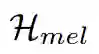Neural network based end-to-end text to speech (TTS) has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron 2) usually first generate mel-spectrogram from text, and then synthesize speech from mel-spectrogram using vocoder such as WaveNet. Compared with traditional concatenative and statistical parametric approaches, neural network based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust (i.e., some words are skipped or repeated) and lack of controllability (voice speed or prosody control). In this work, we propose a novel feed-forward network based on Transformer to generate mel-spectrogram in parallel for TTS. Specifically, we extract attention alignments from an encoder-decoder based teacher model for phoneme duration prediction, which is used by a length regulator to expand the source phoneme sequence to match the length of target mel-sprectrogram sequence for parallel mel-sprectrogram generation. Experiments on the LJSpeech dataset show that our parallel model matches autoregressive models in terms of speech quality, nearly eliminates the skipped words and repeated words, and can adjust voice speed smoothly. Most importantly, compared with autoregressive models, our model speeds up the mel-sprectrogram generation by 270x. Therefore, we call our model FastSpeech. We will release the code on Github.
翻译:基于语调端到端文本的神经网络( TTS) 大大改善了合成语调的质量。 突出的方法( 例如, Tacotron 2) 通常首先从文本中生成Mel- proctragram, 然后使用 VaveNet 等vocoder 来合成Mel- proctragram的mel- procrogram 。 与传统的 concate- decoder 和统计参数参数参数模型相比, 基于端到端模型的神经网络的语调速度缓慢, 而合成语调通常不强( 即, 有些单词被跳过或重复过) 和缺乏可控性( 语音速度或Prosocial) 。 在这项工作中,我们提议以变异器为基础, 生成Melforforth- procrocrocrographram 来生成Ml- devolucreal deal deal deal deal deal deal laves the LJJJJ- developre lax deal deal develments lactions) 数据, 我们的Speal deal deal deal deal deal decreal democreal democremocreal democreal demodestrations missations 。 我们的磁制的语音缩缩缩缩缩制制制制的图像, 我们的磁制制制制制的磁制制的磁制的图像, 我们制的磁制的磁制制制制制式的磁制的磁制。