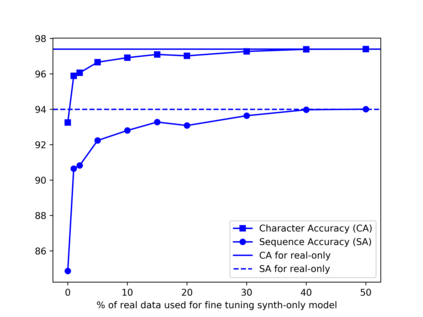
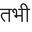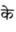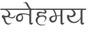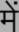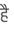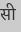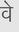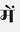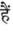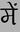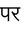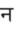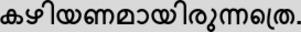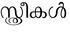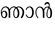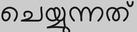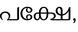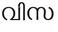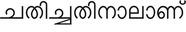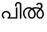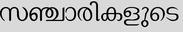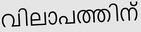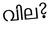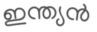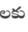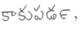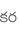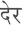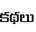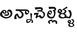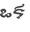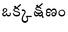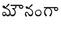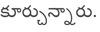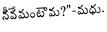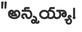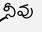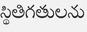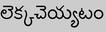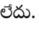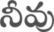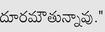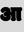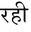Recognition of text on word or line images, without the need for sub-word segmentation has become the mainstream of research and development of text recognition for Indian languages. Modelling unsegmented sequences using Connectionist Temporal Classification (CTC) is the most commonly used approach for segmentation-free OCR. In this work we present a comprehensive empirical study of various neural network models that uses CTC for transcribing step-wise predictions in the neural network output to a Unicode sequence. The study is conducted for 13 Indian languages, using an internal dataset that has around 1000 pages per language. We study the choice of line vs word as the recognition unit, and use of synthetic data to train the models. We compare our models with popular publicly available OCR tools for end-to-end document image recognition. Our end-to-end pipeline that employ our recognition models and existing text segmentation tools outperform these public OCR tools for 8 out of the 13 languages. We also introduce a new public dataset called Mozhi for word and line recognition in Indian language. The dataset contains more than 1.2 million annotated word images (120 thousand text lines) across 13 Indian languages. Our code, trained models and the Mozhi dataset will be made available at http://cvit.iiit.ac.in/research/projects/cvit-projects/
翻译:在这项工作中,我们介绍了对各种神经网络模型的综合实证研究,这些模型使用气候网络模型将神经网络输出中的分级预测转换成统一编码序列。研究针对13种印度语言,使用每种语言约1000页的内部数据集进行。我们研究如何选择行与字作为识别单位,并使用合成数据来培训模型。我们比较我们的模型与公众普及的OCR工具进行终端到终端文件图像识别。我们利用我们的识别模型和现有文本分解工具将13种语言中的8种公共OCR工具转换为超越这些公共 OCR工具的终端到终端管道。我们还引入了一个新的公共数据集,名为Mozhi, 用于印度语言的文字和直线识别。数据集包含120万个注释词图像(120万条文本),在13种印度语言中制作了Mezhezh/Mezurodrouture。