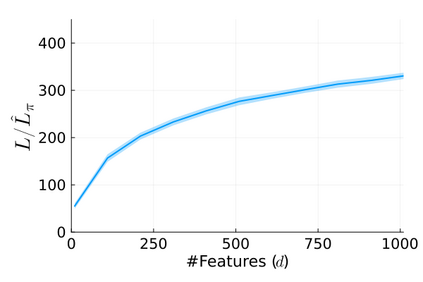
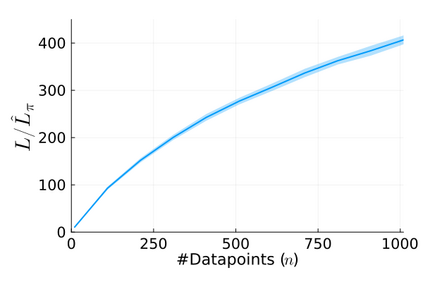
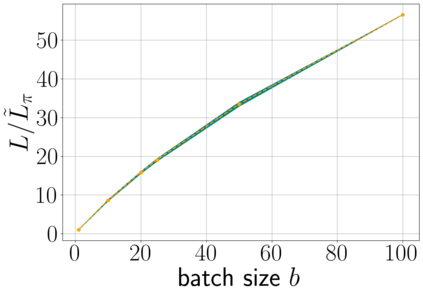
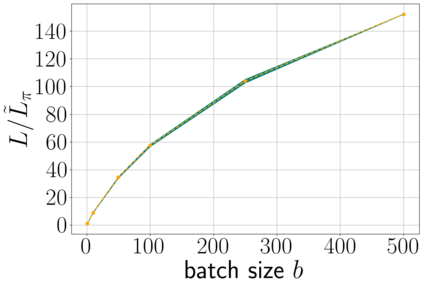
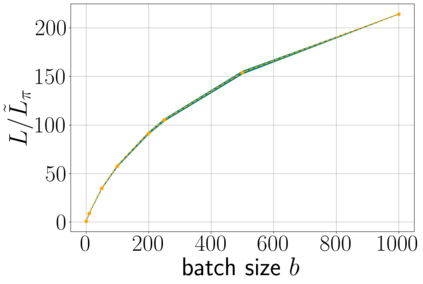
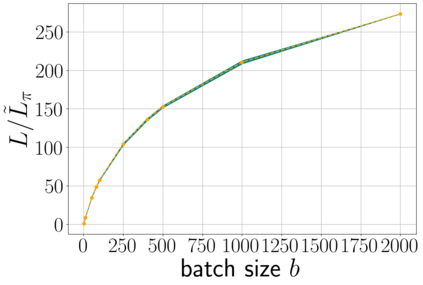
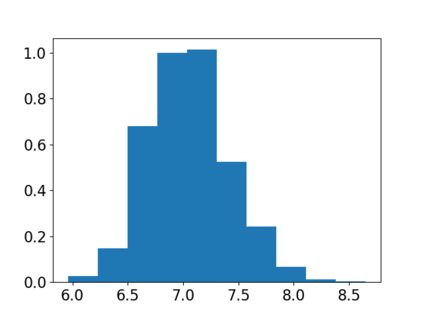
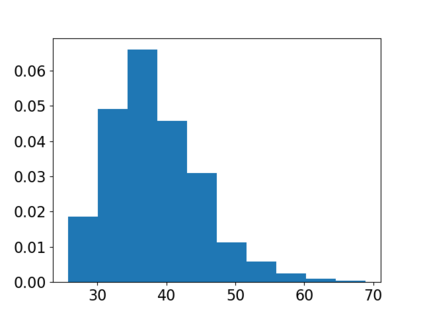
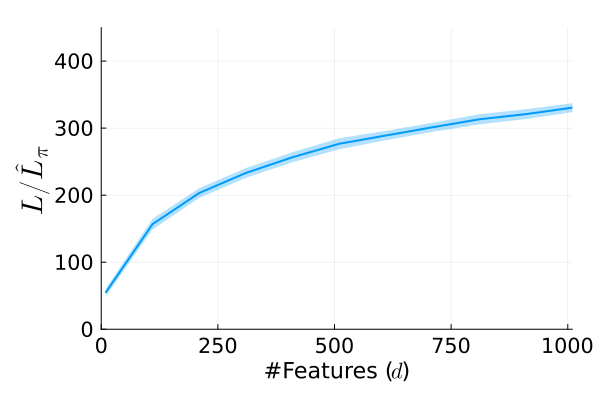
Stochastic gradient descent (SGD) is perhaps the most prevalent optimization method in modern machine learning. Contrary to the empirical practice of sampling from the datasets without replacement and with (possible) reshuffling at each epoch, the theoretical counterpart of SGD usually relies on the assumption of sampling with replacement. It is only very recently that SGD with sampling without replacement -- shuffled SGD -- has been analyzed. For convex finite sum problems with $n$ components and under the $L$-smoothness assumption for each component function, there are matching upper and lower bounds, under sufficiently small -- $\mathcal{O}(\frac{1}{nL})$ -- step sizes. Yet those bounds appear too pessimistic -- in fact, the predicted performance is generally no better than for full gradient descent -- and do not agree with the empirical observations. In this work, to narrow the gap between the theory and practice of shuffled SGD, we sharpen the focus from general finite sum problems to empirical risk minimization with linear predictors. This allows us to take a primal-dual perspective and interpret shuffled SGD as a primal-dual method with cyclic coordinate updates on the dual side. Leveraging this perspective, we prove fine-grained complexity bounds that depend on the data matrix and are never worse than what is predicted by the existing bounds. Notably, our bounds predict much faster convergence than the existing analyses -- by a factor of the order of $\sqrt{n}$ in some cases. We empirically demonstrate that on common machine learning datasets our bounds are indeed much tighter. We further extend our analysis to nonsmooth convex problems and more general finite-sum problems, with similar improvements.
翻译:暂无翻译