

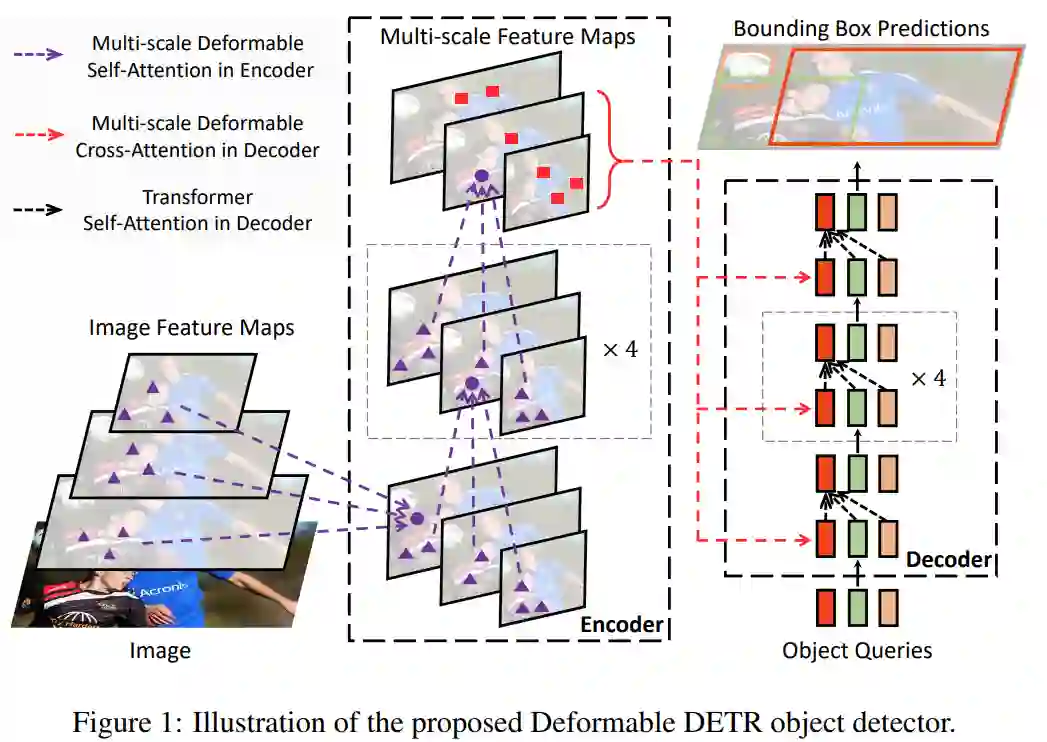
最近提出的DETR,以消除在目标检测中许多手工设计的组件的需要,同时显示良好的性能。但由于Transformer注意模块在处理图像特征图时的局限性,导致收敛速度慢,特征空间分辨率有限。为了减轻这些问题,我们提出了可变形的DETR,其注意力模块只关注参考点周围的一小组关键采样点。可变形的DETR比DETR(特别是在小物体上)可以获得更好的性能,训练周期少10个。在COCO数据集上的大量实验证明了我们的方法的有效性。
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
相关主题

相关VIP内容
相关资讯
相关论文