Generative Adversarial Text to Image Synthesis论文解读
1.背景
这篇文章介绍了一种能够将人工编写一句描述性文本直接转换成为图像。比如,“this white and yellow flower have thin white petals and a round yellow stamen”就应该能生成下面这些图片:

这是一个看起来很有趣的工作,因为它适用范围相当广,但这个问题显然还是挺困难的,所以还没有得到非常良好的解决。
这项工作主要面临两大挑战:
1.学习到能够捕捉到重要的视觉细节的文本特征表达 (learn a text feature representation that captures the important visual details)
2.使用这些特征来合成一些让人们误以为真的图片 (use these features to synthesize a compelling image that a human might mistake for real).
由于近年来深度学习的兴起,这两项挑战的子问题“自然语言表达”和“图像合成”已经得到了一定程度的解决。但是,仍然存在着一个没能很好解决的问题:按描述生成图片(即以文本描述为条件的图像概率分布)是一个非常多模态的问题,也就是说,很有可能会有很多图片都能套用到相同的解释之上。这篇文章的主要贡献就是实现了一个简单高效的GAN架构和训练策略,使得从人工编写的描述文本合成鸟与花的图片成为可能。
2.方法和网络结构
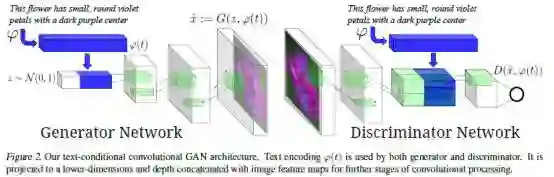
如图所示,网络如同其他GAN一样,分为生成器G和判别器D两个部分。由于是条件GAN,所以生成器的输入不止有随机采样的噪声z∼N(0,1),更有一个text feature(即图中蓝色部分)。这个text feature是由text encoder ϕ 生成的。通常需要将描述文本使用一个全连接层压缩到一个较小维度之后(一般是128维),并使用leaky ReLU再与噪声向量z拼接在一起,作为生成器的整体的输入。
紧接着,后续的前向推断过程就是一个反卷积网络:即一张合成的图片x^通过x^←G(z,ϕ(t))被生成出来。
判别器D。前面几层使用了stride-2卷积层并使用了spatial batch normalization和leaky ReLU。并且仍然像以前一样使用一个全连接层接上一个rectifier来减少描述文本embedding ϕ(t)的维度。当判别器的维度是4×4时,将这个描述文本的embedding复制多份,并在深度上与图片进行拼接。然后在拼接之后的新tensor上继续执行一个卷积操作,然后再计算得分。这便是整个框架在inference的流程。
3.训练
训练条件GAN的最直接的方法就是将图片和description embedding看作是联合的样本,通过观察判别器判断“生成的图片+文本”这个整体是真的还是假的。不过这个方法有些naive:并没有在训练中给判别器提供“是否按照描述正确生成了图像”的信息。
判别其将会观察到两种不同的输入:正确的图片并且配上了正确的文本,以及错误的图片配上了随意的文本。所以,需要分开记录这两种不同的错误来源:不真实的图片(配上任何文本),以及真实图片但条件信息匹配错误。
作者修改了GAN的训练算法来将这两种不同的错误分开。除了real/fake这两种输入以外,作者又增加了第三种输入“真实的图片配上错误的文本”,而判别器也必须要能把这种错误给区分出来。
4.算法流程

首先,将正确的和错误的文本信息encode成h和h^,然后采样出一个随机噪声,然后用正确的encode和随机噪声,产生一组fake图片。然后分别计算三个不同的判别其判别的结果:真实图片正确文本、真实图片错误文本、生成图片正确文本。然后再通过后面的公式计算判别器的损失函数,进而更新判别器。然后再计算生成器的损失函数,并更新生成器。最终完成整个流程。
5.实验结果


6.补充
上面介绍的GAN-CLS方法是训练这个模型的方法之一,文中作者提出了另一种训练方法。深度学习的目的在于学习一个良好的特征表达。一些文章证明,在embedding pairs之间的插值如果在数据流形附近,就说明这个特征选得好。所以我们可以创建大量的额外的text embedding,这些text embedding其实是通过训练集标注的text embedding通过插值得到的。换句话说,这些插值得到的embedding是无法直接对应到人工文本标注上的,所以这一部分数据时不需要标注的。想要利用这些数据,只需要在生成器的目标函数上增加这样一项:Et1,t2∼pdata[log(1−D(G(z,βt1+(1−β)t2)))] 这个公式相当于综合考虑了两个text embedding t1和t2的插值点。通常在实际应用中使用β=0.5效果就不错了。


