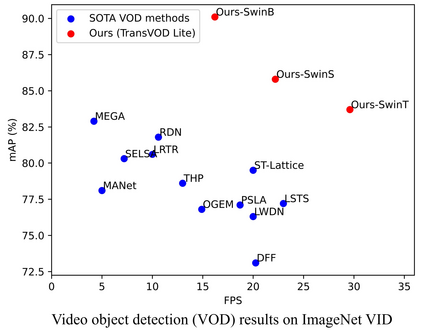
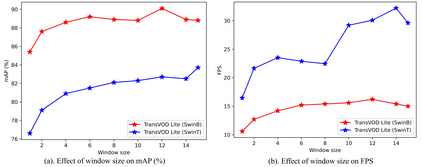
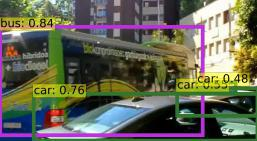
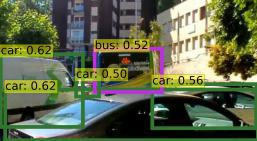
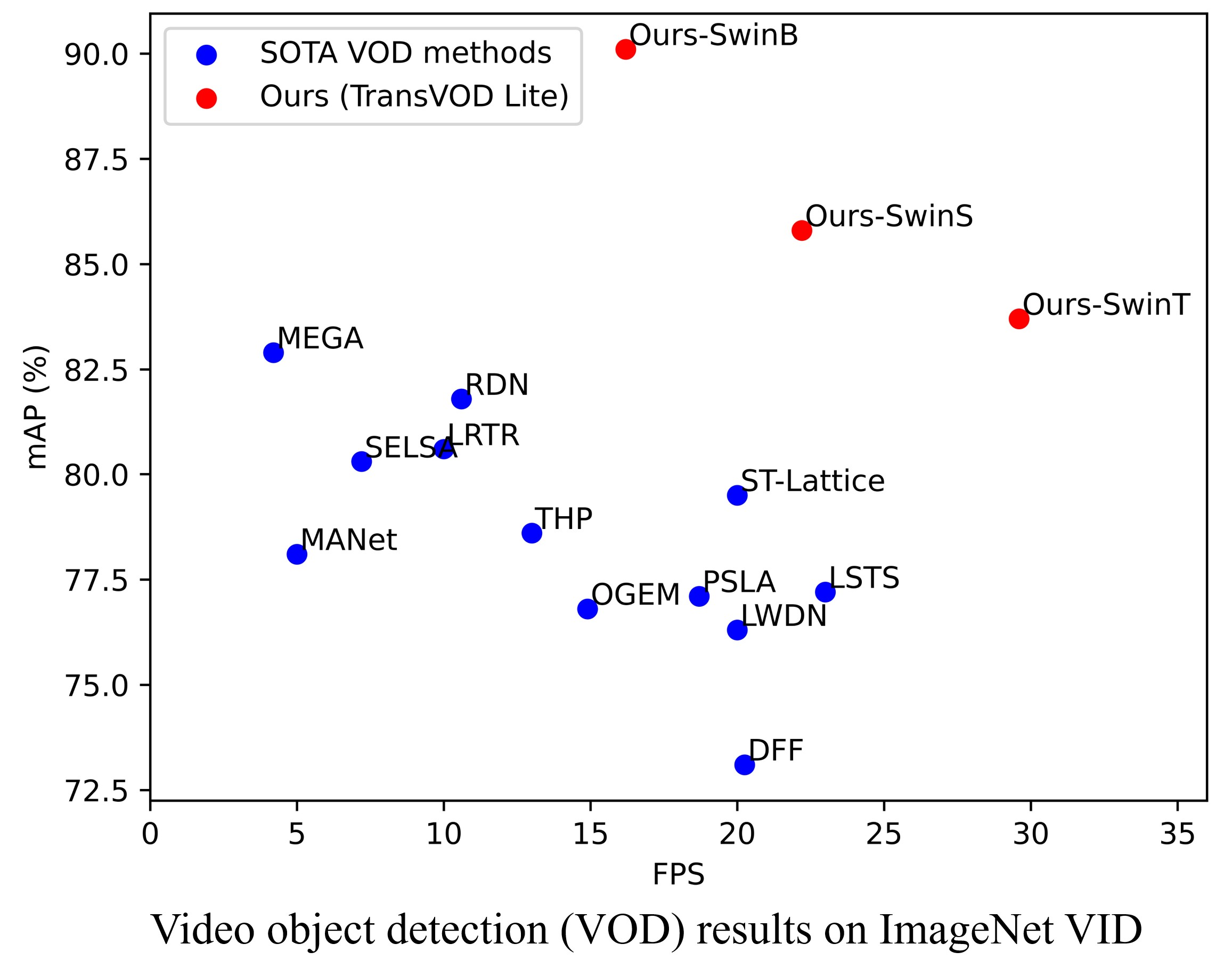
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
翻译:已经提议了检测变异器和变形变异器, 以消除在目标检测中需要许多手工设计的部件的必要性, 同时以先前复杂的手工制作的检测器显示良好的性能。 然而, 尚未很好地探索过这些部件在视频对象检测( VOD) 上的性能。 在本文中, 我们展示了基于空间时空变异器结构的首个端到端视频对象检测系统 TransVOD。 本文的第一个目标是简化 VOD的管道, 有效地消除在特性聚合中需要许多手工设计的部件的需求, 例如光学流模型、 关系网络。 此外, 我们的方法受益于 DETTR 的用户查询器设计。 我们的方法不需要复杂的后处理方法, 如 Seq- NMMS。 特别是, 我们展示了一个时间变异变异器, 以空间对象查询和每个框架的特性存储器。 我们的时间变异变异器的变异器解变器( TQEE) 将让整个变异器变异器变异器变异器(TD) 以获取当前框架检测结果的准确性变异器 。 这些方法将快速的变异器在前变异变异变变变变变变变异模型中, 我们的变变变变异模型中, 的变异性变的变变变变变变变变变变变变异性变异性变码模型的变变变的变变变变变变的变变的变码模型中, 的变的变式数据数据数据模型将的变码模型将的变数据,,, 的变式的变异性变式模型在前的变式的变变异性变变的变更变更变式模型的变换数据模型在前的变式模型中, 的变式模型中,在前的变更变更变的变的变的变的变的变的变的变式模型中,我们的变的变的变的变的变式的变更变更变式的变的变的变的变式的变更变更变更变的变的变的变的变的变的变的变式模型中,,在后的变的变更变更变的变的变的变的变的变式的变更变更变