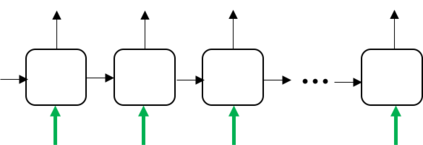
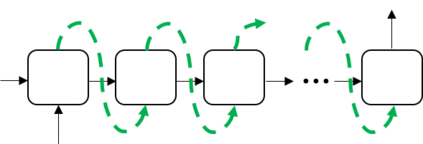
While neural end-to-end text-to-speech (TTS) is superior to conventional statistical methods in many ways, the exposure bias problem in the autoregressive models remains an issue to be resolved. The exposure bias problem arises from the mismatch between the training and inference process, that results in unpredictable performance for out-of-domain test data at run-time. To overcome this, we propose a teacher-student training scheme for Tacotron-based TTS by introducing a distillation loss function in addition to the feature loss function. We first train a Tacotron2-based TTS model by always providing natural speech frames to the decoder, that serves as a teacher model. We then train another Tacotron2-based model as a student model, of which the decoder takes the predicted speech frames as input, similar to how the decoder works during run-time inference. With the distillation loss, the student model learns the output probabilities from the teacher model, that is called knowledge distillation. Experiments show that our proposed training scheme consistently improves the voice quality for out-of-domain test data both in Chinese and English systems.
翻译:虽然神经端到终端文本到语音(TTS)在许多方面优于常规统计方法,但自动递减模型中的暴露偏差问题仍然是一个有待解决的问题。接触偏差问题产生于培训和推断过程的不匹配,这导致在运行时外部测试数据性能不可预测。要克服这一点,我们建议为基于塔科特龙的TTS提供师生培训计划,除了功能损失功能功能外,还引入蒸馏损失功能。我们首先培训基于塔科特龙-2基于TTTS的模型,向解码器提供自然语音框架,作为教师模型。我们随后将基于Tacotron2-基于TTTS的模型作为学生模型,其中,解码器将预测的语音框架作为输入,类似于运行时解码器在运行时的工作方式。随着蒸馏损失,学生模型从教师模型中学习了产出概率,这被称为知识蒸馏。实验显示,我们拟议的培训计划始终在改进中文本系统和中外数据测试的语音质量。