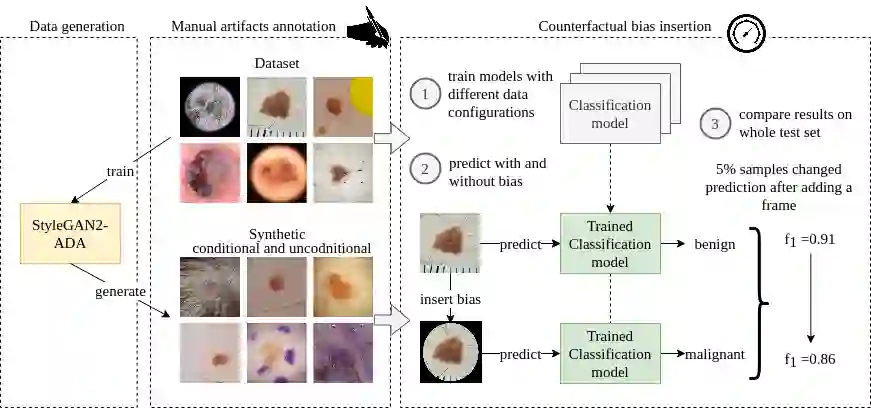
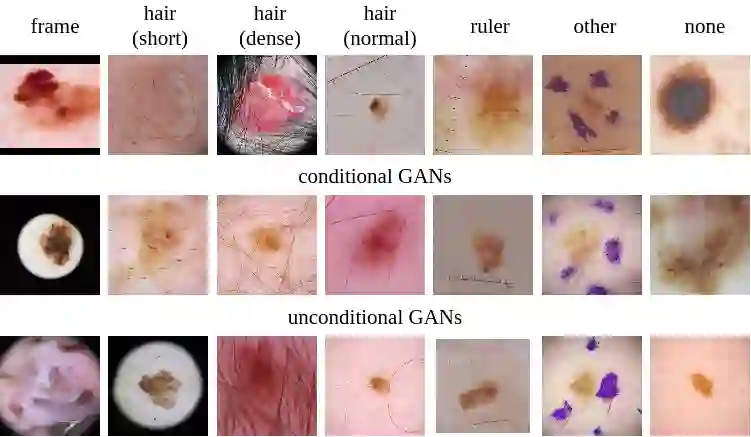
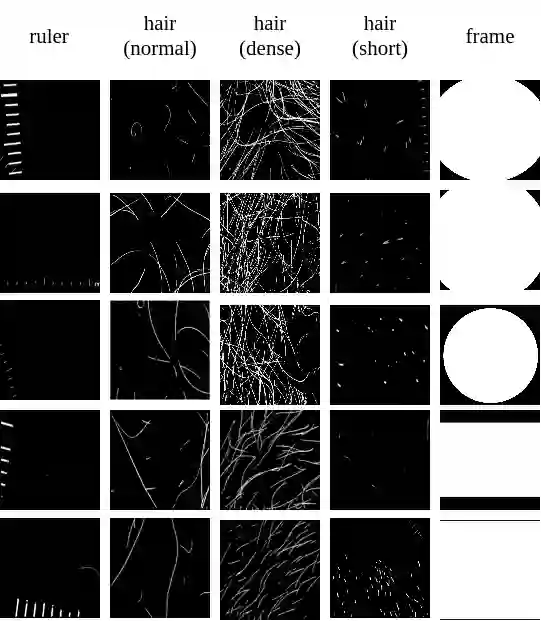
New medical datasets are now more open to the public, allowing for better and more extensive research. Although prepared with the utmost care, new datasets might still be a source of spurious correlations that affect the learning process. Moreover, data collections are usually not large enough and are often unbalanced. One approach to alleviate the data imbalance is using data augmentation with Generative Adversarial Networks (GANs) to extend the dataset with high-quality images. GANs are usually trained on the same biased datasets as the target data, resulting in more biased instances. This work explored unconditional and conditional GANs to compare their bias inheritance and how the synthetic data influenced the models. We provided extensive manual data annotation of possibly biasing artifacts on the well-known ISIC dataset with skin lesions. In addition, we examined classification models trained on both real and synthetic data with counterfactual bias explanations. Our experiments showed that GANs inherited biases and sometimes even amplified them, leading to even stronger spurious correlations. Manual data annotation and synthetic images are publicly available for reproducible scientific research.
翻译:新的医学数据集现在更向公众开放,可以进行更好、更广泛的研究。新的数据集虽然是极为谨慎地编写的,但可能仍然是影响学习过程的虚假相关关系的来源。此外,数据收集通常不够大,而且往往不平衡。缓解数据不平衡的一种方法是利用基因反versarial网络(GANs)增加数据,以高质量的图像扩大数据集。全球网络通常在与目标数据相同的偏差数据集上接受培训,从而导致更多的偏差案例。这项工作探索了无条件和有条件的GANs,以比较其偏差继承以及合成数据如何影响模型。我们提供了广泛的人工数据,说明众所周知的有皮肤损伤的ISIC数据集中可能存在的偏差文物。此外,我们用反事实偏差解释来检查了真实和合成数据培训的分类模型。我们的实验显示,GANs继承的偏差,有时甚至放大了这些模型,从而导致更强烈的虚假关联。人工数据说明和合成图像公开可供人们查阅,以便重新进行科学研究。