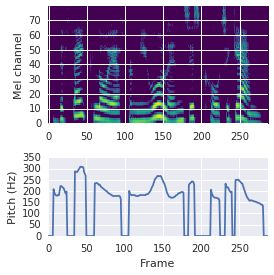
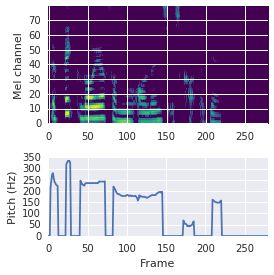
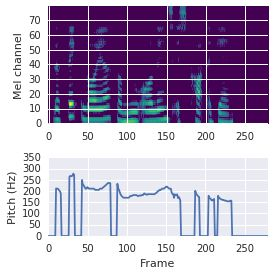
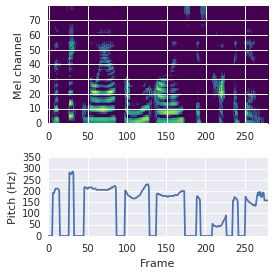
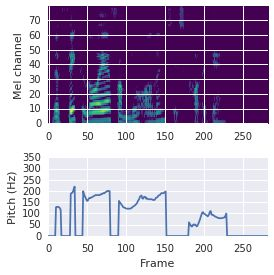
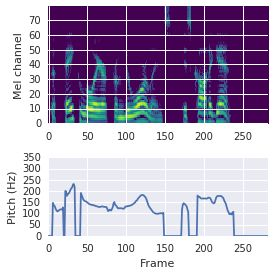
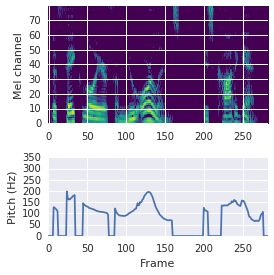
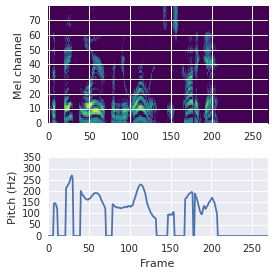
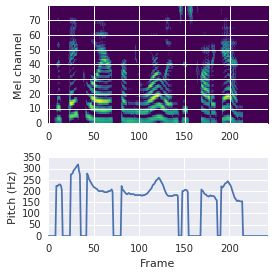
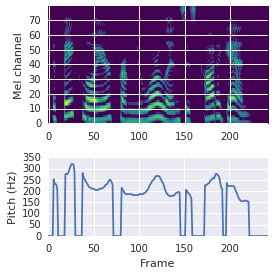
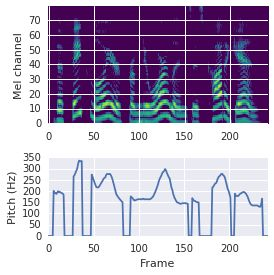
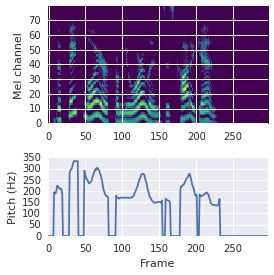
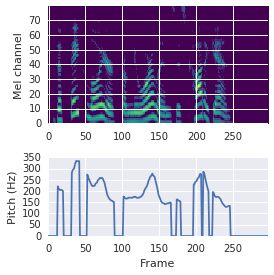
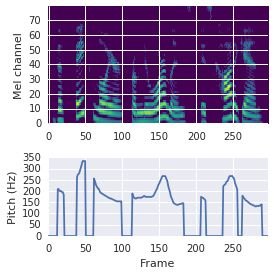
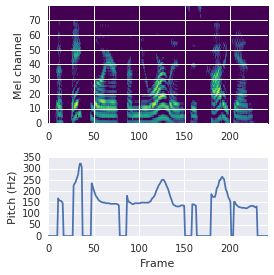
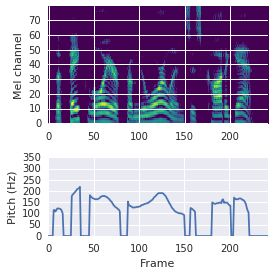
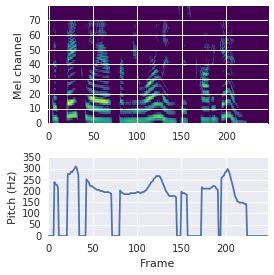
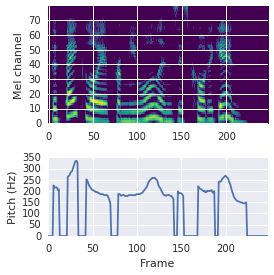
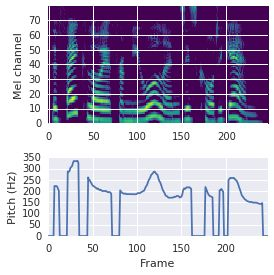
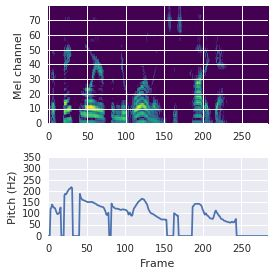
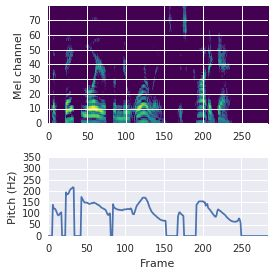
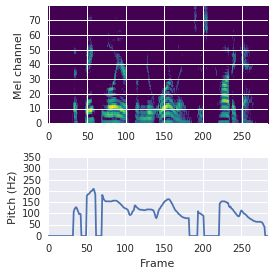
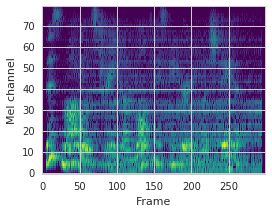
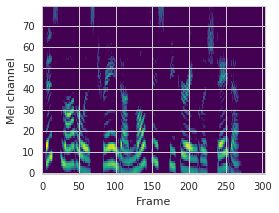
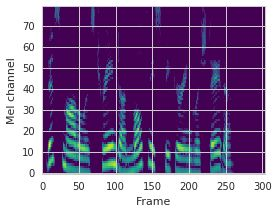
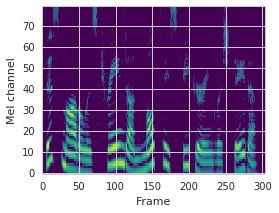
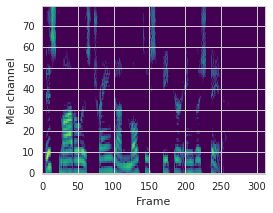
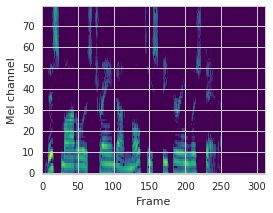
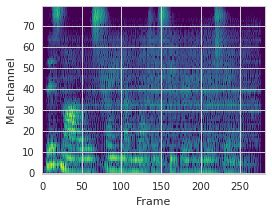
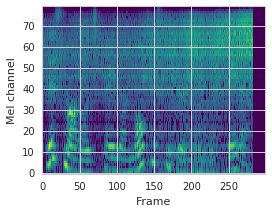
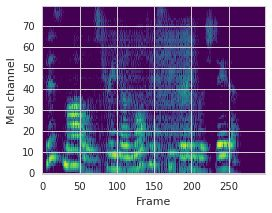
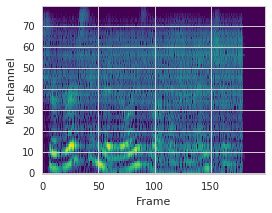
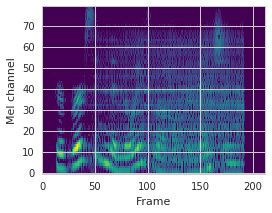
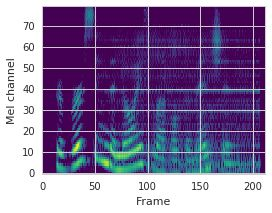
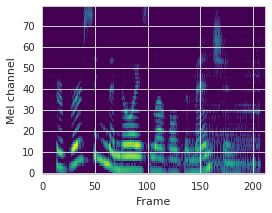
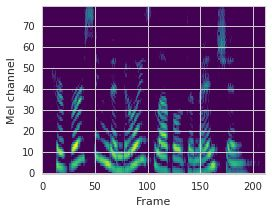
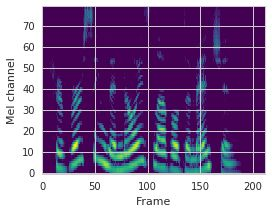
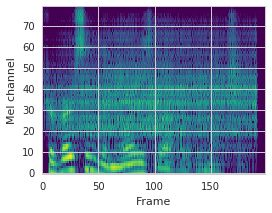
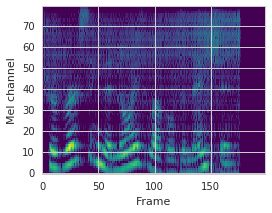
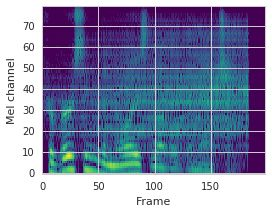
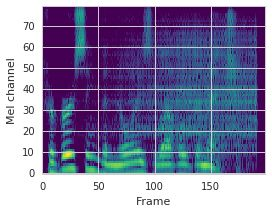
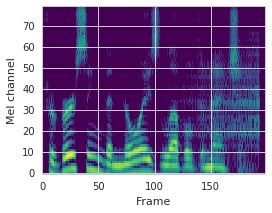
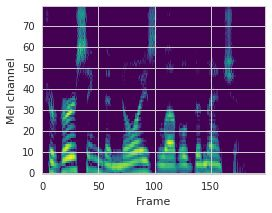
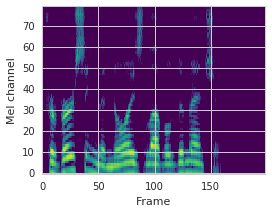
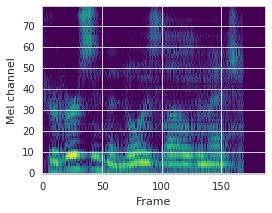
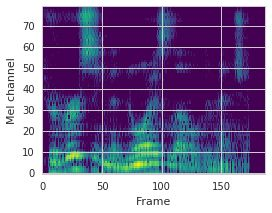
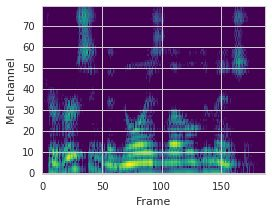
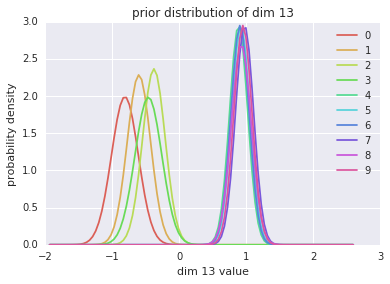
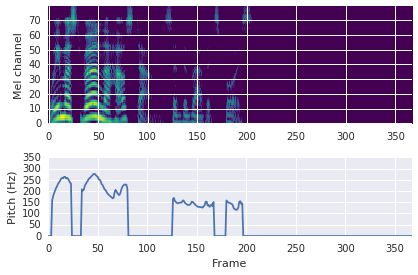
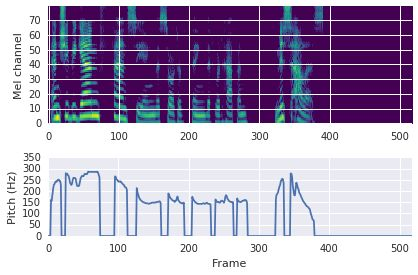
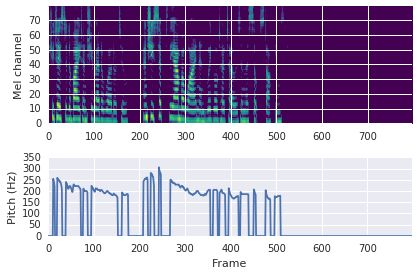
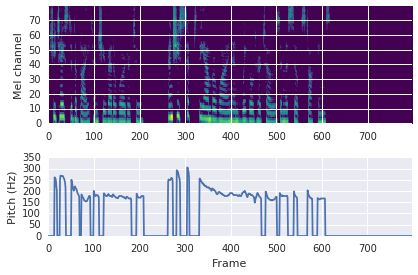
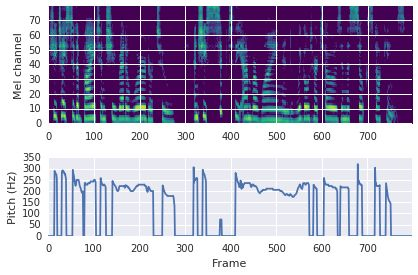
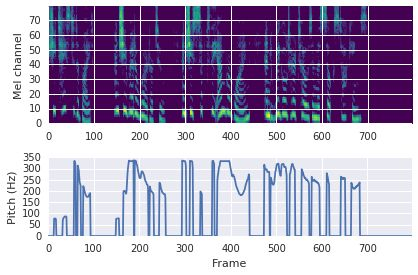
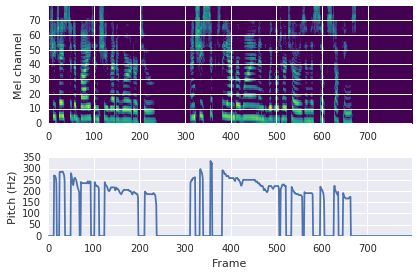
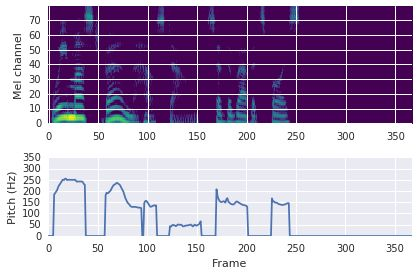
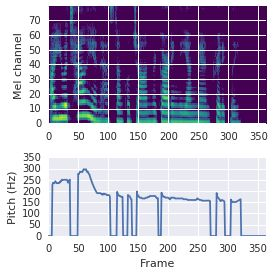
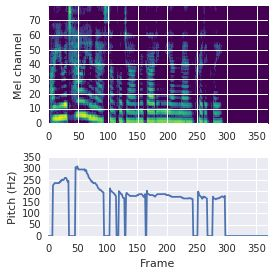
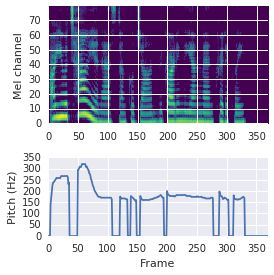
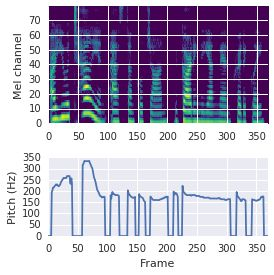
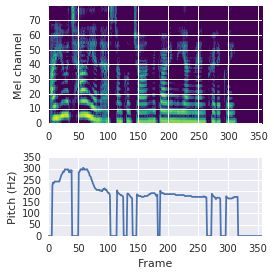
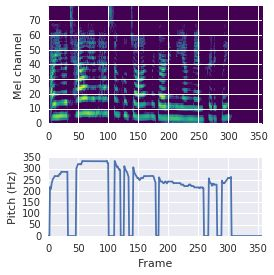
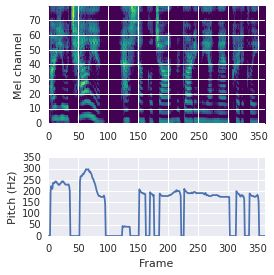
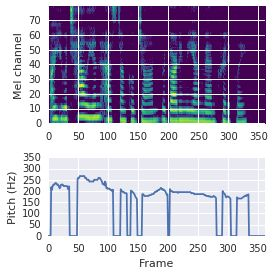
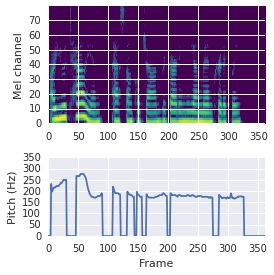
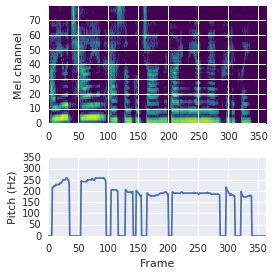
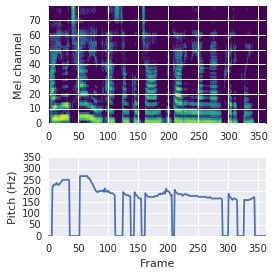
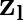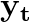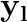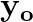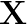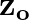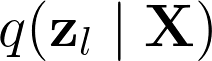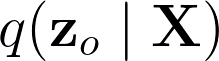This paper proposes a neural sequence-to-sequence text-to-speech (TTS) model which can control latent attributes in the generated speech that are rarely annotated in the training data, such as speaking style, accent, background noise, and recording conditions. The model is formulated as a conditional generative model based on the variational autoencoder (VAE) framework, with two levels of hierarchical latent variables. The first level is a categorical variable, which represents attribute groups (e.g. clean/noisy) and provides interpretability. The second level, conditioned on the first, is a multivariate Gaussian variable, which characterizes specific attribute configurations (e.g. noise level, speaking rate) and enables disentangled fine-grained control over these attributes. This amounts to using a Gaussian mixture model (GMM) for the latent distribution. Extensive evaluation demonstrates its ability to control the aforementioned attributes. In particular, we train a high-quality controllable TTS model on real found data, which is capable of inferring speaker and style attributes from a noisy utterance and use it to synthesize clean speech with controllable speaking style.
翻译:本文提出了一个神经序列到顺序文本到语音( TTS) 模型, 该模型可以控制生成的语音中的隐性属性, 而这种潜在属性在培训数据中很少加注, 如语音风格、口音、背景噪音和记录条件等。 该模型是根据变异自动读数( VAE) 框架设计成一个有条件的基因变异模型, 具有两级等级潜伏变量。 第一层是一个绝对变量, 代表属性组( 如清洁/ noisy) 并提供可解释性。 第二层, 以第一层为条件, 是多变量, 用于描述特定属性配置( 如噪声水平、 语音速度), 并且能够对这些属性进行分解细微的精细控制。 这相当于在潜在分布中使用高斯混合模型( GMM ) 来显示它控制上述属性的能力 。 特别是, 我们用真实发现的数据来培训高品质可控 TTS 模型, 它能够从响音调的语音风格中推断出语音特性, 用它来合成清晰的语音控制 。