phone-level prosodies with a GMM-based mixture density network and then extend it for multi-speaker TTS using speaker adaptation transforms of Gaussian means and variances. Furthermore, we show that we can clone the prosodies from a reference speech by sampling prosodies from the Gaussian components that produce the reference prosodies. Our experiments on LJSpeech and LibriTTS dataset show that the proposed GMM-based method not only achieves significantly better diversity than using a single Gaussian in both single-speaker and multi-speaker TTS, but also provides better naturalness. The prosody cloning experiments demonstrate that the prosody similarity of the proposed GMM-based method is comparable to recent proposed fine-grained VAE while the target speaker similarity is better.
翻译:以不同和顺畅的流体模式生成自然语言,是一项艰巨的任务。 尽管对手机级流体分布的随机抽样抽样进行了调查,以产生不同的流体模式,但所产生的语音多样性仍然非常有限,而且远非人类所能实现的。这在很大程度上是由于在先前的电话级流体模拟工作中使用了单一模式分布,如单一高斯语。在这项工作中,我们提出了一个新颖的方法,即以基于GMM的混合密度网络模拟电话级推进器,然后使用高斯语言变换语言变换和差异来扩展多语组 TTTS。此外,我们表明,我们可以从一个参考演讲中复制来自高斯语组中生成参考推进器的推进器。我们对LJSpeech和LibriTTS数据集的实验显示,拟议的GMM方法不仅比在单位和多位混合的TTTTS中使用单一高音组,而且扩展到多语组TTS的多语组技术。我们展示了我们从一个参考演讲器中复制的推进者,而拟议的类似性GMMRM方法则是更好的。