【论文推荐】最新十篇目标跟踪相关论文—多帧光流跟踪、动态图学习、MV-YOLO、姿态估计、深度核相关滤波、Benchmark
【导读】专知内容组整理了近期十篇目标跟踪(Object Tracking)相关文章,为大家进行介绍,欢迎查看!
1.Visual Object Tracking: The Initialisation Problem(视觉目标跟踪:初始化问题)
作者:George De Ath,Richard Everson
15th Conference on Computer and Robot Vision (CRV 2018).
机构:University of Oxford,University of Amsterdam
摘要:Model initialisation is an important component of object tracking. Tracking algorithms are generally provided with the first frame of a sequence and a bounding box (BB) indicating the location of the object. This BB may contain a large number of background pixels in addition to the object and can lead to parts-based tracking algorithms initialising their object models in background regions of the BB. In this paper, we tackle this as a missing labels problem, marking pixels sufficiently away from the BB as belonging to the background and learning the labels of the unknown pixels. Three techniques, One-Class SVM (OC-SVM), Sampled-Based Background Model (SBBM) (a novel background model based on pixel samples), and Learning Based Digital Matting (LBDM), are adapted to the problem. These are evaluated with leave-one-video-out cross-validation on the VOT2016 tracking benchmark. Our evaluation shows both OC-SVMs and SBBM are capable of providing a good level of segmentation accuracy but are too parameter-dependent to be used in real-world scenarios. We show that LBDM achieves significantly increased performance with parameters selected by cross validation and we show that it is robust to parameter variation.
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/1a2449bc3edadfae6154059bc540456c
2.Vision Meets Drones: A Challenge
作者:Pengfei Zhu,Longyin Wen,Xiao Bian,Haibin Ling,Qinghua Hu
摘要:In this paper we present a large-scale visual object detection and tracking benchmark, named VisDrone2018, aiming at advancing visual understanding tasks on the drone platform. The images and video sequences in the benchmark were captured over various urban/suburban areas of 14 different cities across China from north to south. Specifically, VisDrone2018 consists of 263 video clips and 10,209 images (no overlap with video clips) with rich annotations, including object bounding boxes, object categories, occlusion, truncation ratios, etc. With intensive amount of effort, our benchmark has more than 2.5 million annotated instances in 179,264 images/video frames. Being the largest such dataset ever published, the benchmark enables extensive evaluation and investigation of visual analysis algorithms on the drone platform. In particular, we design four popular tasks with the benchmark, including object detection in images, object detection in videos, single object tracking, and multi-object tracking. All these tasks are extremely challenging in the proposed dataset due to factors such as occlusion, large scale and pose variation, and fast motion. We hope the benchmark largely boost the research and development in visual analysis on drone platforms.

期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/8524db0b346285ea151482899d828a00
3.Fusion of Head and Full-Body Detectors for Multi-Object Tracking(基于头部和全身检测器融合的多目标跟踪)
作者:Roberto Henschel,Laura Leal-Taixé,Daniel Cremers,Bodo Rosenhahn
CVPRW 2018
机构:Leibniz Universitat Hannover,Technische Universitat M¨ unchen
摘要:In order to track all persons in a scene, the tracking-by-detection paradigm has proven to be a very effective approach. Yet, relying solely on a single detector is also a major limitation, as useful image information might be ignored. Consequently, this work demonstrates how to fuse two detectors into a tracking system. To obtain the trajectories, we propose to formulate tracking as a weighted graph labeling problem, resulting in a binary quadratic program. As such problems are NP-hard, the solution can only be approximated. Based on the Frank-Wolfe algorithm, we present a new solver that is crucial to handle such difficult problems. Evaluation on pedestrian tracking is provided for multiple scenarios, showing superior results over single detector tracking and standard QP-solvers. Finally, our tracker ranks 2nd on the MOT16 benchmark and 1st on the new MOT17 benchmark, outperforming over 90 trackers.

期刊:arXiv, 2018年4月24日
网址:
http://www.zhuanzhi.ai/document/d9e9fc8efd51c3cd4038cebeac740e82
4.Object Tracking in Satellite Videos Based on a Multi-Frame Optical Flow Tracker(基于多帧光流跟踪器的卫星视频目标跟踪)
作者:Bo Du,Shihan Cai,Chen Wu,Liangpei Zhang,Dacheng Tao
摘要:Object tracking is a hot topic in computer vision. Thanks to the booming of the very high resolution (VHR) remote sensing techniques, it is now possible to track targets of interests in satellite videos. However, since the targets in the satellite videos are usually too small compared with the entire image, and too similar with the background, most state-of-the-art algorithms failed to track the target in satellite videos with a satisfactory accuracy. Due to the fact that optical flow shows the great potential to detect even the slight movement of the targets, we proposed a multi-frame optical flow tracker (MOFT) for object tracking in satellite videos. The Lucas-Kanade optical flow method was fused with the HSV color system and integral image to track the targets in the satellite videos, while multi-frame difference method was utilized in the optical flow tracker for a better interpretation. The experiments with three VHR remote sensing satellite video datasets indicate that compared with state-of-the-art object tracking algorithms, the proposed method can track the target more accurately.
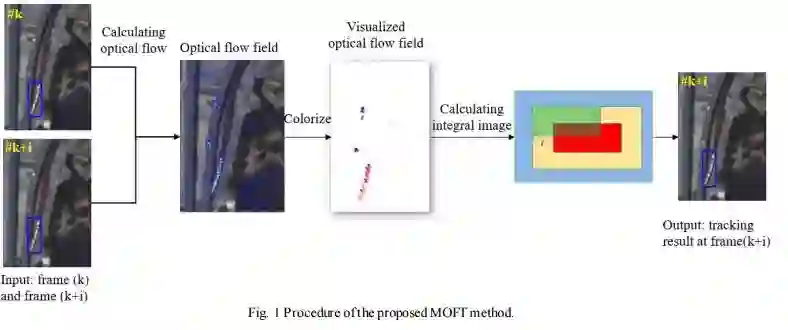
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/69336272c1b1a03c0b61c06adc9e70fc
5.Visual Tracking via Dynamic Graph Learning(动态图学习的视觉跟踪)
作者:Chenglong Li,Liang Lin,Wangmeng Zuo,Jin Tang,Ming-Hsuan Yang
Submitted to TPAMI 2017
摘要:Existing visual tracking methods usually localize a target object with a bounding box, in which the performance of the foreground object trackers or detectors is often affected by the inclusion of background clutter. To handle this problem, we learn a patch-based graph representation for visual tracking. The tracked object is modeled by with a graph by taking a set of non-overlapping image patches as nodes, in which the weight of each node indicates how likely it belongs to the foreground and edges are weighted for indicating the appearance compatibility of two neighboring nodes. This graph is dynamically learned and applied in object tracking and model updating. During the tracking process, the proposed algorithm performs three main steps in each frame. First, the graph is initialized by assigning binary weights of some image patches to indicate the object and background patches according to the predicted bounding box. Second, the graph is optimized to refine the patch weights by using a novel alternating direction method of multipliers. Third, the object feature representation is updated by imposing the weights of patches on the extracted image features. The object location is predicted by maximizing the classification score in the structured support vector machine. Extensive experiments show that the proposed tracking algorithm performs well against the state-of-the-art methods on large-scale benchmark datasets.
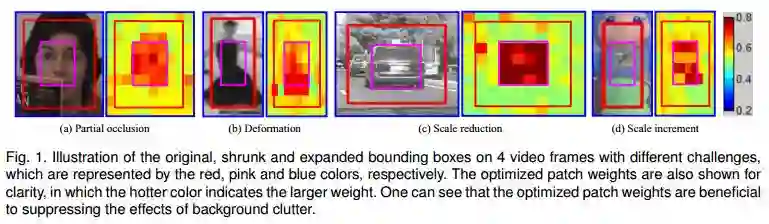
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/b2112dd0dac38071cf1b3d292a3a10e0
6.MV-YOLO: Motion Vector-aided Tracking by Semantic Object Detection(MV-YOLO: 通过语义目标检测实现运动矢量跟踪)
作者:Saeed Ranjbar Alvar,Ivan V. Bajić
机构:Simon Fraser University
摘要:Object tracking is the cornerstone of many visual analytics systems. While considerable progress has been made in this area in recent years, robust, efficient, and accurate tracking in real-world video remains a challenge. In this paper, we present a hybrid tracker that leverages motion information from the compressed video stream and a general-purpose semantic object detector acting on decoded frames to construct a fast and efficient tracking engine suitable for a number of visual analytics applications. The proposed approach is compared with several well-known recent trackers on the OTB tracking dataset. The results indicate advantages of the proposed method in terms of speed and/or accuracy. Another advantage of the proposed method over most existing trackers is its simplicity and deployment efficiency, which stems from the fact that it reuses and re-purposes the resources and information that may already exist in the system for other reasons.
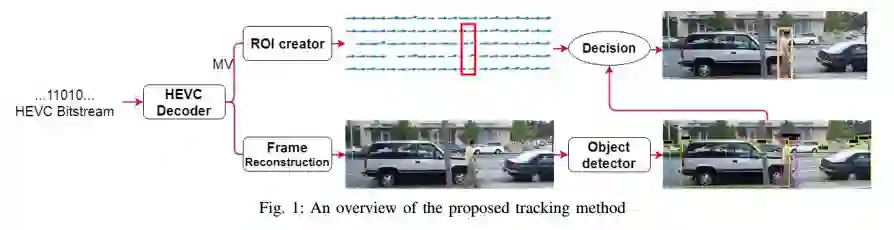
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/48d92fe7344e65d1d3c25dddbb9f28dc
7.Detect-and-Track: Efficient Pose Estimation in Videos(Detect-and-Track: 视频中的有效姿态估计)
作者:Rohit Girdhar,Georgia Gkioxari,Lorenzo Torresani,Manohar Paluri,Du Tran
CVPR 2018
机构:The Robotics Institute, Carnegie Mellon University
摘要:This paper addresses the problem of estimating and tracking human body keypoints in complex, multi-person video. We propose an extremely lightweight yet highly effective approach that builds upon the latest advancements in human detection and video understanding. Our method operates in two-stages: keypoint estimation in frames or short clips, followed by lightweight tracking to generate keypoint predictions linked over the entire video. For frame-level pose estimation we experiment with Mask R-CNN, as well as our own proposed 3D extension of this model, which leverages temporal information over small clips to generate more robust frame predictions. We conduct extensive ablative experiments on the newly released multi-person video pose estimation benchmark, PoseTrack, to validate various design choices of our model. Our approach achieves an accuracy of 55.2% on the validation and 51.8% on the test set using the Multi-Object Tracking Accuracy (MOTA) metric, and achieves state of the art performance on the ICCV 2017 PoseTrack keypoint tracking challenge.
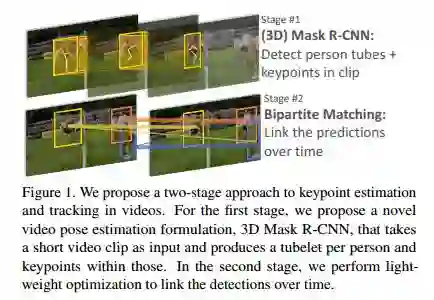
期刊:arXiv, 2018年5月3日
网址:
http://www.zhuanzhi.ai/document/257f199c37cd0b7136fa05ae29085710
8.Tracking in Aerial Hyperspectral Videos using Deep Kernelized Correlation Filters(深度核相关滤波在航空高光谱视频跟踪中的应用)
作者:Burak Uzkent,Aneesh Rangnekar,Matthew J. Hoffman
机构:School of Mathematical Sciences
摘要:Hyperspectral imaging holds enormous potential to improve the state-of-the-art in aerial vehicle tracking with low spatial and temporal resolutions. Recently, adaptive multi-modal hyperspectral sensors have attracted growing interest due to their ability to record extended data quickly from aerial platforms. In this study, we apply popular concepts from traditional object tracking, namely (1) Kernelized Correlation Filters (KCF) and (2) Deep Convolutional Neural Network (CNN) features to aerial tracking in hyperspectral domain. We propose the Deep Hyperspectral Kernelized Correlation Filter based tracker (DeepHKCF) to efficiently track aerial vehicles using an adaptive multi-modal hyperspectral sensor. We address low temporal resolution by designing a single KCF-in-multiple Regions-of-Interest (ROIs) approach to cover a reasonably large area. To increase the speed of deep convolutional features extraction from multiple ROIs, we design an effective ROI mapping strategy. The proposed tracker also provides flexibility to couple with the more advanced correlation filter trackers. The DeepHKCF tracker performs exceptionally well with deep features set up in a synthetic hyperspectral video generated by the Digital Imaging and Remote Sensing Image Generation (DIRSIG) software. Additionally, we generate a large, synthetic, single-channel dataset using DIRSIG to perform vehicle classification in the Wide Area Motion Imagery (WAMI) platform. This way, the high-fidelity of the DIRSIG software is proved and a large scale aerial vehicle classification dataset is released to support studies on vehicle detection and tracking in the WAMI platform.
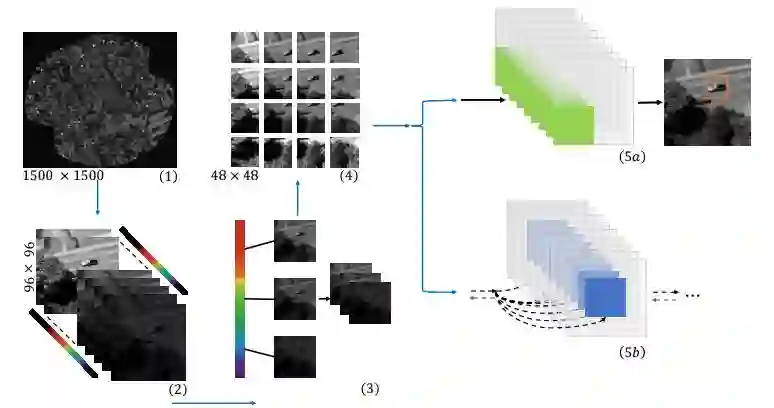
期刊:arXiv, 2018年5月6日
网址:
http://www.zhuanzhi.ai/document/c533150b67b0636ff9ba1d32339e85f9
9.Measurement-wise Occlusion in Multi-object Tracking
作者:Michael Motro,Joydeep Ghosh
21st International Conference on Information Fusion, 2018
机构:University of Texas at Austin
摘要:Handling object interaction is a fundamental challenge in practical multi-object tracking, even for simple interactive effects such as one object temporarily occluding another. We formalize the problem of occlusion in tracking with two different abstractions. In object-wise occlusion, objects that are occluded by other objects do not generate measurements. In measurement-wise occlusion, a previously unstudied approach, all objects may generate measurements but some measurements may be occluded by others. While the relative validity of each abstraction depends on the situation and sensor, measurement-wise occlusion fits into probabilistic multi-object tracking algorithms with much looser assumptions on object interaction. Its value is demonstrated by showing that it naturally derives a popular approximation for lidar tracking, and by an example of visual tracking in image space.
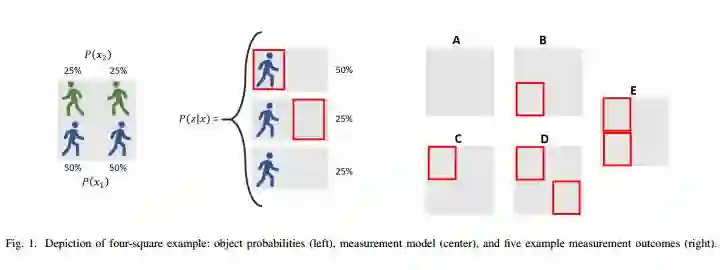
期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/d984b54ff9c9815766f0e1e9a7681082
10.Planar Object Tracking in the Wild: A Benchmark(在自然场景的平面目标跟踪:一个Benchmark)
作者:Pengpeng Liang,Yifan Wu,Hu Lu,Liming Wang,Chunyuan Liao,Haibin Ling
Accepted by ICRA 2018
摘要:Planar object tracking is an actively studied problem in vision-based robotic applications. While several benchmarks have been constructed for evaluating state-of-the-art algorithms, there is a lack of video sequences captured in the wild rather than in constrained laboratory environment. In this paper, we present a carefully designed planar object tracking benchmark containing 210 videos of 30 planar objects sampled in the natural environment. In particular, for each object, we shoot seven videos involving various challenging factors, namely scale change, rotation, perspective distortion, motion blur, occlusion, out-of-view, and unconstrained. The ground truth is carefully annotated semi-manually to ensure the quality. Moreover, eleven state-of-the-art algorithms are evaluated on the benchmark using two evaluation metrics, with detailed analysis provided for the evaluation results. We expect the proposed benchmark to benefit future studies on planar object tracking.

期刊:arXiv, 2018年5月22日
网址:
http://www.zhuanzhi.ai/document/63ab1559ac66e9af9c6b5e9ef524b663
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


